

Техническая реализация коммутаторов. Управление потоком данных при полудуплексной и полнодуплексной работе
В настоящее время коммутаторы используют в качестве базовой одну из трех схем, на которой строится такой узел обмена:
коммутационная матрица;
разделяемая многовходовая память;
общая шина.
Коммутаторы на основе коммутационной матрицы. Коммутационная матрица обеспечивает основной и самый быстрый способ взаимодействия процессоров портов, именно он был реализован в первом промышленном коммутаторе локальных сетей. Однако реализация матрицы возможна только для определенного числа портов, причем сложность схемы возрастает пропорционально квадрату количества портов коммутатора (рис. 2.76).

Рис. 2.76 – Коммутационная матрица
Более детальное представление одного из возможных вариантов реализации коммутационной матрицы для 8 портов дано на рис. 2.77. Входные блоки процессоров портов на основании просмотра адресной таблицы коммутатора определяют по адресу назначения номер выходного порта. Эту информацию они добавляют к байтам исходного кадра в виде специального ярлыка – тэга (tag). Для данного примера тэг представляет собой просто 3-разрядное двоичное число, соответствующее номеру выходного порта.

Рис. 2.77 – Реализация коммутационной матрицы 8х8 с помощью двоичных переключателей
Матрица состоит из трех уровней двоичных переключателей, которые соединяют свой вход с одним из двух выходов в зависимости от значения бита тэга. Переключатели первого уровня управляются первым битом тэга, второго – вторым, а третьего – третьим.
Матрица может быть реализована и по-другому, на основании комбинационных схем другого типа, но ее особенностью все равно остается технология коммутации физических каналов. Известным недостатком этой технологии является отсутствие буферизации данных внутри коммутационной матрицы – если составной канал невозможно построить из-за занятости выходного порта или промежуточного коммутационного элемента, то данные должны накапливаться в их источнике, в данном случае – во входном блоке порта, принявшего кадр. Основные достоинства таких матриц - высокая скорость коммутации и регулярная структура, которую удобно реализовывать в интегральных микросхемах. Зато после реализации матрицы NxN в составе БИС проявляется еще один ее недостаток – сложность наращивания числа коммутируемых портов.
Коммутаторы с общей шиной. В коммутаторах с общей шиной процессоры портов связывают высокоскоростной шиной, используемой в режиме разделения времени.
Пример такой архитектуры приведен на рис. 2.78. Чтобы шина не блокировала работу коммутатора, ее производительность должна равняться, по крайней мере, сумме производительности всех портов коммутатора. Для модульных коммутаторов некоторые сочетания модулей с низкоскоростными портами могут приводить к неблокирующей работе, а установка модулей с высокоскоростными портами может приводить к тому, что блокирующим элементом станет, например, общая шина.

Рис. 2.78 – Архитектура коммутатора с общей шиной
Кадр должен передаваться по шине небольшими частями, по нескольку байт, чтобы передача кадров между несколькими портами происходила в псевдопараллельном режиме, не внося задержек в передачу кадра в целом. Размер такой ячейки данных определяется производителем коммутатора. Некоторые производители, например LANNET или Centillion, выбрали в качестве порции данных, переносимых за одну операцию по шине, ячейку АТМ с ее полем данных в 48 байт. Такой подход облегчает трансляцию протоколов локальных сетей в протокол АТМ, если коммутатор поддерживает эти технологии.
Входной блок процессора помещает в ячейку, переносимую по шине, тэг, в котором указывает номер порта назначения. Каждый выходной блок процессора порта содержит фильтр тэгов, который выбирает тэги, предназначенные данному порту.
Шина, так же как и коммутационная матрица, не может осуществлять промежуточную буферизацию, но так как данные кадра разбиваются на небольшие ячейки, то задержек с начальным ожиданием доступности выходного порта в такой схеме нет – здесь работает принцип коммутации пакетов, а не каналов.
Коммутаторы с разделяемой памятью. Третья базовая архитектура взаимодействия портов – двухвходовая разделяемая память. Пример такой архитектуры приведен на рис. 2.79.

Рис. 2.79 – Архитектура разделяемой памяти
Входные блоки процессоров портов соединяются с переключаемым входом разделяемой памяти, а выходные блоки этих же процессоров соединяются с переключаемым выходом этой памяти. Переключением входа и выхода разделяемой памяти управляет менеджер очередей выходных портов. В разделяемой памяти менеджер организует несколько очередей данных, по одной для каждого выходного порта. Входные блоки процессоров передают менеджеру портов запросы на запись данных в очередь того порта, который соответствует адресу назначения пакета. Менеджер по очереди подключает вход памяти к одному из входных блоков процессоров и тот переписывает часть данных кадра в очередь определенного выходного порта. По мере заполнения очередей менеджер производит также поочередное подключение выхода разделяемой памяти к выходным блокам процессоров портов, и данные из очереди переписываются в выходной буфер процессора.
Память должна быть достаточно быстродействующей для поддержания скорости переписи данных между N портами коммутатора. Применение общей буферной памяти, гибко распределяемой менеджером между отдельными портами, снижает требования к размеру буферной памяти процессора порта.
Управление потоком данных при полнодуплексной работе. Простой отказ от поддержки алгоритма доступа к разделяемой среде без какой-либо модификации протокола ведет к повышению вероятности потерь кадров коммутаторами, так как при этом теряется контроль за потоками кадров, направляемых конечными узлами в сеть. Раньше поток кадров регулировался методом доступа к разделяемой среде, так что слишком часто генерирующий кадры узел вынужден был ждать своей очереди к среде и фактическая интенсивность потока данных, который направлял в сеть этот узел, была заметно меньше той интенсивности, которую узел хотел бы отправить в сеть. При переходе на полнодуплексный режим узлу разрешается отправлять кадры в коммутатор всегда, когда это ему нужно, поэтому коммутаторы сети могут в этом режиме сталкиваться с перегрузками, не имея при этом никаких средств регулирования потока кадров.
Поэтому, если входной трафик неравномерно распределяется между выходными портами, легко представить ситуацию, когда в какой-либо выходной порт коммутатора будет направляться трафик с суммарной средней интенсивностью большей, чем протокольный максимум. На рис. 2.74 изображена как раз такая ситуация, когда в порт 3 коммутатора направляется трафик от портов 1,2,4 и 6, с суммарной интенсивностью в 22 100 кадров в секунду. Порт 3 оказывается загружен на 150 %, Естественно, что когда кадры поступают в буфер порта со скоростью 20 100 кадров в секунду, а уходят со скоростью 14 880 кадров в секунду, то внутренний буфер выходного порта начинает неуклонно заполняться необработанными кадрами.

Рис. 2.74 – Переполнение буфера порта из-за несбалансированности трафика
Какой бы ни был объем буфера порта, он в какой-то момент времени обязательно переполнится. Нетрудно подсчитать, что при размере буфера в 100 Кбайт в приведенном примере полное заполнение буфера произойдет через 0,22 секунды после начала его работы (буфер такого размера может хранить до 1600 кадров размером в 64 байт). Увеличение буфера до 1 Мбайт даст увеличение времени заполнения буфера до 2,2 секунд, что также неприемлемо. А потери кадров всегда очень нежелательны, так как снижают полезную производительность сети, и коммутатор, теряющий кадры, может значительно ухудшить производительность сети вместо ее улучшения.
В глобальных сетях коммутаторы технологии Х.25 поддерживают протокол канального уровня LAP-В, который имеет специальные кадры управления потоком «Приемник готов» (RR) и «Приемник не готов» (RNR). Протокол LAP-B работает между соседними коммутаторами сети Х.25 и в том случае, когда очередь коммутатора доходит до опасной границы, запрещает своим ближайшим соседям с помощью кадра «Приемник не готов» передавать ему кадры, пока очередь не уменьшится до нормального уровня. В сетях Х.25 такой протокол необходим, так как эти сети никогда не использовали разделяемые среды передачи данных, а работали по индивидуальным каналам связи в полнодуплексном режиме.
При разработке коммутаторов локальных сетей ситуация коренным образом отличалась от ситуации, при которой создавались коммутаторы территориальных сетей. Основной задачей было сохранение конечных узлов в неизменном виде, что исключало корректировку протоколов локальных сетей. А в этих протоколах процедур управления потоком не было – общая среда передачи данных в режиме разделения времени исключала возникновение ситуаций, когда сеть переполнялась бы необработанными кадрами. Сеть не накапливала данных в каких-либо промежуточных буферах при использовании только повторителей или концентраторов.
В марте 1997 года принят стандарт IEEE 802.3x на управление потоком в полнодуплексных версиях протокола Ethernet. Он определяет весьма простую процедуру управления потоком, подобную той, которая используется в протоколах LLC2 и LAP-B. Эта процедура подразумевает две команды – «Приостановить передачу» и «Возобновить передачу», которые направляются соседнему узлу. Отличие от протоколов типа LLC2 в том, что эти команды реализуются на уровне символов кодов физического уровня, таких как 4В/5В, а не на уровне команд, оформленных в специальные управляющие кадры. Сетевой адаптер или порт коммутатора, поддерживающий стандарт 802.3x и получивший команду «Приостановить передачу», должен прекратить передавать кадры впредь до получения команды «Возобновить передачу».
Управление потоком кадров при полудуплексной работе. При работе порта в полудуплексном режиме коммутатор не может изменять протокол и пользоваться для управления потоком новыми командами, такими как «Приостановить передачу» и «Возобновить передачу». Зато у коммутатора появляется возможность воздействовать на конечный узел с помощью механизмов алгоритма доступа к среде, который конечный узел обязан отрабатывать. Эти приемы основаны на том, что конечные узлы строго соблюдают все параметры алгоритма доступа к среде, а порты коммутатора - нет. Обычно применяются два основных способа управления потоком кадров - обратное давление на конечный узел и агрессивный захват среды.
Метод обратного давления (backpressure) состоит в создании искусственных коллизий в сегменте, который чересчур интенсивно посылает кадры в коммутатор. Для этого коммутатор обычно использует jam-последовательность, отправляемую на выход порта, к которому подключен сегмент (или узел), чтобы приостановить его активность. Кроме того, метод обратного давления может применяться в тех случаях, когда процессор порта не рассчитан на поддержку максимально возможного для данного протокола трафика.
Второй метод «торможения» конечного узла в условиях перегрузки внутренних буферов коммутатора основан на так называемом агрессивном поведении порта коммутатора при захвате среды либо после окончания передачи очередного пакета, либо после коллизии. Эти два случая иллюстрируются рис. 2.75, а и б.

Рис. 2.75 – Агрессивное поведение коммутатора при перегрузках буферов
В первом случае коммутатор окончил передачу очередного кадра и вместо технологической паузы в 9,6 мкс сделал паузу в 9,1 мкс и начал передачу нового кадра. Компьютер не смог захватить среду, так как он выдержал стандартную паузу в 9,6 мкс и обнаружил после этого, что среда уже занята.
Во втором случае кадры коммутатора и компьютера столкнулись, и была зафиксирована коллизия. Так как компьютер сделал паузу после коллизии в 51,2 мкс, как это положено по стандарту (интервал отсрочки равен 512 битовых интервалов), а коммутатор - 50 мкс, то и в этом случае компьютеру не удалось передать свой кадр.
Коммутатор может пользоваться этим механизмом адаптивно, увеличивая степень своей агрессивности по мере необходимости.
Многие производители реализуют с помощью сочетания описанных двух методов достаточно тонкие механизмы управления потоком кадров при перегрузках. Эти методы используют алгоритмы чередования передаваемых и принимаемых кадров (frame interleave). Алгоритм чередования должен быть гибким и позволять компьютеру в критических ситуациях на каждый принимаемый кадр передавать несколько своих, разгружая внутренний буфер кадров, причем, не обязательно снижая при этом интенсивность приема кадров до нуля, а просто уменьшая ее до необходимого уровня.
Организация сетей Token-Ring и FDDI. Спецификация физической среды
Сети Token Ring, так же как и сети Ethernet, характеризует разделяемая среда передачи данных, которая в данном случае состоит из отрезков кабеля, соединяющих все станции сети в кольцо. Кольцо рассматривается как общий разделяемый ресурс, и для доступа к нему требуется не случайный алгоритм, как в сетях Ethernet, а детерминированный, основанный на передаче станциям права на использование кольца в определенном порядке. Это право передается с помощью кадра специального формата, называемого маркером или токеном (token).
Технология Token Ring был разработана компанией IBM в 1984 году, а затем передана в качестве проекта стандарта в комитет IEEE 802, который на ее основе принял в 1985 году стандарт 802.5. Компания IBM использует технологию Token Ring в качестве своей основной сетевой технологии для построения локальных сетей на основе компьютеров различных классов – мэйнфреймов, мини-компьютеров и персональных компьютеров. В настоящее время именно компания IBM является основным законодателем моды технологии Token Ring, производя около 60 % сетевых адаптеров этой технологии.
Сети Token Ring работают с двумя битовыми скоростями – 4 и 16 Мбит/с. Смешение станций, работающих на различных скоростях, в одном кольце не допускается. Сети Token Ring, работающие со скоростью 16 Мбит/с, имеют некоторые усовершенствования в алгоритме доступа по сравнению со стандартом 4 Мбит/с.
Технология Token Ring является более сложной технологией, чем Ethernet. Она обладает свойствами отказоустойчивости. В сети Token Ring определены процедуры контроля работы сети, которые используют обратную связь кольцеобразной структуры - посланный кадр всегда возвращается в станцию – отправитель. В некоторых случаях обнаруженные ошибки в работе сети устраняются автоматически, например, может быть восстановлен потерянный маркер. В других случаях ошибки только фиксируются, а их устранение выполняется вручную обслуживающим персоналом.
Для контроля сети одна из станций выполняет роль, так называемого, активного монитора. Активный монитор выбирается во время инициализации кольца как станция с максимальным значением МАС-адреса, Если активный монитор выходит из строя, процедура инициализации кольца повторяется и выбирается новый активный монитор. Чтобы сеть могла обнаружить отказ активного монитора, последний в работоспособном состоянии каждые 3 секунды генерирует специальный кадр своего присутствия. Если этот кадр не появляется в сети более 7 секунд, то остальные станции сети начинают процедуру выборов нового активного монитора.
Маркерный метод доступа к разделяемой среде.
В сетях с маркерным методом доступа (а к ним, кроме сетей Token Ring, относятся сети FDDI, а также сети, близкие к стандарту 802.4, – ArcNet, сети производственного назначения MAP) право на доступ к среде передается циклически от станции к станции по логическому кольцу.
В сети Token Ring кольцо образуется отрезками кабеля, соединяющими соседние станции. Таким образом, каждая станция связана со своей предшествующей и последующей станцией и может непосредственно обмениваться данными только с ними. Для обеспечения доступа станций к физической среде по кольцу циркулирует кадр специального формата и назначения - маркер. В сети Token Ring любая станция всегда непосредственно получает данные только от одной станции – той, которая является предыдущей в кольце. Такая станция называется ближайшим активным соседом, расположенным выше по потоку (данных) – Nearest Active Upstream Neighbor, NAUN. Передачу же данных станция всегда осуществляет своему ближайшему соседу вниз по потоку данных.
Получив маркер, станция анализирует его и при отсутствии у нее данных для передачи обеспечивает его продвижение к следующей станции. Станция, которая имеет данные для передачи, при получении маркера изымает его из кольца, что дает ей право доступа к физической среде и передачи своих данных. Затем эта станция выдает в кольцо кадр данных установленного формата последовательно по битам. Переданные данные проходят по кольцу всегда в одном направлении от одной станции к другой. Кадр снабжен адресом назначения и адресом источника.
Все станции кольца ретранслируют кадр побитно, как повторители. Если кадр проходит через станцию назначения, то, распознав свой адрес, эта станция копирует кадр в свой внутренний буфер и вставляет в кадр признак подтверждения приема. Станция, выдавшая кадр данных в кольцо, при обратном его получении с подтверждением приема изымает этот кадр из кольца и передает в сеть новый маркер для обеспечения возможности другим станциям сети передавать данные. Такой алгоритм доступа применяется в сетях Token Ring со скоростью работы 4 Мбит/с, описанных в стандарте 802.5.
На рис. 3.13 описанный алгоритм доступа к среде иллюстрируется временной диаграммой. Здесь показана передача пакета А в кольце, состоящем из 6 станций, от станции 1 к станции 3. После прохождения станции назначения 3 в пакете А устанавливаются два признака - признак распознавания адреса и признак копирования пакета в буфер (что на рисунке отмечено звездочкой внутри пакета). После возвращения пакета в станцию 1 отправитель распознает свой пакет по адресу источника и удаляет пакет из кольца. Установленные станцией 3 признаки говорят станции-отправителю о том, что пакет дошел до адресата и был успешно скопирован им в свой буфер.

Рис. 3.13 – Принцип маркерного доступа
Время владения разделяемой средой в сети Token Ring ограничивается временем удержания маркера (token holding time), после истечения, которого станция обязана прекратить передачу собственных данных (текущий кадр разрешается завершить) и передать маркер далее по кольцу. Станция может успеть передать за время удержания маркера один или несколько кадров в зависимости от размера кадров и величины времени удержания маркера. Обычно время удержания маркера по умолчанию равно 10 мс, а максимальный размер кадра в стандарте 802.5 не определен. Для сетей 4 Мбит/с он обычно равен 4 Кбайт, а для сетей 16 Мбит/с – 16 Кбайт. Это связано с тем, что за время удержания маркера станция должна успеть передать хотя бы один кадр. При скорости 4 Мбит/с за время 10 мс можно передать 5000 байт, а при скорости 16 Мбит/с - соответственно 20 000 байт. Максимальные размеры кадра выбраны с некоторым запасом.
В сетях Token Ring 16 Мбит/с используется также несколько другой алгоритм доступа к кольцу, называемый алгоритмом раннего освобождения маркера (Early Token Release). В соответствии с ним станция передает маркер доступа следующей станции сразу же после окончания передачи последнего бита кадра, не дожидаясь возвращения по кольцу этого кадра с битом подтверждения приема. В этом случае пропускная способность кольца используется более эффективно, так как по кольцу одновременно продвигаются кадры нескольких станций. Тем не менее свои кадры в каждый момент времени может генерировать только одна станция - та, которая в данный момент владеет маркером доступа. Остальные станции в это время только повторяют чужие кадры, так что принцип разделения кольца во времени сохраняется, ускоряется только процедура передачи владения кольцом.
Для различных видов сообщений, передаваемым кадрам, могут назначаться различные приоритеты: от 0 (низший) до 7 (высший). Решение о приоритете конкретного кадра принимает передающая станция (протокол Token Ring получает этот параметр через межуровневые интерфейсы от протоколов верхнего уровня, например прикладного). Маркер также всегда имеет некоторый уровень текущего приоритета. Станция имеет право захватить переданный ей маркер только в том случае, если приоритет кадра, который она хочет передать, выше (или равен) приоритета маркера. В противном случае станция обязана передать маркер следующей по кольцу станции.
За наличие в сети маркера, причем единственной его копии, отвечает активный монитор. Если активный монитор не получает маркер в течение длительного времени (например, 2,6 с), то он порождает новый маркер.
Физический уровень технологии Token Ring. Стандарт Token Ring фирмы IBM изначально предусматривал построение связей в сети с помощью концентраторов, называемых MAU (Multistation Access Unit) или MSAU (Multi-Station Access Unit), то есть устройствами многостанционного доступа (рис. 3.14). Сеть Token Ring может включать до 260 узлов.

Рис. 3.14 – Физическая конфигурация сети Token Ring
Концентратор Token Ring может быть активным или пассивным. Пассивный концентратор просто соединяет порты внутренними связями так, чтобы станции, подключаемые к этим портам, образовали кольцо. Ни усиление сигналов, ни их ресинхронизацию пассивный MSAU не выполняет. Такое устройство можно считать простым кроссовым блоком за одним исключением – MSAU обеспечивает обход какого-либо порта, когда присоединенный к этому порту компьютер выключают. Такая функция необходима для обеспечения связности кольца вне зависимости от состояния подключенных компьютеров. Обычно обход порта выполняется за счет релейных схем, которые питаются постоянным током от сетевого адаптера, а при выключении сетевого адаптера нормально замкнутые контакты реле соединяют вход порта с его выходом.
Активный концентратор выполняет функции регенерации сигналов и поэтому иногда называется повторителем, как в стандарте Ethernet.
Возникает вопрос - если концентратор является пассивным устройством, то каким образом обеспечивается качественная передача сигналов на большие расстояния, которые возникают при включении в сеть нескольких сот компьютеров? Ответ состоит в том, что роль усилителя сигналов в этом случае берет на себя каждый сетевой адаптер, а роль ресинхронизирующего блока выполняет сетевой адаптер активного монитора кольца. Каждый сетевой адаптер Token Ring имеет блок повторения, который умеет регенерировать и ресинхронизировать сигналы, однако последнюю функцию выполняет в кольце только блок повторения активного монитора.
Блок ресинхронизации состоит из 30-битного буфера, который принимает манчестерские сигналы с несколько искаженными за время оборота по кольцу интервалами следования. При максимальном количестве станций в кольце (260) вариация задержки циркуляции бита по кольцу может достигать 3-битовых интервалов. Активный монитор «вставляет» свой буфер в кольцо и синхронизирует битовые сигналы, выдавая их на выход с требуемой частотой.
В общем случае сеть Token Ring имеет комбинированную звездно-кольцевую конфигурацию. Конечные узлы подключаются к MSAU по топологии звезды, а сами MSAU объединяются через специальные порты Ring In (RI) и Ring Out (RO) для образования магистрального физического кольца.
Все станции в кольце должны работать на одной скорости - либо 4 Мбит/с, либо 16 Мбит/с. Кабели, соединяющие станцию с концентратором, называются ответвительными (lobe cable), а кабели, соединяющие концентраторы, - магистральными (trunk cable).
Технология Token Ring позволяет использовать для соединения конечных станций и концентраторов различные типы кабеля: STP Type I, UTP Type 3, UTP Type 6, а также волоконно-оптический кабель.
При использовании экранированной витой пары STP Type 1 из номенклатуры кабельной системы IBM в кольцо допускается объединять до 260 станций при длине ответвительных кабелей до 100 метров, а при использовании неэкранированной витой пары максимальное количество станций сокращается до 72 при длине ответвительных кабелей до 45 метров.
Расстояние между пассивными MSAU может достигать 100 м при использовании кабеля STP Type 1 и 45 м при использовании кабеля UTP Type 3. Между активными MSAU максимальное расстояние увеличивается соответственно до 730 м или 365 м в зависимости от типа кабеля.
Максимальная длина кольца Token Ring составляет 4000 м. Ограничения на максимальную длину кольца и количество станций в кольце в технологии Token Ring не являются такими жесткими, как в технологии Ethernet. Здесь эти ограничения во многом связаны со временем оборота маркера по кольцу (но не только -есть и другие соображения, диктующие выбор ограничений). Так, если кольцо состоит из 260 станций, то при времени удержания маркера в 10 мс маркер вернется в активный монитор в худшем случае через 2,6 с, а это время как раз составляет тайм-аут контроля оборота маркера. В принципе, все значения тайм-аутов в сетевых адаптерах узлов сети Token Ring можно настраивать, поэтому можно построить сеть Token Ring с большим количеством станций и с большей длиной кольца.
Технология FDDI. Технология FDDI (Fiber Distributed Data Interface) – оптоволоконный интерфейс распределенных данных – это первая технология локальных сетей, в которой средой передачи данных является волоконно-оптический кабель. Работы по созданию технологий и устройств для использования волоконно-оптических каналов в локальных сетях начались в 80-е годы, вскоре после начала промышленной эксплуатации подобных каналов в территориальных сетях. Проблемная группа ХЗТ9.5 института ANSI разработала в период с 1986 по 1988 гг. начальные версии стандарта FDDI, который обеспечивает передачу кадров со скоростью 100 Мбит/с по двойному волоконно-оптическому кольцу длиной до 100 км.
Основные характеристики технологии
Технология FDDI во многом основывается на технологии Token Ring, развивая и совершенствуя ее основные идеи. Разработчики технологии FDDI ставили перед собой в качестве наиболее приоритетных следующие цели:
повысить битовую скорость передачи данных до 100 Мбит/с;
повысить отказоустойчивость сети за счет стандартных процедур восстановления ее после отказов различного рода – повреждения кабеля, некорректной работы узла, концентратора, возникновения высокого уровня помех на линии и т. п.;
максимально эффективно использовать потенциальную пропускную способность сети как для асинхронного, так и для синхронного (чувствительного к задержкам) трафиков.
Сеть FDDI строится на основе двух оптоволоконных колец, которые образуют основной и резервный пути передачи данных между узлами сети. Наличие двух колец - это основной способ повышения отказоустойчивости в сети FDDI, и узлы, которые хотят воспользоваться этим повышенным потенциалом надежности, должны быть подключены к обоим кольцам.
В нормальном режиме работы сети данные проходят через все узлы и все участки кабеля только первичного (Primary) кольца, этот режим назван режимом Thru – «сквозным» или «транзитным». Вторичное кольцо (Secondary) в этом режиме не используется.
В случае какого-либо вида отказа, когда часть первичного кольца не может передавать данные (например, обрыв кабеля или отказ узла), первичное кольцо объединяется со вторичным (рис. 2.42), вновь образуя единое кольцо. Этот режим работы сети называется Wrap, то есть «свертывание» или «сворачивание» колец. Операция свертывания производится средствами концентраторов и/или сетевых адаптеров FDDI. Для упрощения этой процедуры данные по первичному кольцу всегда передаются в одном направлении (на диаграммах это направление изображается против часовой стрелки), а по вторичному - в обратном (изображается по часовой стрелке). Поэтому при образовании общего кольца из двух колец передатчики станций по-прежнему остаются подключенными к приемникам соседних станций, что позволяет правильно передавать и принимать информацию соседними станциями.

Рис. 2.42 – Реконфигурация колец FDDI при отказе
В стандартах FDDI много внимания отводится различным процедурам, которые позволяют определить наличие отказа в сети, а затем произвести необходимую реконфигурацию. Сеть FDDI может полностью восстанавливать свою работоспособность в случае единичных отказов ее элементов. При множественных отказах сеть распадается на несколько не связанных сетей. Технология FDDI дополняет механизмы обнаружения отказов технологии Token Ring механизмами реконфигурации пути передачи данных в сети, основанными на наличии резервных связей, обеспечиваемых вторым кольцом.
Кольца в сетях FDDI рассматриваются как общая разделяемая среда передачи данных, поэтому для нее определен специальный метод доступа. Этот метод очень близок к методу доступа сетей Token Ring и также называется методом маркерного кольца – token ring.
Отличия метода доступа заключаются в том, что время удержания маркера в сети FDDI не является постоянной величиной, как в сети Token Ring. Это время зависит от загрузки кольца – при небольшой загрузке оно увеличивается, а при больших перегрузках может уменьшаться до нуля. Эти изменения в методе доступа касаются только асинхронного трафика, который не критичен к небольшим задержкам передачи кадров. Для синхронного трафика время удержания маркера по-прежнему остается фиксированной величиной. Механизм приоритетов кадров, аналогичный принятому в технологии Token Ring, в технологии FDDI отсутствует. Разработчики технологии решили, что деление трафика на 8 уровней приоритетов избыточно и достаточно разделить трафик на два класса - асинхронный и синхронный, последний из которых обслуживается всегда, даже при перегрузках кольца.
В остальном пересылка кадров между станциями кольца на уровне MAC полностью соответствует технологии Token Ring. Станции FDDI применяют алгоритм раннего освобождения маркера, как и сети Token Ring со скоростью 16 Мбит/с.
Адреса уровня MAC имеют стандартный для технологий IEEE 802 формат. Формат кадра FDDI близок к формату кадра Token Ring, основные отличия заключаются в отсутствии полей приоритетов. Признаки распознавания адреса, копирования кадра и ошибки позволяют сохранить имеющиеся в сетях Token Ring процедуры обработки кадров станцией-отправителем, промежуточными станциями и станцией-получателем.
Особенности метода доступа FDDI. Для передачи синхронных кадров станция всегда имеет право захватить маркер при его поступлении. При этом время удержания маркера имеет заранее заданную фиксированную величину.
Если же станции кольца FDDI нужно передать асинхронный кадр (тип кадра определяется протоколами верхних уровней), то для выяснения возможности захвата маркера при его очередном поступлении станция должна измерить интервал времени, который прошел с момента предыдущего прихода маркера. Этот интервал называется временем оборота маркера (Token Rotation Time, TRT). Интервал TRT сравнивается с другой величиной - максимально допустимым временем оборота маркера по кольцу Т_0рг. Если в технологии Token Ring максимально допустимое время оборота маркера является фиксированной величиной (2,6 с из расчета 260 станций в кольце), то в технологии FDDI станции договариваются о величине Т_0рг во время инициализации кольца. Каждая станция может предложить свое значение Т_0рг, в результате для кольца устанавливается минимальное из предложенных станциями времен. Это позволяет учитывать потребности приложений, работающих на станциях. Обычно синхронным приложениям (приложениям реального времени) нужно чаще передавать данные в сеть небольшими порциями, а асинхронным приложениям лучше получать доступ к сети реже, но большими порциями. Предпочтение отдается станциям, передающим синхронный трафик.
Таким образом, при очередном поступлении маркера для передачи асинхронного кадра сравнивается фактическое время оборота маркера TRT с максимально возможным Т_0рг. Если кольцо не перегружено, то маркер приходит раньше, чем истекает интервал Т_0рг, то есть TRT < Т_0рг. В этом случае станции разрешается захватить маркер и передать свой кадр (или кадры) в кольцо. Время удержания маркера ТНТ равно разности T_0pr - TRT, и в течение этого времени станция передает в кольцо столько асинхронных кадров, сколько успеет.
Если же кольцо перегружено и маркер опоздал, то интервал TRT будет больше Т_0рг. В этом случае станция не имеет права захватить маркер для асинхронного кадра. Если все станции в сети хотят передавать только асинхронные кадры, а маркер сделал оборот по кольцу слишком медленно, то все станции пропускают маркер в режиме повторения, маркер быстро делает очередной оборот и на следующем цикле работы станции уже имеют право захватить маркер и передать свои кадры.
Метод доступа FDDI для асинхронного трафика является адаптивным и хорошо регулирует временные перегрузки сети.
Физический уровень технологии FDDI. В технологии FDDI для передачи световых сигналов по оптическим волокнам реализовано логическое кодирование 4В/5В в сочетании с физическим кодированием NRZI. Эта схема приводит к передаче по линии связи сигналов с тактовой частотой 125 МГц.
Так как из 32 комбинаций 5-битных символов для кодирования исходных 4-битных символов нужно только 16 комбинаций, то из оставшихся 16 выбрано несколько кодов, которые используются как служебные. К наиболее важным служебным символам относится символ Idle - простой, который постоянно передается между портами в течение пауз между передачей кадров данных. За счет этого станции и концентраторы сети FDDI имеют постоянную информацию о состоянии физических соединений своих портов. В случае отсутствия потока символов Idle фиксируется отказ физической связи и производится реконфигурация внутреннего пути концентратора или станции, если это возможно.
При первоначальном соединении кабелем двух узлов их порты сначала выполняют процедуру установления физического соединения. В этой процедуре используются последовательности служебных символов кода 4В/5В, с помощью которых создается некоторый язык команд физического уровня. Эти команды позволяют портам выяснить друг у друга типы портов (А, В, М или S) и решить, корректно ли данное соединение (например, соединение S-S является некорректным и т. п.). Если соединение корректно, то далее выполняется тест качества канала при передаче символов кодов 4В/5В, а затем проверяется работоспособность уровня MAC соединенных устройств путем передачи нескольких кадров MAC. Если все тесты прошли успешно, то физическое соединение считается установленным. Работу по установлению физического соединения контролирует протокол управления станцией SMT.
Физический уровень разделен на два подуровня: независимый от среды подуровень PHY (Physical) и зависящий от среды подуровень PMD (Physical Media Dependent).
Технология FDDI в настоящее время поддерживает два подуровня PMD: для волоконно-оптического кабеля и для неэкранированной витой пары категории 5. Последний стандарт появился позже оптического и носит название TP-PMD.
Оптоволоконный подуровень PMD обеспечивает необходимые средства для передачи данных от одной станции к другой по оптическому волокну. Его спецификация определяет:
использование в качестве основной физической среды многомодового волоконно-оптического кабеля 62,5/125 мкм;
требования к мощности оптических сигналов и максимальному затуханию между узлами сети. Для стандартного многомодового кабеля эти требования приводят к предельному расстоянию между узлами в 2 км, а для одномодового кабеля расстояние увеличивается до 10-40 км в зависимости от качества кабеля;
требования к оптическим обходным переключателям (optical bypass switches) и оптическим приемопередатчикам;
параметры оптических разъемов MIC (Media Interface Connector), их маркировку;
использование для передачи света с длиной волны в 1300 нм;
представление сигналов в оптических волокнах в соответствии с методом NRZI.
Подуровень TP-PMD определяет возможность передачи данных между станциями по витой паре в соответствии с методом физического кодирования MLT-3, использующего два уровня потенциала: +V и -V для представления данных в кабеле. Для получения равномерного по мощности спектра сигнала данные перед физическим кодированием проходят через скрэмблер. Максимальное расстояние между узлами в соответствии со стандартом TP-PMD равно 100 м.
Максимальная общая длина кольца FDDI составляет 100 километров, максимальное число станций с двойным подключением в кольце - 500.
Перенаправление маршрутов в сети TCP/IP
Протокол IP (Internet_протокол) является маршрутизируемым протоколом сети Internet. Пакеты маршрутизируются по оптимальному пути от отправителя к получателю на основе уникальных идентификаторов – IP-адресов. Данные могут быть правильно доставлены получателю в том случае, если в сети требуемым образом работают механизмы пересылки пакетов, устройства, преобразующие данные из одного формата в другой, а также протоколы с установлением и без установления соединения.
Маршрутизируемые и маршрутизирующие протоколы. Протоколом называется основанный на стандартах набор правил, определяющий принципы взаимодействия компьютеров в сети. Протокол также задает общие правила взаимодействия разнообразных приложений, сетевых узлов или систем, создавая, таким образом, единую среду передачи. Взаимодействующие друг с другом компьютеры обмениваются данными; чтобы принять и обработать сообщения с данными, компьютерам необходимо знать, как сформированы сообщения и что они означают. Примерами использования различных форматов сообщений в разных протоколах могут служить установление соединения с удаленной машиной, отправка сообщений по электронной почте или передача файлов и данных; интуитивно понятно, что разные службы используют разные сообщения.
Протокол описывает:
формат сообщения, которому приложения обязаны следовать;
способ обмена сообщениями между компьютерами в контексте определенного действия, такого, как отправка сообщений по сети.
Схожее звучание терминов ‘‘маршрутизируемый протокол’’ и ‘‘протокол маршрутизации’’ нередко приводит к путанице. Приведенные ниже определения помогут прояснить ситуацию.
Маршрутизируемый протокол - это любой сетевой протокол, адрес сетевого уровня которого предоставляет достаточное количество информации для доставки пакета от одного сетевого узла другому на основе используемой схемы адресации. Такой протокол задает форматы полей внутри пакета. Пакеты обычно передаются от одной конечной системы другой. Маршрутизируемый протокол использует таблицу маршрутизации для пересылки пакетов. В их число входят:
Internet протокол (IP);
протокол межсетевого пакетного обмена (Internetwork Packet Exchange - IPX);
протокол AppleTalk.
Протокол маршрутизации – это протокол, который поддерживает маршрутизируемые протоколы и предоставляет механизмы обмена маршрутной информацией. Сообщения протокола маршрутизации передаются между маршрутизаторами. Протокол маршрутизации позволяет маршрутизаторам обмениваться информацией друг с другом для обновления записей и поддержки таблиц маршрутизации. Ниже приводятся некоторые примеры протоколов маршрутизации TCP/IP:
протокол маршрутной информации (Routing Information Protocol — RIP);
протокол маршрутизации внутреннего шлюза (Interior Gateway Routing Protocol — IGRP);
усовершенствованный протокол маршрутизации внутреннего шлюза (Enhanced Interior Gateway Routing Protocol – EIGRP);
протокол первоочередного обнаружения кратчайших маршрутов (Open Shortest Path First – OSPF).
Чтобы протокол был маршрутизируемым, в нем должны наличествовать механизмы назначения как номера сети, так и номера узла для каждого отдельного сетевого устройства. В некоторых протоколах, таких, как, например, IPX, необходимо назначить только адрес сети, поскольку в качестве адреса устройства эта технология использует физический адрес (MAC-адрес) устройства. Другие протоколы, такие, как IP, требуют, чтобы явно был задан весь адрес и сетевая маска.
Для создания маршрутизируемой сети необходимы как IP-адрес, так и маска сети. Сетевая маска делит 32-битовый IP-адрес на сетевую часть и адрес узла. Протокол IPX использует MAC-адрес, объединенный с установленным администратором номером сети, для создания полного адреса и не требует использования сетевой маски. При использовании IP-технологий адрес сети вычисляется путем сравнения полного адреса и маски подсети.
Сетевая маска позволяет рассматривать группу последовательных IP-адресов как единое целое. Без такой возможности группировки адресов потребовался бы механизм маршрутизации для каждого отдельного узла. Такая схема была бы непригодна для миллионов узлов, работающих в сети Internet. На рис. 10.2 показано, что все 254 адреса в диапазоне от 192.168.10.1 до 192.168.10.254 могут быть представлены одним сетевым адресом 192.168.10.0. Такая возможность позволяет адресовать информацию любому из этих узлов, используя соответствующий адрес сети. Таким образом, таблицы маршрутизации должны содержать всего одну запись 192.168.10.0, вместо 254 записей для каждого отдельного узла.
Чтобы маршрутизация могла правильно функционировать, рекомендуется использовать группирование адресов.
IP как маршрутизируемый протокол. Протокол IP является наиболее широко распространенной реализацией иерархической схемы сетевой адресации. Используемый в сети Internet, протокол IP не отвечает за установку соединений, не является надежным и позволяет реализовать только негарантированную доставку данных. Термин протокол без установления соединения (connectionless) означает, что для взаимодействия не требуется выделенный канал, как это происходит во время телефонного звонка, и не существует процедуры вызова перед началом передачи данных между сетевыми узлами. Протокол IP выбирает наиболее эффективный маршрут из числа доступных на основе решения, принятого протоколом маршрутизации. Отсутствие надежности и негарантированная доставка не означает, что система работает плохо и ненадежно, а указывает лишь на то, что протокол IP не предпринимает никаких усилий, чтобы проверить, был ли доставлен пакет по назначению. Эти функции делегированы протоколам верхних уровней.
Информация, проходя сверху вниз по уровням OSI-модели, на каждом из уровней надлежащим образом обрабатывается. На сетевом уровне данные инкапсулируются внутрь пакетов, зачастую называемых дейтаграммами.
Протокол IP распознает формат заголовка пакета (включая адресную часть и другую служебную информацию), но никоим образом не заботится о фактических данных. Он принимает любые данные, переданные протоколами верхнего уровня.
Пересылка пакетов и коммутация внутри маршрутизатора. Заголовок и конец фрейма отбрасываются и заменяются новыми каждый раз при прохождении движущимся по сети пакетом маршрутизирующего устройства третьего уровня. Причина этого состоит в том, что блоки информации второго уровня (фреймы) используются для локальной доставки информации, в то время как блоки третьего уровня (пакеты) предназначены для сквозной передачи данных согласно схеме адресации.
Ethernet-фреймы второго уровня предназначены для работы внутри широковещательных доменов с назначенными каждому сетевому устройству MAC-адресами. Фреймы второго уровня других типов, такие, как последовательные двухточечные соединения и Frame Relay распределенных сетей (сетей WAN), используют свою собственную схему адресации второго уровня. Принципиальным является то, что, независимо от используемой схемы адресации второго уровня, все они разработаны для использования внутри одного широковещательного домена второго уровня. При прохождении данными через устройство третьего уровня информация второго уровня изменяется.
Схема обработки фрейма маршрутизатором показана на рисунке 2.

Рисунок 2 – Изменение пакета в процессе инкапсуляции в маршрутизаторе
Из пакета, приходящего на интерфейс маршрутизатора, извлекается MAC-адрес и проверяется, адресован ли этот пакет непосредственно какому-либо узлу либо интерфейсу или он является широковещательным; та же процедура выполняется всеми устройствами внутри домена коллизий. В любом из указанных вариантов пакет будет принят и обработан; в противном случае пакет будет отброшен, поскольку был адресован другому устройству в домене коллизий. Таким образом, домен коллизий – это разделяемая среда передачи данных, в которой устройства работают в режиме конкуренции. На основании значения, содержащегося в поле контрольной суммы, с помощью циклического избыточного кода (Cyclical Redundancy Check – CRC), извлеченного из окончания полученного фрейма, проверяется, не были ли данные повреждены. Если проверка дает отрицательный результат, такой фрейм отбрасывается. В случае положительного результата проверки заголовок и окончание фрейма удаляются, и пакет передается на третий уровень. Далее выполняется проверка, адресован ли пакет маршрутизатору или потребуется его дальнейшая маршрутизация на пути к пункту назначения. Пакеты, адресованные маршрутизатору в качестве IP-адреса получателя, содержат адрес одного из интерфейсов маршрутизатора. У таких пакетов удаляется заголовок, и они передаются на четвертый уровень. Если пакету предстоит маршрутизация, он сравнивается с записями в таблице маршрутизации. Если будет найдено точное соответствие или существует стандартный маршрут, пакет будет отправлен на интерфейс, указанный в соответствующей записи таблицы маршрутизации.
Когда пакет коммутируется на выходной интерфейс, новое значение CRC добавляется в конец фрейма и, в зависимости от типа интерфейса (Ethernet, Frame Relay или последовательный), пакету добавляется соответствующий заголовок. После этого фрейм пересылается в другой широковещательный домен, являющийся следующей частью маршрута к конечному пункту назначения.
Технология маршрутизации. Маршрутизация является функцией третьего уровня модели OSI. Она основана на иерархической схеме, которая позволяет группировать отдельные адреса и работать с группами как с единым целым до тех пор, пока не потребуется установить индивидуальный адрес для окончательной доставки данных. Под термином ‘‘маршрутизация’’ подразумевают процесс определения наиболее эффективного пути от одного устройства к другому. Основным устройством, отвечающим за осуществление процесса маршрутизации, является маршрутизатор.
Маршрутизатор выполняет две ключевые функции:
поддерживает таблицы маршрутизации и обменивается информацией об изменениях в топологии сети с другими маршрутизаторами. Эта функция реализуется с помощью одного или нескольких протоколов маршрутизации для передачи сетевой информации другим маршрутизаторам;
когда пакеты приходят на один из интерфейсов, маршрутизатор, руководствуясь таблицей маршрутизации, должен определить, куда именно следует отправить пакет. Он перенаправляет пакеты на выбранный интерфейс, создает фреймы и затем пересылает их.
Маршрутизатор является устройством сетевого уровня и использует одну или несколько метрик маршрутизации (routing metric), для того чтобы установить оптимальный путь, по которому должен следовать сетевой трафик. Метрика маршрутизации - это параметр, по которому определяется наиболее предпочтительный маршрут. Протоколы маршрутизации используют различные комбинации параметров для расчета метрик.
Для определения наилучшего межсетевого маршрута вычисляются различные комбинации компонентов метрики: количество ретрансляций (т.е. транзитных узлов), полоса пропускания, задержки, надежность, загрузка и стоимость. Маршрутизаторы объединяют сетевые сегменты или целые сети. Фреймы данных они передают на основе информации протокола третьего уровня. Маршрутизаторы принимают логическое решение о наилучшем маршруте доставки данных между сетями и отправляют пакеты в соответствующий исходящий порт для последующей инкапсуляции и пересылки. Процессы инкапсуляции и декапсуляции происходят каждый раз, когда пакеты проходят через маршрутизатор и данные передаются от одного устройства другому (рис. 10.12). При выполнении инкапсуляции поток данных разбивается на сегменты, добавляются необходимые заголовки и концы, после чего данные передаются по сети. Декапсуляция – это обратный процесс, при котором удаляются заголовки и концы, а данные собираются в неразрывный поток. Маршрутизаторы принимают фреймы от устройств локальной сети (например, рабочих станций) и на основе информации третьего уровня пересылают их по сети.
Маршрутизацию часто путают с коммутацией второго уровня, которая, как может показаться при поверхностном рассмотрении, выполняет те же функции. Принципиальное различие состоит в том, что коммутация реализована на втором уровне модели OSI, а маршрутизация – на третьем. Такое принципиальное отличие означает, что маршрутизация и коммутация используют разную информацию для организации передачи данных от отправителя получателю.
Коммутатор передает фрейм маршрутизатору на основе его MAC-адреса. Маршрутизатор анализирует адрес получателя третьего уровня в пакете для принятия решения о выборе маршрута. Стандартный шлюз — это маршрутизатор, находящийся в той же сети или подсети, что и узел Х. Подобно тому, как коммутатор второго уровня хранит таблицу известных MAC-адресов, маршрутизатор работает с набором IP-адресов сетей, который формирует базу данных доступных ему сетей, называющуюся таблицей маршрутизации.
Каждый компьютер и Ethernet-интерфейс маршрутизатора поддерживают ARP-таблицу для взаимодействий второго уровня; такие таблицы актуальны только для того широковещательного домена, к которому подключено данное устройство. Маршрутизатор, кроме этого, поддерживает еще и таблицу маршрутизации, которая дает возможность выбирать маршрут для доставки данных за пределы широковещательного домена. Каждая ARP-таблица содержит пары IP и MAC-адресов. Таблица маршрутизации содержит информацию о маршрутах; IP-адреса доступных сетей, значение счетчика транзитных узлов до этих известных сетей и интерфейсы, через которые информация будет отправлена в нужную сеть. Разница между двумя рассмотренными типами адресов состоит в том, что MAC-адреса не организованы по какому-то определенному принципу. Однако этот недостаток не вызывает проблем с управлением сетями, поскольку отдельные сетевые сегменты не содержат большого количества узлов. Если бы IP-адреса подчинялись тем же правилам, сеть Internet просто не смогла бы функционировать. В том случае, если бы IP-адреса не были организованы (иерархически или как-либо еще), то не существовало бы способа определить маршрут для достижения каждого конкретного адреса. Иерархическая организация IP-адресов позволяет рассматривать группы адресов как единое целое до тех пор, пока не потребуется определить адрес индивидуального узла. Понять такой подход в адресации можно на примере библиотеки, хранящей миллионы отдельных страниц в одной большой кипе бумаг. В таком случае воспользоваться необходимым материалом будет невозможно, поскольку нет способа найти необходимый документ. Намного проще воспользоваться нужной информацией, если страницы пронумерованы, переплетены в книги и каждая внесена в каталог.
Протокол ARP. ARP-таблица, порядок преобразования адресов, запросы и ответы
Для отображения IP-адресов в Ethernet адреса используется протокол ARP (Address Resolution Protocol – адресный протокол). Отображение выполняется только для отправляемых IP-пакетов, так как только в момент отправки создаются заголовки IP и Ethernet. ARP-таблица для преобразования адресов. Преобразование адресов выполняется путем поиска в таблице. Эта таблица, называемая ARP-таблицей, хранится в памяти и содержит строки для каждого узла сети. В двух столбцах содержатся IP- и Ethernet-адреса. Если требуется преобразовать IP-адрес в Ethernet-адрес, то ищется запись с соответствующим IP-адресом. Ниже приведен пример упрощенной ARP-таблицы.
---------------------------------------------
| IP-адрес Ethernet-адрес |
---------------------------------------------
| 223.1.2.1 08:00:39:00:2F:C3 |
| 223.1.2.3 08:00:5A:21:A7:22 |
| 223.1.2.4 08:00:10:99:AC:54 |
---------------------------------------------
Табл.1. Пример ARP-таблицы
Принято все байты 4-байтного IP-адреса записывать десятичными числами, разделенными точками. При записи 6-байтного Ethernet-адреса каждый байт указывается в 16-ричной системе и отделяется двоеточием.
ARP-таблица необходима потому, что IP-адреса и Ethernet-адреса выбираются независимо, и нет какого-либо алгоритма для преобразования одного в другой. IP-адрес выбирает менеджер сети с учетом положения машины в сети internet. Если машину перемещают в другую часть сети internet, то ее IP-адрес должен быть изменен. Ethernet-адрес выбирает производитель сетевого интерфейсного оборудования из выделенного для него по лицензии адресного пространства. Когда у машины заменяется плата сетевого адаптера, то меняется и ее Ethernet-адрес.
Порядок преобразования адресов. В ходе обычной работы сетевая программа, такая как TELNET, отправляет прикладное сообщение, пользуясь транспортными услугами TCP. Модуль TCP посылает соответствующее транспортное сообщение через модуль IP. В результате составляется IP-пакет, который должен быть передан драйверу Ethernet. IP-адрес места назначения известен прикладной программе, модулю TCP и модулю IP. Необходимо на его основе найти Ethernet-адрес места назначения. Для определения искомого Ethernet-адреса используется ARP-таблица.
Запросы и ответы протокола ARP. Как же заполняется ARP-таблица? Она заполняется автоматически модулем ARP, по мере необходимости. Когда с помощью существующей ARP-таблицы не удается преобразовать IP-адрес, то происходит следующее:
По сети передается широковещательный ARP-запрос.
Исходящий IP-пакет ставится в очередь.
Каждый сетевой адаптер принимает широковещательные передачи. Все драйверы Ethernet проверяют поле типа в принятом Ethernet-кадре и передают ARP-пакеты модулю ARP. ARP-запрос можно интерпретировать так: "Если ваш IP-адрес совпадает с указанным, то сообщите мне ваш Ethernet-адрес". Пакет ARP-запроса выглядит примерно так:
-----------------------------------------------------------
| IP-адрес отправителя 223.1.2.1 |
| Ethernet-адрес отправителя 08:00:39:00:2F:C3 |
-----------------------------------------------------------
| Искомый IP-адрес 223.1.2.2 |
| Искомый Ethernet-адрес <пусто> |
-----------------------------------------------------------
Табл.2. Пример ARP-запроса
Каждый модуль ARP проверяет поле искомого IP-адреса в полученном ARP-пакете и, если адрес совпадает с его собственным IP-адресом, то посылает ответ прямо по Ethernet-адресу отправителя запроса. ARP-ответ можно интерпретировать так: "Да, это мой IP-адрес, ему соответствует такой-то Ethernet-адрес". Пакет с ARP-ответом выглядит примерно так:
-----------------------------------------------------------
| IP-адрес отправителя 223.1.2.2 |
| Ethernet-адрес отправителя 08:00:28:00:38:A9 |
-----------------------------------------------------------
| Искомый IP-адрес 223.1.2.1 |
| Искомый Ethernet-адрес 08:00:39:00:2F:C3 |
-----------------------------------------------------------
Табл.3. Пример ARP-ответа
Этот ответ получает машина, сделавшая ARP-запрос. Драйвер этой машины проверяет поле типа в Ethernet-кадре и передает ARP-пакет модулю ARP. Модуль ARP анализирует ARP-пакет и добавляет запись в свою ARP-таблицу.
Обновленная таблица выглядит следующим образом:
---------------------------------------------
| IP-адрес Ethernet-адрес |
---------------------------------------------
| 223.1.2.1 08:00:39:00:2F:C3 |
| 223.1.2.2 08:00:28:00:38:A9 |
| 223.1.2.3 08:00:5A:21:A7:22 |
| 223.1.2.4 08:00:10:99:AC:54 |
---------------------------------------------
Табл.4. ARP-таблица после обработки ответа
Новая запись в ARP-таблице появляется автоматически, спустя несколько миллисекунд после того, как она потребовалась. Как вы помните, ранее на шаге 2 исходящий IP-пакет был поставлен в очередь. Теперь с использованием обновленной ARP-таблицы выполняется преобразование IPадреса в Ethernet-адрес, после чего Ethernet-кадр передается по сети. Полностью порядок преобразования адресов выглядит так:
По сети передается широковещательный ARP-запрос.
Исходящий IP-пакет ставится в очередь.
Возвращается ARP-ответ, содержащий информацию о соответствии IP- и Ethernet-адресов. Эта информация заносится в ARP-таблицу.
Для преобразования IP-адреса в Ethernet-адрес у IP-пакета, постав ленного в очередь, используется ARP-таблица.
Ethernet-кадр передается по сети Ethernet.
Короче говоря, если с помощью ARP-таблицы не удается сразу осуществить преобразование адресов, то IP-пакет ставится в очередь, а необходимая для преобразования информация получается с помощью запросов и ответов протокола ARP, после чего IP-пакет передается по назначению.
Если в сети нет машины с искомым IP-адресом, то ARP-ответа не будет и не будет записи в ARP-таблице. Протокол IP будет уничтожать IP-пакеты, направляемые по этому адресу. Протоколы верхнего уровня не могут отличить случай повреждения сети Ethernet от случая отсутствия машины с искомым IP-адресом.
Некоторые реализации IP и ARP не ставят в очередь IP-пакеты на то время, пока они ждут ARP-ответов. Вместо этого IP-пакет просто уничтожается, а его восстановление возлагается на модуль TCP или прикладной процесс, работающий через UDP. Такое восстановление выполняется с помощью таймаутов и повторных передач. Повторная передача сообщения проходит успешно, так как первая попытка уже вызвала заполнение ARP-таблицы.
Следует отметить, что каждая машина имеет отдельную ARP-таблицу для каждого своего сетевого интерфейса.
Протокол IP. Прямая и косвенная маршрутизация
Модуль IP является базовым элементом технологии internet, а центральной частью IP является его таблица маршрутов. Протокол IP использует эту таблицу при принятии всех решений о маршрутизации IP-пакетов. Содержание таблицы маршрутов определяется администратором сети. Ошибки при установке маршрутов могут заблокировать передачи.
Чтобы понять технику межсетевого взаимодействия, нужно понять то, как используется таблица маршрутов. Это понимание необходимо для успешного администрирования и сопровождения IP-сетей.
Прямая маршрутизация. На рисунке показана небольшая IP-сеть, состоящая из 3 машин: A, B и C. Каждая машина имеет такой же стек протоколов TCP/IP как на рис.1. Каждый сетевой адаптер этих машин имеет свой Ethernet-адрес. Менеджер сети должен присвоить машинам уникальные IP-адреса.
A B C
| | |
--------------o------o------o-----
Ethernet 1
IP-сеть "development"
Простая IP-сеть
Когда A посылает IP-пакет B, то заголовок IP-пакета содержит в поле отправителя IP-адрес узла A, а заголовок Ethernet-кадра содержит в поле отправителя Ethernet-адрес A. Кроме этого, IP-заголовок содержит в поле получателя IP-адрес узла B, а Ethernet-заголовок содержит в поле получателя Ethernet-адрес B.
-----------------------------------------------------
| адрес отправитель получатель |
-----------------------------------------------------
| IP-заголовок A B |
| Ethernet-заголовок A B |
-----------------------------------------------------
Адреса в Ethernet-кадре, передающем IP-пакет от A к B
В этом простом примере протокол IP является излишеством, которое мало что добавляет к услугам, предоставляемым сетью Ethernet. Однако протокол IP требует дополнительных расходов на создание, передачу и обработку IP-заголовка. Когда в машине B модуль IP получает IP-пакет от машины A, он сопоставляет IP-адрес места назначения со своим и, если адреса совпадают, то передает датаграмму протоколу верхнего уровня.
В данном случае при взаимодействии A с B используется прямая маршрутизация.
Косвенная маршрутизация. На рисунке представлена более реалистичная картина сети internet. В данном случае сеть internet состоит из трех сетей Ethernet, на базе которых работают три IP-сети, объединенные шлюзом D. Каждая IP-сеть включает четыре машины; каждая машина имеет свои собственные IP- и Ethernet адреса.
----- D ------
A B C | | | E F G
| | | | | | | | |
----o-----o-----o-----o-- | --o-----o-----o-----o--
Ethernet 1 | Ethernet 2
IP-сеть "development" | IP-сеть "accounting"
|
| H I J
| | | |
--o----o-----o-----o---------
Ethernet 3
IP-сеть "fuctory"
Рис. 7. Сеть internet, состоящая из трех IP-сетей
За исключением D все машины имеют стек протоколов, аналогичный показанному на рисунке. Шлюз D соединяет все три сети и, следовательно, имеет три IP-адреса и три Ethernet-адреса. Машина D имеет стек протоколов TCP/IP, похожий на тот, что показан на рис.3, но вместо двух модулей ARP и двух драйверов, он содержит три модуля ARP и три драйвера Ethernet. Обратим внимание на то, что машина D имеет только один модуль IP.
Менеджер сети присваивает каждой сети Ethernet уникальный номер, называемый IP-номером сети. На рис.7 IP-номера не показаны, вместо них используются имена сетей.
Когда машина A посылает IP-пакет машине B, то процесс передачи идет в пределах одной сети. При всех взаимодействиях между машинами, подключенными к одной IP-сети, используется прямая маршрутизация, обсуждавшаяся в предыдущем примере.
Когда машина D взаимодействует с машиной A, то это прямое взаимодействие. Когда машина D взаимодействует с машиной E, то это прямое взаимодействие. Когда машина D взаимодействует с машиной H, то это прямое взаимодействие. Это так, поскольку каждая пара этих машин принадлежит одной IP-сети.
Однако когда машина A взаимодействует с машинами, включенными в другую IP-сеть, то взаимодействие уже не будет прямым. Машина A должена использовать шлюз D для ретрансляции IP-пакетов в другую IP-сеть. Такое взаимодействие называется "косвенным".
Маршрутизация IP-пакетов выполняется модулями IP и является прозрачной для модулей TCP, UDP и прикладных процессов.
Если машина A посылает машине E IP-пакет, то IP-адрес и Ethernet-адрес отправителя соответствуют адресам A. IP-адрес места назначения является адресом E, но поскольку модуль IP в A посылает IP-пакет через D, Ethernet-адрес места назначения является адресом D.
----------------------------------------------------
| адрес отправитель получатель |
---------------------------------------------------
| IP-заголовок A E |
| Ethernet-заголовок A D |
---------------------------------------------------
Табл.6. Адреса в Ethernet-кадре, содержащем IP-пакет от A к E
Модуль IP в машине D получает IP-пакет и проверяет IP-адрес места назначения. Определив, что это не его IP-адрес, шлюз D посылает этот IP-пакет прямо к E.
----------------------------------------------------
| адрес отправитель получатель |
----------------------------------------------------
| IP-заголовок A E |
| Ethernet-заголовок D E |
----------------------------------------------------
Табл.7. Адреса в Ethernet-кадре, содержащем IP-пакет от A к E (после шлюза D)
Итак, при прямой маршрутизации IP- и Ethernet-адреса отправителя соответствуют адресам того узла, который послал IP-пакет, а IP- и Ethernet-адреса места назначения соответствуют адресам получателя. При косвенной маршрутизации IP- и Ethernet-адреса не образуют таких пар.
В данном примере сеть internet является очень простой. Реальные сети могут быть гораздо сложнее, так как могут содержать несколько шлюзов и несколько типов физических сред передачи. В приведенном примере несколько сетей Ethernet объединяются шлюзом для того, чтобы локализовать широковещательный трафик в каждой сети.
Технология 100VG-AnyLan. Топология оборудования и хабы. Кадр передачи
Технология 100VG-AnyLAN отличается от классического Ethernet в значительно большей степени, чем Fast Ethernet. Главные отличия перечислены ниже.
Используется другой метод доступа Demand Priority, который обеспечивает более справедливое распределение пропускной способности сети по сравнению с методом CSMA/CD, Кроме того, этот метод поддерживает приоритетный доступ для синхронных приложений.
Кадры передаются не всем станциям сети, а только станции назначения.
В сети есть выделенный арбитр доступа - концентратор, и это заметно отличает данную технологию от других, в которых применяется распределенный между станциями сети алгоритм доступа.
Поддерживаются кадры двух технологий - Ethernet и Token Ring (именно это обстоятельство дало добавку AnyLAN в названии технологии).
Данные передаются одновременно по 4 парам кабеля UTP категории 3. По каждой паре данные передаются со скоростью 25 Мбит/с, что в сумме дает 100 Мбит/с. В отличие от Fast Ethernet в сетях 100VG-AnyLAN нет коллизий, поэтому удалось использовать для передачи все четыре пары стандартного кабеля категории 3. Для кодирования данных применяется код 5В/6В, который обеспечивает спектр сигнала в диапазоне до 16 МГц (полоса пропускания UTP категории 3) при скорости передачи данных 25 Мбит/с. Метод доступа Demand Priority основан на передаче концентратору функций арбитра, решающего проблему доступа к разделяемой среде. Сеть 100VG-AnyLAN состоит из центрального концентратора, называемого также корневым, и соединенных с ним конечных узлов и других концентраторов (рис. 1).

Рисунок 1 – Сеть 100VG-AnyLAN
Допускаются три уровня каскадирования. Каждый концентратор и сетевой адаптер l00VG-AnyLAN должен быть настроен либо на работу с кадрами Ethernet, либо с кадрами Token Ring, причем одновременно циркуляция обоих типов кадров не допускается.
Концентратор циклически выполняет опрос портов. Станция, желающая передать пакет, посылает специальный низкочастотный сигнал концентратору, запрашивая передачу кадра и указывая его приоритет. В сети l00VG-AnyLAN используются два уровня приоритетов – низкий и высокий. Низкий уровень приоритета соответствует обычным данным (файловая служба, служба печати и т. п.), а высокий приоритет соответствует данным, чувствительным к временным задержкам (например, мультимедиа). Приоритеты запросов имеют статическую и динамическую составляющие, то есть станция с низким уровнем приоритета, долго не имеющая доступа к сети, получает высокий приоритет.
Если сеть свободна, то концентратор разрешает передачу пакета. После анализа адреса получателя в принятом пакете концентратор автоматически отправляет пакет станции назначения. Если сеть занята, концентратор ставит полученный запрос в очередь, которая обрабатывается в соответствии с порядком поступления запросов и с учетом приоритетов. Если к порту подключен другой концентратор, то опрос приостанавливается до завершения опроса концентратором нижнего уровня. Станции, подключенные к концентраторам различного уровня иерархии, не имеют преимуществ по доступу к разделяемой среде, так как решение о предоставлении доступа принимается после проведения опроса всеми концентраторами опроса всех своих портов.
Остается неясным вопрос – каким образом концентратор узнает, к какому порту подключена станция назначения? Во всех других технологиях кадр просто передавался всем станциям сети, а станция назначения, распознав свой адрес, копировала кадр в буфер. Для решения этой задачи концентратор узнает MAC адрес станции в момент физического присоединения ее к сети кабелем. Если в других технологиях процедура физического соединения выясняет связность кабеля (link test в технологии l0Base-T), тип порта (технология FDDI), скорость работы порта (процедура auto-negotiation в Fast Ethernet), то в технологии l00VG-AnyLAN концентратор при установлении физического соединения выясняет MAC адрес станции. И запоминает его в таблице адресов MAC, аналогичной таблице моста/коммутатора. Отличие концентратора l00VG-AnyLAN от моста/коммутатора в том, что у него нет внутреннего буфера для хранения кадров. Поэтому он принимает от станций сети только один кадр, отправляет его на порт назначения и, пока этот кадр не будет полностью принят станцией назначения, новые кадры концентратор не принимает. Так что эффект разделяемой среды сохраняется. Улучшается только безопасность сети - кадры не попадают на чужие порты, и их труднее перехватить.
Технология l00VG-AnyLAN поддерживает несколько спецификаций физического уровня. Первоначальный вариант был рассчитан на четыре неэкранированные витые пары категорий 3,4,5. Позже появились варианты физического уровня, рассчитанные на две неэкранированные витые пары категории 5, две экранированные витые пары типа 1 или же два оптических многомодовых оптоволокна.
Важная особенность технологии l00VG-AnyLAN - сохранение форматов кадров Ethernet и Token Ring. Сторонники l00VG-AnyLAN утверждают, что этот подход облегчит межсетевое взаимодействие через мосты и маршрутизаторы, а также обеспечит совместимость с существующими средствами сетевого управления, в частности с анализаторами протоколов.
Несмотря на много хороших технических решений, технология l00VG-AnyLAN не нашла большого количества сторонников и значительно уступает по популярности технологии Fast Ethernet.
Эталонная модель взаимодействия открытых систем
Открытой системой может быть названа любая система (компьютер, вычислительная сеть, ОС, программный пакет, другие аппаратные и программные продукты), которая построена в соответствии с открытыми спецификациями. Под термином «спецификация» (в вычислительной технике) понимают формализованное описание аппаратных или программных компонентов, способов их функционирования, взаимодействия с другими компонентами, условий эксплуатации, ограничений и особых характеристик. В свою очередь, под открытыми спецификациями понимаются опубликованные, общедоступные спецификации, соответствующие стандартам и принятые в результате достижения согласия после всестороннего обсуждения всеми заинтересованными сторонами.
В начале 80-х годов ряд международных организаций по стандартизации разработали модель, которая сыграла значительную роль в развитии сетей. Эта модель называется моделью взаимодействия открытых систем (Open System Interconnection, OSI) или моделью OSI. Модель OSI определяет различные уровни взаимодействия систем, дает им стандартные имена и указывает, какие функции должен выполнять каждый уровень. Модель OSI была разработана на основании большого опыта, полученного при создании компьютерных сетей, в основном глобальных, в 70-е годы. Полное описание этой модели занимает более 1000 страниц текста.
В модели OSI (рис. 2.5) средства взаимодействия делятся на семь уровней: прикладной, представительный, сеансовый, транспортный, сетевой, канальный и физический. Каждый уровень имеет дело с одним определенным аспектом взаимодействия сетевых устройств.

Рис. 2.5 Модель взаимодействия открытых систем ISO/OSI
Модель OSI описывает только системные средства взаимодействия, реализуемые операционной системой, системными утилитами, системными аппаратными средствами. Модель не включает средства взаимодействия приложений конечных пользователей. Свои собственные протоколы взаимодействия приложения реализуют, обращаясь к системным средствам. Поэтому необходимо различать уровень взаимодействия приложений и прикладной уровень.
Следует также иметь в виду, что приложение может взять на себя функции некоторых верхних уровней модели OSI. Например, некоторые СУБД имеют встроенные средства удаленного доступа к файлам. В этом случае приложение, выполняя доступ к удаленным ресурсам, не использует системную файловую службу; оно обходит верхние уровни модели OSI и обращается напрямую к системным средствам, ответственным за транспортировку сообщений по сети, которые располагаются на нижних уровнях модели OSI.
Итак, пусть приложение обращается с запросом к прикладному уровню, например к файловой службе. На основании этого запроса программное обеспечение прикладного уровня формирует сообщение стандартного формата. Обычное сообщение состоит из заголовка и поля данных. Заголовок содержит служебную информацию, которую необходимо передать через сеть прикладному уровню машины-адресата, чтобы сообщить ему, какую работу надо выполнить. В нашем случае заголовок, очевидно, должен содержать информацию о месте нахождения файла и о типе операции, которую необходимо над ним выполнить. Поле данных сообщения может быть пустым или содержать какие-либо данные, например те, которые необходимо записать в удаленный файл. Но для того чтобы доставить эту информацию по назначению, предстоит решить еще много задач, ответственность за которые несут нижележащие уровни.
После формирования сообщения прикладной уровень направляет его вниз по стеку представительному уровню. Протокол представительного уровня на основании информации, полученной из заголовка прикладного уровня, выполняет требуемые действия и добавляет к сообщению собственную служебную информацию - заголовок представительного уровня, в котором содержатся указания для протокола представительного уровня машины-адресата. Полученное в результате сообщение передается вниз сеансовому уровню, который в свою очередь добавляет свой заголовок, и т. д. Наконец, сообщение достигает нижнего, физического уровня, который собственно и передает его по линиям связи машине-адресату. К этому моменту сообщение «обрастает» заголовками всех уровней (рис. 2.6).
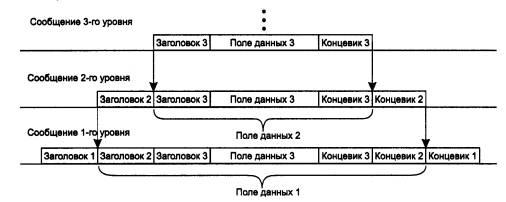
Рис. 2.6 Вложенность сообщений различных уровней
Когда сообщение по сети поступает на машину - адресат, оно принимается ее физическим уровнем и последовательно перемещается вверх с уровня на уровень. Каждый уровень анализирует и обрабатывает заголовок своего уровня, выполняя соответствующие данному уровню функции, а затем удаляет этот заголовок и передает сообщение вышележащему уровню.
Наряду с термином сообщение (message) существуют и другие термины, применяемые сетевыми специалистами для обозначения единиц данных в процедурах обмена. В стандартах ISO для обозначения единиц данных, с которыми имеют дело протоколы разных уровней, используется общее название протокольный блок данных (Protocol Data Unit, PDU). Для обозначения блоков данных определенных уровней-часто используются специальные названия: кадр (frame), пакет (packet), дейтаграмма (datagram), сегмент (segment).
В модели OSI различаются два основных типа протоколов. В протоколах с установлением соединения (connection-oriented) перед обменом данными отправитель и получатель должны сначала установить соединение и, возможно, выбрать некоторые параметры протокола, которые они будут использовать при обмене данными. После завершения диалога они должны разорвать это соединение. Телефон - это пример взаимодействия, основанного на установлении соединения.
Вторая группа протоколов - протоколы без предварительного установления соединения (connectionless). Такие протоколы называются также дейтаграммными протоколами. Отправитель просто передает сообщение, когда оно готово. Опускание письма в почтовый ящик - это пример связи без предварительного установления соединения. При взаимодействии компьютеров используются протоколы обоих типов.
Уровни модели OSI
Физический уровень. Физический уровень (Physical layer) имеет дело с передачей битов по физическим каналам связи, таким, например, как коаксиальный кабель, витая пара, оптоволоконный кабель или цифровой территориальный канал. К этому уровню имеют отношение характеристики физических сред передачи данных, такие как полоса пропускания, помехозащищенность, волновое сопротивление и другие. На этом же уровне определяются характеристики электрических сигналов, передающих дискретную информацию, например, крутизна фронтов импульсов, уровни напряжения или тока передаваемого сигнала, тип кодирования, скорость передачи сигналов. Кроме этого, здесь стандартизуются типы разъемов и назначение каждого контакта.
Функции физического уровня реализуются во всех устройствах, подключенных к сети. Со стороны компьютера функции физического уровня выполняются сетевым адаптером или последовательным портом.
Примером протокола физического уровня может служить спецификация l0-Base-T технологии Ethernet, которая определяет в качестве используемого кабеля неэкранированную витую пару категории 3 с волновым сопротивлением 100 Ом, разъем RJ-45, максимальную длину физического сегмента 100 метров, манчестерский код для представления данных в кабеле, а также некоторые другие характеристики среды и электрических сигналов.
Канальный уровень. На физическом уровне просто пересылаются биты. При этом не учитывается, что в некоторых сетях, в которых линии связи используются (разделяются) попеременно несколькими парами взаимодействующих компьютеров, физическая среда передачи может быть занята. Поэтому одной из задач канального уровня (Data Link layer) является проверка доступности среды передачи. Другой задачей канального уровня является реализация механизмов обнаружения и коррекции ошибок. Для этого на канальном уровне биты группируются в наборы, называемые кадрами (frames). Канальный уровень обеспечивает корректность передачи каждого кадра, помещая специальную последовательность бит в начало и конец каждого кадра, для его выделения, а также вычисляет контрольную сумму, обрабатывая все байты кадра определенным способом и добавляя контрольную сумму к кадру. Когда кадр приходит по сети, получатель снова вычисляет контрольную сумму полученных данных и сравнивает результат с контрольной суммой из кадра. Если они совпадают, кадр считается правильным и принимается. Если же контрольные суммы не совпадают, то фиксируется ошибка. Канальный уровень может не только обнаруживать ошибки, но и исправлять их за счет повторной передачи поврежденных кадров. Необходимо отметить, что функция исправления ошибок не является обязательной для канального уровня, поэтому в некоторых протоколах этого уровня она отсутствует, например, в Ethernet и frame relay.
В протоколах канального уровня, используемых в локальных сетях, заложена определенная структура связей между компьютерами и способы их адресации. Хотя канальный уровень и обеспечивает доставку кадра между любыми двумя узлами локальной сети, он это делает только в сети с совершенно определенной топологией связей, именно той топологией, для которой он был разработан. К таким типовым топологиям, поддерживаемым протоколами канального уровня локальных сетей, относятся общая шина, кольцо и звезда, а также структуры, полученные из них с помощью мостов и коммутаторов. Примерами протоколов канального уровня являются протоколы Ethernet, Token Ring, FDDI, l00VG-AnyLAN.
В локальных сетях протоколы канального уровня используются компьютерами, мостами, коммутаторами и маршрутизаторами. В компьютерах функции канального уровня реализуются совместными усилиями сетевых адаптеров и их драйверов.
Тем не менее для обеспечения качественной транспортировки сообщений в сетях любых топологий и технологий функций канального уровня оказывается недостаточно, поэтому в модели OSI решение этой задачи возлагается на два следующих уровня - сетевой и транспортный.
Сетевой уровень. Сетевой уровень (Network layer) служит для образования единой транспортной системы, объединяющей несколько сетей, причем эти сети могут использовать совершенно различные принципы передачи сообщений между конечными узлами и обладать произвольной структурой связей. Функции сетевого уровня достаточно разнообразны. Начнем их рассмотрение на примере объединения локальных сетей.
Протоколы канального уровня локальных сетей обеспечивают доставку данных между любыми узлами только в сети с соответствующей типовой топологией, например топологией иерархической звезды. Это очень жесткое ограничение, которое не позволяет строить сети с развитой структурой, например, сети, объединяющие несколько сетей предприятия в единую сеть, или высоконадежные сети, в которых существуют избыточные связи между узлами. Можно было бы усложнять протоколы канального уровня для поддержания петлевидных избыточных связей, но принцип разделения обязанностей между уровнями приводит к другому решению. Чтобы с одной стороны сохранить простоту процедур передачи данных для типовых топологий, а с другой допустить использование произвольных топологий, вводится дополнительный сетевой уровень.
На сетевом уровне сам термин сеть наделяют специфическим значением. В данном случае под сетью понимается совокупность компьютеров, соединенных между собой в соответствии с одной из стандартных типовых топологий и использующих для передачи данных один из протоколов канального уровня, определенный для этой топологии.
Внутри сети доставка данных обеспечивается соответствующим канальным уровнем, а вот доставкой данных между сетями занимается сетевой уровень, который и поддерживает возможность правильного выбора маршрута передачи сообщения даже в том случае, когда структура связей между составляющими сетями имеет характер, отличный от принятого в протоколах канального уровня. Сети соединяются между собой специальными устройствами, называемыми маршрутизаторами. Маршрутизатор - это устройство, которое собирает информацию о топологии межсетевых соединений и на ее основании пересылает пакеты сетевого уровня в сеть назначения. Чтобы передать сообщение от отправителя, находящегося в одной сети, получателю, находящемуся в другой сети, нужно совершить некоторое количество транзитных передач между сетями, или хопов (от hop - прыжок), каждый раз выбирая подходящий маршрут. Таким образом, маршрут представляет собой последовательность маршрутизаторов, через которые проходит пакет.
На рис. 2.7 показаны четыре сети, связанные тремя маршрутизаторами. Между узлами А и В данной сети пролегают два маршрута: первый через маршрутизаторы 1 и 3, а второй через маршрутизаторы 1, 2 и 3.

Рис. 2.7 Пример составной сети
Проблема выбора наилучшего пути называется маршрутизацией, и ее решение является одной из главных задач сетевого уровня. Эта проблема осложняется тем, что самый короткий путь не всегда самый лучший. Часто критерием при выборе маршрута является время передачи данных по этому маршруту; оно зависит от пропускной способности каналов связи и интенсивности трафика, которая может изменяться с течением времени. Некоторые алгоритмы маршрутизации пытаются приспособиться к изменению нагрузки, в то время как другие принимают решения на основе средних показателей за длительное время. Выбор маршрута может осуществляться и по другим критериям, например надежности передачи.
В общем случае функции сетевого уровня шире, чем функции передачи сообщений по связям с нестандартной структурой, которые мы сейчас рассмотрели на примере объединения нескольких локальных сетей. Сетевой уровень решает также задачи согласования разных технологий, упрощения адресации в крупных сетях и создания надежных и гибких барьеров на пути нежелательного трафика между сетями.
Сообщения сетевого уровня принято называть пакетами (packets). При организации доставки пакетов на сетевом уровне используется понятие «номер сети». В этом случае адрес получателя состоит из старшей части - номера сети и младшей - номера узла в этой сети. Все узлы одной сети должны иметь одну и ту же старшую часть адреса, поэтому термину «сеть» на сетевом уровне можно дать и другое, более формальное определение: сеть - это совокупность узлов, сетевой адрес которых содержит один и тот же номер сети.
На сетевом уровне определяются два вида протоколов. Первый вид - сетевые протоколы (routed protocols) - реализуют продвижение пакетов через сеть. Именно эти протоколы обычно имеют в виду, когда говорят о протоколах сетевого уровня. Однако часто к сетевому уровню относят и другой вид протоколов, называемых протоколами обмена маршрутной информацией или просто протоколами маршрутизации (routing protocols). С помощью этих протоколов маршрутизаторы собирают информацию о топологии межсетевых соединений. Протоколы сетевого уровня реализуются программными модулями операционной системы, а также программными и аппаратными средствами маршрутизаторов.
Примерами протоколов сетевого уровня являются протокол межсетевого взаимодействия IP стека TCP/IP и протокол межсетевого обмена пакетами IPX стека Novell.
Транспортный уровень. На пути от отправителя к получателю пакеты могут быть искажены или утеряны. Хотя некоторые приложения имеют собственные средства обработки ошибок, существуют и такие, которые предпочитают сразу иметь дело с надежным соединением. Транспортный уровень (Transport layer) обеспечивает приложениям или верхним уровням стека - прикладному и сеансовому - передачу данных с той степенью надежности, которая им требуется. Модель OSI определяет пять классов сервиса, предоставляемых транспортным уровнем. Эти виды сервиса отличаются качеством предоставляемых услуг: срочностью, возможностью восстановления прерванной связи, наличием средств мультиплексирования нескольких соединений между различными прикладными протоколами через общий транспортный протокол, а главное - способностью к обнаружению и исправлению ошибок передачи, таких как искажение, потеря и дублирование пакетов.
Выбор класса сервиса транспортного уровня определяется, с одной стороны, тем, в какой степени задача обеспечения надежности решается самими приложениями и протоколами более высоких, чем транспортный, уровней, а с другой стороны, этот выбор зависит от того, насколько надежной является система транспортировки данных в сети, обеспечиваемая уровнями, расположенными ниже транспортного - сетевым, канальным и физическим. Так, например, если качество каналов передачи связи очень высокое и вероятность возникновения ошибок, не обнаруженных протоколами более низких уровней, невелика, то разумно воспользоваться одним из облегченных сервисов транспортного уровня, не обремененных многочисленными проверками, квитированием и другими приемами повышения надежности. Если же транспортные средства нижних уровней изначально очень ненадежны, то целесообразно обратиться к наиболее развитому сервису транспортного уровня, который работает, используя максимум средств для обнаружения и устранения ошибок, - с помощью предварительного установления логического соединения, контроля доставки сообщений по контрольным суммам и циклической нумерации пакетов, установления тайм-аутов доставки и т. п.
Как правило, все протоколы, начиная с транспортного уровня и выше, реализуются программными средствами конечных узлов сети - компонентами их сетевых операционных систем. В качестве примера транспортных протоколов можно привести протоколы TCP и UDP стека TCP/IP и протокол SPX стека Novell. Протоколы нижних четырех уровней обобщенно называют сетевым транспортом или транспортной подсистемой, так как они полностью решают задачу транспортировки сообщений с заданным уровнем качества в составных сетях с произвольной топологией и различными технологиями. Остальные три верхних уровня решают задачи предоставления прикладных сервисов на основании имеющейся транспортной подсистемы.
Сеансовый уровень. Сеансовый уровень (Session layer) обеспечивает управление диалогом: фиксирует, какая из сторон является активной в настоящий момент, предоставляет средства синхронизации. Последние позволяют вставлять контрольные точки в длинные передачи, чтобы в случае отказа можно было вернуться назад к последней контрольной точке, а не начинать все с начала. На практике немногие приложения используют сеансовый уровень, и он редко реализуется в виде отдельных протоколов, хотя функции этого уровня часто объединяют с функциями прикладного уровня и реализуют в одном протоколе.
Представительный уровень. Представительный уровень (Presentation layer) имеет дело с формой представления передаваемой по сети информации, не меняя при этом ее содержания. За счет уровня представления информация, передаваемая прикладным уровнем одной системы, всегда понятна прикладному уровню другой системы. С помощью средств данного уровня протоколы прикладных уровней могут преодолеть синтаксические различия в представлении данных или же различия в кодах символов, например кодов ASCII и EBCDIC. На этом уровне может выполняться шифрование и дешифрование данных, благодаря которому секретность обмена данными обеспечивается сразу для всех прикладных служб. Примером такого протокола является протокол Secure Socket Layer (SSL), который обеспечивает секретный обмен сообщениями для протоколов прикладного уровня стека TCP/IP.
Прикладной уровень. Прикладной уровень (Application layer) - это в действительности просто набор разнообразных протоколов, с помощью которых пользователи сети получают доступ к разделяемым ресурсам, таким как файлы, принтеры или гипертекстовые Web-страницы, а также организуют свою совместную работу, например, с помощью протокола электронной почты. Единица данных, которой оперирует прикладной уровень, обычно называется сообщением (message).
Существует очень большое разнообразие служб прикладного уровня. Приведем в качестве примера хотя бы несколько наиболее распространенных реализации файловых служб: NCP в операционной системе Novell NetWare, SMB в Microsoft Windows NT, NFS, FTP и TFTP, входящие в стек TCP/IP.
Структура стека протоколов TCP/IP и протокол межсетевого взаимодействия IP
Transmission Control Protocol/Internet Protocol (TCP/IP) - это промышленный стандарт стека протоколов, разработанный для глобальных сетей.
Стандарты TCP/IP опубликованы в серии документов, названных Request for Comment (RFC). Документы RFC описывают внутреннюю работу сети Internet. Некоторые RFC описывают сетевые сервисы или протоколы и их реализацию, в то время как другие обобщают условия применения. Стандарты TCP/IP всегда публикуются в виде документов RFC, но не все RFC определяют стандарты.
Стек был разработан по инициативе Министерства обороны США (Department of Defence, DoD) более 20 лет назад для связи экспериментальной сети ARPAnet с другими сателлитными сетями как набор общих протоколов для разнородной вычислительной среды. Сеть ARPA поддерживала разработчиков и исследователей в военных областях. В сети ARPA связь между двумя компьютерами осуществлялась с использованием протокола Internet Protocol (IP), который и по сей день является одним из основных в стеке TCP/IP и фигурирует в названии стека.
Большой вклад в развитие стека TCP/IP внес университет Беркли, реализовав протоколы стека в своей версии ОС UNIX. Широкое распространение ОС UNIX привело и к широкому распространению протокола IP и других протоколов стека. На этом же стеке работает всемирная информационная сеть Internet, чье подразделение Internet Engineering Task Force (IETF) вносит основной вклад в совершенствование стандартов стека, публикуемых в форме спецификаций RFC.
Если в настоящее время стек TCP/IP распространен в основном в сетях с ОС UNIX, то реализация его в последних версиях сетевых операционных систем для персональных компьютеров (Windows NT 3.5, NetWare 4.1, Windows 95) является хорошей предпосылкой для быстрого роста числа установок стека TCP/IP.
Итак, лидирующая роль стека TCP/IP объясняется следующими его свойствами:
Это наиболее завершенный стандартный и в то же время популярный стек сетевых протоколов, имеющий многолетнюю историю.
Почти все большие сети передают основную часть своего трафика с помощью протокола TCP/IP.
Это метод получения доступа к сети Internet.
Этот стек служит основой для создания intranet- корпоративной сети, использующей транспортные услуги Internet и гипертекстовую технологию WWW, разработанную в Internet.
Все современные операционные системы поддерживают стек TCP/IP.
Это гибкая технология для соединения разнородных систем как на уровне транспортных подсистем, так и на уровне прикладных сервисов.
Это устойчивая масштабируемая межплатформенная среда для приложений клиент-сервер.
Данный стек протоколов TCP/IP был разработан раньше утверждения модели открытых систем, поэтому число уровней управления в стеке TCP/IP отличаются от OSI-4.

Рис. 13.1. Структура стека протоколов TCP/IP
Уровень межсетевого взаимодействия. Стержнем всей архитектуры является уровень межсетевого взаимодействия, или сетевой уровень, который реализует концепцию передачи пакетов в режиме без установления соединений, то есть дейтаграммным способом. Именно этот уровень обеспечивает возможность перемещения пакетов по сети, используя тот маршрут, который в данный момент является наиболее рациональным. Этот уровень также называют уровнем internet, указывая, тем самым, на основную его функцию - передачу данных через составную сеть.
Основным протоколом уровня (в терминологии модели OSI) в стеке TCP/IP является протокол IP. Этот протокол изначально проектировался как протокол передачи пакетов в составных сетях, состоящих из большого количества локальных сетей, объединенных как локальными, так глобальными связями. Поэтому протокол IP хорошо работает в сетях со множеством топологий, рационально используя наличие в них подсистем и экономно расходуя пропускную способность низкоскоростных линий связи. Так как протокол IP является дейтаграммным протоколом, он не гарантирует доставку пакетов до узла назначения, но старается это сделать.
К уровню межсетевого взаимодействия относятся все протоколы, связанные с состоянием и модификацией таблиц маршрутизации, такие как протоколы сбора маршрутной информации RIP и OSPF, а также протокол межсетевых управляющих сообщений ICMP. Последний протокол предназначен для обмена информацией об ошибках между маршрутизаторами сети и удаленным источником пакета. С помощью специальных пакетов ICMP сообщает о невозможности доставки пакета, о превышении времени жизни или продолжительности сборки пакета из фрагментов, об аномальных величинах параметров, об изменении маршрута пересылки и типа обслуживания, о состоянии системы и т. п.
Основной уровень. Поскольку на сетевом уровне не устанавливается соединение, то нет никаких гарантий того, что все пакеты будут доставлены в место назначения целыми и невредимыми или придут в том же порядке, в котором они были отправлены. Эту задачу - обеспечение надежности информационной связи между двумя конечными узлами - решает основной уровень стека TCP/IP, называемый также транспортным.
На этом уровне функционируют протокол управления передачей TCP и протокол дейтаграмм пользователя UDP. Протокол TCP обеспечивает надежную передачу сообщений между удаленными прикладными процессами за счет образования логических соединений. Этот протокол позволяет равноранговым объектам на компьютере-отправителе и на компьютере-получателе поддерживать обмен данными в дуплексном режиме. TCP позволяет без ошибок доставлять сформированный на одном из компьютеров поток байт в любой другой компьютер, входящий в составную сеть. TCP делит поток байт на части - сегменты и передает их нижележащему уровню межсетевого взаимодействия. После того, как эти сегменты будут доставлены в пункт назначения, протокол TCP снова соберет их в непрерывный поток байт.
Протокол UDP обеспечивает передачу прикладных пакетов дейтаграммным способом, как и главный протокол уровня межсетевого взаимодействия IP, и выполняет только функции связующего звена (мультиплексора) между сетевым протоколом и многочисленными системами прикладного уровня, или пользовательскими процессами.
Прикладной уровень. Прикладной уровень объединяет все службы, представляемые системой пользовательским приложениям. За долгие годы использования в сетях различных стран и организаций стек TCP/IP накопил большое число протоколов и служб прикладного уровня. Прикладной уровень реализуется программными системами, построенными в архитектуре клиент-сервер, базирующейся на протоколах нижних уровней.
В отличие от протоколов остальных трех уровней, протоколы прикладного уровня занимаются деталями конкретного приложения и "не интересуются" способами передачи данных по сети. Этот уровень постоянно расширяется за счет присоединения к старым, прошедшим многолетнюю эксплуатацию сетевым службам типа Telnet, FTP, TFTP, DNS, SNMP, сравнительно новых служб, таких, например, как протокол передачи гипертекстовой информации HTTP.
Уровень межкомпьютерного взаимодействия. Идеологическим отличием архитектуры стека TCP/IP от многоуровневой организации других стеков является интерпретация функций самого нижнего уровня – уровня сетевых интерфейсов. Протоколы этого уровня должны обеспечивать интеграцию в составную сеть других сетей, причем задача ставится так: сеть TCP/IP должна иметь средства включения в себя любой другой сети, какую бы внутреннюю технологию передачи данных эта сеть не использовала. Отсюда следует, что этот уровень нельзя определить раз и навсегда. Для каждой технологии, включаемой в составную сеть подсети, должны быть разработаны собственные интерфейсные средства. К таким интерфейсным средствам относится протокол инкапсуляции IP-пакетов межсетевого взаимодействия в кадры локальных технологий.
Уровень сетевых интерфейсов в протоколах TCP/IP не регламентируется, но он поддерживает все популярные стандарты физического и канального уровней: для локальных сетей - это Ethernet, Token Ring, FDDI, Fast Ethernet, Gigabit Ethernet, 100VG-AnyLAN, для глобальных сетей - протоколы соединений "точка-точка" SLIP и PPP, протоколы территориальных сетей с коммутацией пакетов X.25, frame relay. Разработана также специальная спецификация, определяющая использование технологии ATM в качестве транспорта канального уровня.
Основные протоколы:
SNMP – простой протокол управления сетью;
Telnet – протокол удалённого терминала;
FTP – протокол передачи файлов;
SMTP – простой протокол электронной почты;
TFTP – тривиальный протокол передачи файлов;
SFTP – простой протокол передачи файлов;
NFS – управление файловой системы;
TCP – протокол управления передачей по виртуальному каналу;
UDP – пользовательский протокол передачи данных, датаграммы;
IP – протокол межсетевой передачи пакетов;
ICMP – протокол управления сообщениями;
RIP – протокол обмена маршрутной информацией и формирование таблиц маршрута;
OSPF – протокол формирования таблиц маршрутов;
ARP – по IP-адресу назначает MAC-адрес;
RARP – по MAC-адресу назначает IP-адрес.
Модель взаимодействия протоколов стека TCP/IP.
Схема взаимодействия протоколов показана на рис. 13.2.

Рис. 13.2. Схема взаимодействия протоколов
Рассмотрим потоки данных, проходящие через стек. В случае использования протокола TCP, данные передаются между прикладным процессом и модулем TCP. Типичным прикладным процессом, использующим протокол TCP, является модуль FTP. Стек протоколов в этом случае будет FTP/TCP/IP/Ethernet. При использовании протокола UDP, данные передаются между прикладным процессом и модулем UDP. Например, SNMP пользуется транспортными услугами UDP. Его стек протоколов выглядит так: SNMP/UDP/IP/Ethernet.
Модули TCP, UDP и драйвер Ethernet являются мультиплексорами n x 1. Действуя как мультиплексоры, они переключают несколько входов на один выход. Они также являются демультиплексорами 1 x n. Как демультиплексоры, они переключают один вход на один из многих выходов в соответствии с полем типа в заголовке протокольного блока данных. Другими словами, происходит следующее:
Когда Ethernet-кадр попадает в драйвер сетевого интерфейса Ethernet, он может быть направлен либо в модуль ARP, либо в модуль IP. На то, куда должен быть направлен Ethernet-кадр, указывает значение поля типа в заголовке кадра.
Если IP-пакет попадает в модуль IP, то содержащиеся в нем данные могут быть переданы либо модулю TCP, либо UDP, что определяется полем "протокол" в заголовке IP-пакета.
Если UDP-датаграмма попадает в модуль UDP, то на основании значения поля "порт" в заголовке датаграммы определяется прикладная программа, которой должно быть передано прикладное сообщение.
Если TCP-сообщение попадает в модуль TCP, то выбор прикладной программы, которой должно быть передано сообщение, осуществляется на основе значения поля "порт" в заголовке TCP-сообщения.
Мультиплексирование данных в обратную сторону осуществляется довольно просто, так как из каждого модуля существует только один путь вниз. Каждый протокольный модуль добавляет к пакету свой заголовок, на основании которого машина, принявшая пакет, выполняет демультиплексирование.
Протокол межсетевого взаимодействия IP.V4.
Основу транспортных средств стека протоколов TCP/IP составляет протокол межсетевого взаимодействия - IP (Internet Protocol). К основным функциям протокола IP относятся:
перенос между сетями различных типов адресной информации в унифицированной форме;
сборка и разборка пакетов при передаче их между сетями с различным максимальным значением длины пакета.
Формат пакета ip
Стандартом IP определен формат пакета:
|
0 3 |
4 7 |
8 15 |
16 31 | |||
|
Версия |
Длина заголовка пакета |
Тип сервиса |
Длина полного пакета (в байтах) | |||
|
Идентификатор пакета |
Поле управления флагов |
Смещение фрагмента | ||||
|
Время жизни дейтаграммы |
Идентификатор протокола верхнего уровня |
Контрольная сумма заголовка | ||||
|
Адрес источника | ||||||
|
Адрес получателя | ||||||
|
Дополнительные услуги / заполнитель | ||||||
|
Текст межсетевой дейтаграммы | ||||||
Длина заголовка в кол-ве 32-разрядных слов.
Тип сервиса:
|
0 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
|
Приоритет |
D |
T |
R |
0 |
0 | ||
Приоритет: 111 – сетевая управляющая информация;
110 – межсетевая управляющая информация;
101 – критическая информация;
100 – сверхмолния;
011 – молния;
010 – срочная информация;
001 – приоритетная информация;
000 – обычная информация.
Д – бит задержки: 0 – нормальная, 1 – низкая.
Т – требуемая производительность: 1 – высокая, 0 – нормальная.
R – требуемая надёжность: 1 – высокая, 0 – нормальная.
Идентификатор пакета используется при фрагментации.
Поле управляющих флагов:
|
0 |
DF |
MF |
MF – признак продолжения фрагментации;
DF – признак разрешения фрагментации.
Пакет IP состоит из заголовка и поля данных. Заголовок пакета имеет следующие поля:
Поле Номер версии (VERS) указывает версию протокола IP. Сейчас повсеместно используется версия 4 и готовится переход на версию 6, называемую также IPng (IP next generation).
Поле Длина заголовка (HLEN) пакета IP занимает 4 бита и указывает значение длины заголовка, измеренное в 32-битовых словах. Обычно заголовок имеет длину в 20 байт (пять 32-битовых слов), но при увеличении объема служебной информации эта длина может быть увеличена за счет использования дополнительных байт в поле Резерв (IP OPTIONS).
Поле Тип сервиса (SERVICE TYPE) занимает 1 байт и задает приоритетность пакета и вид критерия выбора маршрута. Первые три бита этого поля образуют подполе приоритета пакета (PRECEDENCE). Приоритет может иметь значения от 0 (нормальный пакет) до 7 (пакет управляющей информации). Маршрутизаторы и компьютеры могут принимать во внимание приоритет пакета и обрабатывать более важные пакеты в первую очередь. Поле Тип сервисасодержит также три бита, определяющие критерий выбора маршрута. Установленный бит D (delay) говорит о том, что маршрут должен выбираться для минимизации задержки доставки данного пакета, бит T - для максимизации пропускной способности, а бит R - для максимизации надежности доставки.
Поле Общая длина (TOTAL LENGTH) занимает 2 байта и указывает общую длину пакета с учетом заголовка и поля данных.
Поле Идентификатор пакета (IDENTIFICATION) занимает 2 байта и используется для распознавания пакетов, образовавшихся путем фрагментации исходного пакета. Все фрагменты должны иметь одинаковое значение этого поля.
Поле Флаги (FLAGS) занимает 3 бита, оно указывает на возможность фрагментации пакета (установленный бит Do not Fragment - DF - запрещает маршрутизатору фрагментировать данный пакет), а также на то, является ли данный пакет промежуточным или последним фрагментом исходного пакета (установленный бит More Fragments - MF - говорит о том пакет переносит промежуточный фрагмент).
Поле Смещение фрагмента (FRAGMENT OFFSET) занимает 13 бит, оно используется для указания в байтах смещения поля данных этого пакета от начала общего поля данных исходного пакета, подвергнутого фрагментации. Используется при сборке/разборке фрагментов пакетов при передачах их между сетями с различными величинами максимальной длины пакета.
Поле Время жизни (TIME TO LIVE) занимает 1 байт и указывает предельный срок, в течение которого пакет может перемещаться по сети. Время жизни данного пакета измеряется в секундах и задается источником передачи средствами протокола IP. На шлюзах и в других узлах сети по истечении каждой секунды из текущего времени жизни вычитается единица; единица вычитается также при каждой транзитной передаче (даже если не прошла секунда). При истечении времени жизни пакет аннулируется.
Идентификатор Протокола верхнего уровня (PROTOCOL) занимает 1 байт и указывает, какому протоколу верхнего уровня принадлежит пакет (например, это могут быть протоколы TCP, UDP или RIP).
Контрольная сумма (HEADER CHECKSUM) занимает 2 байта, она рассчитывается по всему заголовку.
Поля Адрес источника (SOURCE IP ADDRESS) и Адрес назначения (DESTINATION IP ADDRESS) имеют одинаковую длину - 32 бита, и одинаковую структуру.
Поле Резерв (IP OPTIONS) является необязательным и используется обычно только при отладке сети. Это поле состоит из нескольких подполей, каждое из которых может быть одного из восьми предопределенных типов. В этих подполях можно указывать точный маршрут прохождения маршрутизаторов, регистрировать проходимые пакетом маршрутизаторы, помещать данные системы безопасности, а также временные отметки. Так как число подполей может быть произвольным, то в конце поля Резерв должно быть добавлено несколько байт для выравнивания заголовка пакета по 32-битной границе.
Максимальная длина поля данных пакета ограничена разрядностью поля, определяющего эту величину, и составляет 65535 байтов, однако при передаче по сетям различного типа длина пакета выбирается с учетом максимальной длины пакета протокола нижнего уровня, несущего IP-пакеты. Если это кадры Ethernet, то выбираются пакеты с максимальной длиной в 1500 байтов, умещающиеся в поле данных кадра Ethernet.
Адресация в IP-сетях. Особенности протокола IP.V6
Каждый компьютер в сети TCP/IP имеет адреса трех уровней:
Локальный адрес узла, определяемый технологией, с помощью которой построена отдельная сеть, в которую входит данный узел. Для узлов, входящих в локальные сети - это МАС-адрес сетевого адаптера или порта маршрутизатора, например, 11-А0-17-3D-BC-01. Эти адреса назначаются производителями оборудования и являются уникальными адресами, так как управляются централизовано. Для всех существующих технологий локальных сетей МАС-адрес имеет формат 6 байтов: старшие 3 байта - идентификатор фирмы производителя, а младшие 3 байта назначаются уникальным образом самим производителем. Для узлов, входящих в глобальные сети, такие как Х.25 или frame relay, локальный адрес назначается администратором глобальной сети.
IP-адрес, состоящий из 4 байт, например, 109.26.17.100. Этот адрес используется на сетевом уровне. Он назначается администратором во время конфигурирования компьютеров и маршрутизаторов. IP-адрес состоит из двух частей: номера сети и номера узла. Номер сети может быть выбран администратором произвольно, либо назначен по рекомендации специального подразделения Internet NIC (Network Information Center), если сеть должна работать как составная часть Internet. Обычно провайдеры услуг Internet получают диапазоны адресов у подразделений INIC, а затем распределяют их между своими абонентами.
Номер узла в протоколе IP назначается независимо от локального адреса узла. Деление IP-адреса на поле номера сети и номера узла - гибкое, и граница между этими полями может устанавливаться весьма произвольно. Узел может входить в несколько IP-сетей. В этом случае узел должен иметь несколько IP-адресов, по числу сетевых связей. Таким образом, IP-адрес характеризует не отдельный компьютер или маршрутизатор, а одно сетевое соединение.
Символьный идентификатор-имя, например, SERV1.IBM.COM. Этот адрес назначается администратором и состоит из нескольких частей, например, имени машины, имени организации, имени домена. Такой адрес, называемый также DNS-именем, используется на прикладном уровне, например, в протоколах FTP или telnet.
IP-адрес имеет длину 4 байта и обычно записывается в виде четырех чисел, представляющих значения каждого байта в десятичной форме, и разделенных точками, например:
128.10.2.30 - традиционная десятичная форма представления адреса, 10000000 00001010 00000010 00011110 - двоичная форма представления этого же адреса.
В таблице 4 представлена структура IP-адреса.
Табл.4. Структура IP-адреса.
|
Класс А |
0 |
N сети |
N узла | |||
|
Класс В |
1 0 |
N сети |
N узла | |||
|
Класс С |
1 1 0 |
N сети |
N узла | |||
|
Класс D |
1 1 1 0 |
адрес группы multicast | ||||
|
Класс Е |
1 1 1 1 0 |
зарезервирован | ||||
Адрес состоит из двух логических частей - номера сети и номера узла в сети. Какая часть адреса относится к номеру сети, а какая к номеру узла, определяется значениями первых битов адреса:
Если адрес начинается с 0, то сеть относят к классу А, и номер сети занимает один байт, остальные 3 байта интерпретируются как номер узла в сети. Сети класса А имеют номера в диапазоне от 1 до 126. (Номер 0 не используется, а номер 127 зарезервирован для специальных целей, о чем будет сказано ниже.) В сетях класса А количество узлов должно быть больше 216 , но не превышать 224.
Если первые два бита адреса равны 10, то сеть относится к классу В и является сетью средних размеров с числом узлов 28 - 216. В сетях класса В под адрес сети и под адрес узла отводится по 16 битов, то есть по 2 байта.
Если адрес начинается с последовательности 110, то это сеть класса С с числом узлов не больше 28. Под адрес сети отводится 24 бита, а под адрес узла - 8 битов.
Если адрес начинается с последовательности 1110, то он является адресом класса D и обозначает особый, групповой адрес - multicast. Если в пакете в качестве адреса назначения указан адрес класса D, то такой пакет должны получить все узлы, которым присвоен данный адрес.
Если адрес начинается с последовательности 11110, то это адрес класса Е, он зарезервирован для будущих применений.
В следующей таблице приведены диапазоны номеров сетей, соответствующих каждому классу сетей.
Табл.5. Диапазоны номеров в классах A-E.
|
Класс |
Наименьший адрес |
Наибольший адрес |
|
A |
01.0.0.0 |
126.0.0.0 |
|
B |
128.0.0.0 |
191.255.0.0 |
|
C |
192.0.1.0 |
223.255.255.0 |
|
D |
224.0.0.0 |
239.255.255.255 |
|
E |
240.0.0.0 |
247.255.255.255 |
В протоколе IP существует несколько соглашений об особой интерпретации некоторых IP-адресов:
если IР-адрес состоит только из двоичных нулей,
0 0 0 0 ..................................... 0
то он обозначает адрес того узла, который сгенерировал этот пакет;
если в поле номера сети стоят 0,
0 0 0 0 ................. 0
Номер узла
то по умолчанию считается, что этот узел принадлежит той же самой сети, что и узел, который отправил пакет;
если все двоичные разряды IP-адреса равны 1,
1 1 1 1 ..................................... 1
то пакет с таким адресом назначения должен рассылаться всем узлам, находящимся в той же сети, что и источник этого пакета. Такая рассылка называется ограниченным широковещательным сообщением (limited broadcast);
если в поле адреса назначения стоят сплошные 1,
Номер сети
1 1 1 1 ................ 1
то пакет, имеющий такой адрес рассылается всем узлам сети с заданным номером. Такая рассылка называется широковещательным сообщением (broadcast);
адрес 127.0.0.1 зарезервирован для организации обратной связи при тестировании работы программного обеспечения узла без реальной отправки пакета по сети. Этот адрес имеет название loopback.
Уже упоминавшаяся форма группового IP-адреса - multicast - означает, что данный пакет должен быть доставлен сразу нескольким узлам, которые образуют группу с номером, указанным в поле адреса. Узлы сами идентифицируют себя, то есть определяют, к какой из групп они относятся. Один и тот же узел может входить в несколько групп. Такие сообщения в отличие от широковещательных называются мультивещательными. Групповой адрес не делится на поля номера сети и узла и обрабатывается маршрутизатором особым образом.
В протоколе IP нет понятия широковещательности в том смысле, в котором оно используется в протоколах канального уровня локальных сетей, когда данные должны быть доставлены абсолютно всем узлам. Как ограниченный широковещательный IP-адрес, так и широковещательный IP-адрес имеют пределы распространения в интерсети - они ограничены либо сетью, к которой принадлежит узел - источник пакета, либо сетью, номер которой указан в адресе назначения. Поэтому деление сети с помощью маршрутизаторов на части локализует широковещательный шторм пределами одной из составляющих общую сеть частей просто потому, что нет способа адресовать пакет одновременно всем узлам всех сетей составной сети.
Маршрутизация пакетов с помощью IP-адресов.
Рассмотрим теперь принципы, на основании которых в сетях IP происходит выбор маршрута передачи пакета между сетями.
В стеке TCP/IP маршрутизаторы и конечные узлы принимают решения о том, кому передавать пакет для его успешной доставки узлу назначения, на основании так называемых таблиц маршрутизации (routing tables).
Следующая таблица представляет собой типичный пример таблицы маршрутов, использующей IP-адреса сетей:
Табл.8. Пример таблицы маршрутов.
|
Адрес сети назначения |
Адрес следующего маршрутизатора |
Номер выходного порта |
Расстояние до сети назначения |
|
56.0.0.0 |
198.21.17.7 |
1 |
20 |
|
56.0.0.0 |
213.34.12.4 |
2 |
130 |
|
116.0.0.0 |
213.34.12.4 |
2 |
1450 |
|
129.13.0.0 |
198.21.17.6 |
1 |
50 |
|
198.21.17.0 |
- |
2 |
0 |
|
213.34.12.0 |
- |
1 |
0 |
|
default |
198.21.17.7 |
1 |
- |
В этой таблице в столбце "Адрес сети назначения" указываются адреса всех сетей, которым данный маршрутизатор может передавать пакеты. В стеке TCP/IP принят так называемый одношаговый подход к оптимизации маршрута продвижения пакета (next-hop routing) - каждый маршрутизатор и конечный узел принимает участие в выборе только одного шага передачи пакета. Поэтому в каждой строке таблицы маршрутизации указывается не весь маршрут в виде последовательности IP-адресов маршрутизаторов, через которые должен пройти пакет, а только один IP-адрес - адрес следующего маршрутизатора, которому нужно передать пакет. Вместе с пакетом следующему маршрутизатору передается ответственность за выбор следующего шага маршрутизации. Одношаговый подход к маршрутизации означает распределенное решение задачи выбора маршрута. Это снимает ограничение на максимальное количество транзитных маршрутизаторов на пути пакета.
(Альтернативой одношаговому подходу является указание в пакете всей последовательности маршрутизаторов, которые пакет должен пройти на своем пути. Такой подход называется маршрутизацией от источника - Source Routing. В этом случае выбор маршрута производится конечным узлом или первым маршрутизатором на пути пакета, а все остальные маршрутизаторы только отрабатывают выбранный маршрут, осуществляя коммутацию пакетов, то есть передачу их с одного порта на другой. Алгоритм Source Routing применяется в сетях IP только для отладки, когда маршрут задается в поле Резерв (IP OPTIONS) пакета.)
В случае, если в таблице маршрутов имеется более одной строки, соответствующей одному и тому же адресу сети назначения, то при принятии решения о передаче пакета используется та строка, в которой указано наименьшее значение в поле "Расстояние до сети назначения".
При этом под расстоянием понимается любая метрика, используемая в соответствии с заданным в сетевом пакете классом сервиса. Это может быть количество транзитных маршрутизаторов в данном маршруте (количество хопов от hop - прыжок), время прохождения пакета по линиям связи, надежность линий связи, или другая величина, отражающая качество данного маршрута по отношению к конкретному классу сервиса. Если маршрутизатор поддерживает несколько классов сервиса пакетов, то таблица маршрутов составляется и применяется отдельно для каждого вида сервиса (критерия выбора маршрута).
Для отправки пакета следующему маршрутизатору требуется знание его локального адреса, но в стеке TCP/IP в таблицах маршрутизации принято использование только IP-адресов для сохранения их универсального формата, не зависящего от типа сетей, входящих в интерсеть. Для нахождения локального адреса по известному IP-адресу необходимо воспользоваться протоколом ARP (как это происходит, мы рассмотрели в предыдущей главе).
Конечный узел, как и маршрутизатор, имеет в своем распоряжении таблицу маршрутов унифицированного формата и на основании ее данных принимает решение, какому маршрутизатору нужно передавать пакет для сети N. Решение о том, что этот пакет нужно вообще маршрутизировать, компьютер принимает в том случае, когда он видит, что адрес сети назначения пакета отличается от адреса его собственной сети (каждому компьютеру при конфигурировании администратор присваивает его IP-адрес или несколько IP-адресов, если компьютер одновременно подключен к нескольким сетям).
Одношаговая маршрутизация обладает еще одним преимуществом - она позволяет сократить объем таблиц маршрутизации в конечных узлах и маршрутизаторах за счет использования в качестве номера сети назначения так называемого маршрута по умолчанию – default, который обычно занимает в таблице маршрутизации последнюю строку. Если в таблице маршрутизации есть такая запись, то все пакеты с номерами сетей, которые отсутствуют в таблице маршрутизации, передаются маршрутизатору, указанному в строке default. Поэтому маршрутизаторы часто хранят в своих таблицах ограниченную информацию о сетях интерсети, пересылая пакеты для остальных сетей в порт и маршрутизатор, используемые по умолчанию. Подразумевается, что последние передадут пакет на магистральную сеть, а маршрутизаторы, подключенные к магистрали, имеют полную информацию о составе интерсети.
Другим способом разгрузки компьютера от необходимости ведения больших таблиц маршрутизации является получение от маршрутизатора сведений о рациональном маршруте для какой-нибудь конкретной сети с помощью протоколаICMP.
Кроме маршрута default, в таблице маршрутизации могут встретиться два типа специальных записей - запись о специфичном для узла маршруте и запись об адресах сетей, непосредственно подключенных к портам маршрутизатора.
Специфичный для узла маршрут содержит вместо номера сети полный IP-адрес, то есть адрес, имеющий ненулевую информацию не только в поле номера сети, но и в поле номера узла. Предполагается, что для такого конечного узла маршрут должен выбираться не так, как для всех остальных узлов сети, к которой он относится. В случае, когда в таблице есть разные записи о продвижении пакетов для всей сети N и ее отдельного узла, имеющего адрес N,D, при поступлении пакета, адресованного узлу N,D, маршрутизатор отдаст предпочтение записи для N,D.
Записи в таблице маршрутизации, относящиеся к сетям, непосредственно подключенным к маршрутизатору, в поле "Расстояние до сети назначения" содержат нули.
Особенности протокола IP.V6.
Интернет-протокол версии 6 (IPv6) представляет сетевой слой пакетной передачи данных между сетями. Он разрабатывается в качестве преемника IPv4, текущей версии интернет-протокола для общего использования в Интернете.
Основным отличием IPv6 является гораздо большее адресное пространство, что добавляет большую гибкость при распределении адресов. Увеличенная длина адреса позволяет отказаться от использования NAT (network address translation), что позволяет избежать нехватки интернет-адресов, а также упрощает назначения адресов и нумерации при смене интернет-провайдера.
Адресное пространство IPv6 по настоящему огромно. IPv6 поддерживает 2128 (примерно 3,4x1038 адресов). Таким образом на каждого из 6,5 миллиардов жителей Земли приходится по 5x1028 (около 295) адресов. Т.е. более чем в десять миллиардов миллиардов миллиардов раз больше адресов, чем поддерживает IPv4.
Большое число адресов позволяет использовать иерархическое распределение адресов, упрощая маршрутизацию. В IPv6 изменение нумерации осуществляется практически автоматически, поскольку идентификатор узла (хоста) отделен от идентификатора сети провайдера. Разделение адресных пространств провайдеров и узлов добавляет "неэффективные" биты в адресное пространство, однако чрезвычайно эффективно для решения оперативных вопросов, таких как изменение сервис-провайдера.
Главное отличие IPv6 от IPv4 - длина сетевых адресов. IPv6-адреса имеют длину128 (так определено в RFC 4291), в то время IPv4-адреса всего 32 бита. Таким образом адресное пространство IPv4 содержит около 4 млрд. адресов, IPv6имеет 3,4 × 10^38 уникальных адресов.
Как правило адрес IPv6 состоит из двух логических частей: 64-битного префикса (под-)сети и 64-битного адреса узла, который либо автоматически генерируется на основе MAC-адреса или устанавливается вручную. Так как уникальный во всем мире MAC-адрес позволяет отслеживать пользователей оборудования, то в IPv6 были внесены изменения (RFC 3041) с возможности отключения постоянной привязки оборудования к IPv6 адресу. Таким образом, удалось восстановить некоторые возможности анонимности, существующие в IPv4. RFC 3041 определяет механизм, с помощью которого, вместо MAC-адресов могут быть использованы случайные битовые строки.
Адреса IPv6, как правило, записываются в виде восьми групп по четыре шестнадцатеричные цифры, где каждая группа разделяется двоеточием (:). Например, 2001:0db8:85a3:08d3:1319:8a2e:0370:7334 является IPv6-адресом.
Если одна или несколько из четырех групп цифр нули (0000), они могут быть опущены и заменены двумя двоеточиями (::). Например, 2001:0db8:0000:0000:0000:0000:1428:57ab может быть сокращен до 2001:0db8::1428:57. В соответствии с этим правилом, любое число последовательных 0000-групп может быть сокращены до двух двоеточий, до тех пор, пока существует только одно двойное двоеточие. Ведущие нули в группе могут быть опущены (например ::1 для localhost). Таким образом, следующие адреса правильны и идентичны:
2001:0db8:0000:0000:0000:0000:1428:57ab
2001:0db8:0000:0000:0000::1428:57ab
2001:0db8:0:0:0:0:1428:57ab
2001:0db8:0:0::1428:57ab
2001:0db8::1428:57ab
2001:db8::1428:57ab
Адрес с двумя двойными двоеточиями является недействительным, поскольку создает двусмысленность в нотации. Например, сократив 2001:0000:0000:FFD3:0000:0000:0000:57ab до 2001::FFD3::57ab мы получим возможные комбинации: 2001:0000:0000:0000:0000:FFD3:0000:57ab, 2001:0000:FFD3:0000:0000:0000:0000:57ab и т.д.
Последовательность из 4 байт в конце IPv6-адреса может быть записана в десятичной форме, используя в качестве разделителя точки. Эта нотация часто используется для совместимости с адресами. Кроме того, это решение удобно, когда речь идет о смешанной среде IPv4 и IPv6-адресов. Общее обозначение имеет форму х:х:х:х:х:х:d.d.d.d, где х - 6 групп шестнадцатеричных цифр верхнего октета, а d соответствует десятичным цифрам нижнего октета адреса, поскольку он в формате IPv4. Так, например, ::ffff:12.34.56.78 соответствует ::ffff:0c22:384e или 0:0:0:0:0:ffff:0c22:384e. Следует помнить, что использование данной нотации не рекомендуется и не поддерживается многими приложениями.
IPv6-пакет, состоит из двух основных частей: заголовка и "полезной нагрузки".
Заголовок находится в первых 40 октетах (320 бит) в пакете и содержит поля:
Версия - версии IP (4 бита).
Класс трафика – приоритет пакета (8-бит). Существует два класса: где источник обеспечивает контроль и где источник не обеспечивает контроль трафика.
Метка потока – QoS-менеджмент (20 бит). Первоначально был создан для предоставления специальных сервисов в реальном времени, но в настоящее время не используется.
Длина полезной нагрузки - длина полезной нагрузки в байтах (16 бит). Если заполнена нулями, значит используется Jumbo payload.
Следующий заголовок - определяет следующий инкапсулированный протокол. Значения, совместимы с теми, что определенны для протокола IPv4 (8 бит).
Лимит скачков - заменяет поле time to live в IPv4 (8 бит).
Источник и адрес назначения - 128 бит каждый.
Полезная нагрузка может быть размером до 64 Kб в стандартном режиме, или большего размера в Jumbo payload режиме.
Фрагментация производится только в отправляющем узле IPv6: маршрутизаторы никогда не фрагментируют пакеты, и ожидается, что узлы будут использовать PMTU.
Поле "Протокол" из IPv4 заменяется на поле "Следующий заголовок". Это поле, как правило, определяет уровень транспортного протокола, используемого в "полезной нагрузке".
Отображение IP-адресов на локальные адреса и автоматизация процесса назначения IP-адресов.
Для определения локального адреса по IP-адресу используется протокол разрешения адреса Address Resolution Protocol, ARP. Протокол ARP работает различным образом в зависимости от того, какой протокол канального уровня работает в данной сети - протокол локальной сети (Ethernet, Token Ring, FDDI) с возможностью широковещательного доступа одновременно ко всем узлам сети, или же протокол глобальной сети (X.25, frame relay), как правило не поддерживающий широковещательный доступ.
Функциональность протокола ARP сводится к решению двух задач. Одна часть протокола определяет физические адреса при посылке дейтаграммы, другая отвечает на запросы устройств в сети. Протокол ARP предполагает, что каждое устройство «знает» как свой IP -адрес, так и свой физический адрес.
Для того чтобы уменьшить количество посылаемых запросов ARP , каждое устройство в сети, использующее протокол ARP , должно иметь специальную буферную память. В ней хранятся пары адресов ( IP -адрес, физический адрес) устройств в сети. Всякий раз, когда устройство получает ARP -ответ, оно сохраняет в буферной памяти соответствующую пару. Если адрес есть в списке пар, то нет необходимости посылать ARP -запрос. Эта буферная память называется ARP -таблицей.
В ARP -таблице могут содержаться как статические, так и динамические записи. Динамические записи добавляются и удаляются автоматически, статические заносятся вручную.
Так как большинство устройств в сети поддерживает динамическое разрешение адресов, то администратору, как правило, нет необходимости собственноручно указывать записи протокола ARP в таблице адресов.
Кроме того, ARP -таблица всегда содержит запись с физическим широковещательным адресом ( OxFFFFFFFFFFFF ) для локальной сети. Эта запись позволяет устройству принимать широковещательные ARP -запросы. Каждая запись в ARP -таблице имеет свое время жизни, например для операционной системы Microsoft Windows 2000 оно составляет 10 минут. При добавлении записи для нее активируется таймер. Если запись не востребована в первые две минуты, она удаляется. Если используется — будет существовать на протяжении 10 минут. В некоторых реализациях протокола ARP новый таймер устанавливается после каждого обращения к записи в ARP -таблице.
Сообщения протокола ARP при передаче по сети инкапсулируются в поле данных кадра. Они не содержат IP -заголовка. В отличие от сообщений большинства протоколов, сообщения ARP не имеют фиксированного формата заголовка. Это объясняется тем, что протокол был разработан таким образом, чтобы он был применим для разрешения адресов в различных сетях. Фактически протокол способен работать с произвольными физическими адресами и сетевыми протоколами.
Узел, которому нужно выполнить отображение IP-адреса на локальный адрес, формирует ARP запрос, вкладывает его в кадр протокола канального уровня, указывая в нем известный IP-адрес, и рассылает запрос широковещательно. Все узлы локальной сети получают ARP запрос и сравнивают указанный там IP-адрес с собственным. В случае их совпадения узел формирует ARP-ответ, в котором указывает свой IP-адрес и свой локальный адрес и отправляет его уже направленно, так как в ARP запросе отправитель указывает свой локальный адрес. ARP-запросы и ответы используют один и тот же формат пакета. Так как локальные адреса могут в различных типах сетей иметь различную длину, то формат пакета протокола ARP зависит от типа сети.

Рис. 15.1. Структура пакета ARP.
Обычно IP-адреса хранятся на диске (в конфигурационных файлах), откуда они считываются при загрузке системы. Проблема возникает тогда, когда необходимо инициализировать рабочую станцию, не имеющую диска. Бездисковые системы часто используют операции типа TFTP для переноса из сервера в память образа операционной системы, а это нельзя сделать, не зная IP-адресов сервера и ЭВМ-клиента. Записывать эти адреса в ПЗУ не представляется целесообразным, так как их значения зависят от точки подключения ЭВМ и могут меняться. Для решения данной проблемы был разработан протокол обратной трансляции адресов (RARP – Reverse Address Resolution Protocol, RFC-0903, смотри также ниже описание протокола BOOTP). Форматы сообщений RARP сходны с ARP (см. рис. 5.10), хотя сами протоколы принципиально различны. Протокол RARP предполагает наличие специального сервера, обслуживающего RARPзапросы и хранящего базу данных о соответствии аппаратных адресов протокольным. Этот протокол работает с любой транспортной средой, в случае же кадра Ethernet в поле тип будет записан код 803516.

Рис. 15.2. Структура пакета RARP.
Автоматизация процесса назначения IP-адресов (протокол DHCP).
Протокол динамической конфигурации ЭВМ DHCP (Dynamic Host Configuration Protocol) служит для предоставления конфигурационных параметров ЭВМ, подключенных к Интернет. DHCP имеет два компонента: протокол предоставления специфических для ЭВМ конфигурационных параметров со стороны DHCP-сервера и механизм предоставления ЭВМ сетевых адресов.
DHCP построен по схеме клиентсервер, где DHCP-сервер выделяет сетевые адреса и доставляет конфигурационные параметры динамически конфигурируемым ЭВМ.
DHCP поддерживает три механизма выделения IP-адресов. При автоматическом выделении DHCP присваивает клиенту постоянный IP-адрес. При динамическом присвоении DHCP присваивает клиенту IP-адрес на ограниченное время. При ручном выделении, IP-адрес выделяется клиенту сетевым администратором, а DHCP используется просто для передачи адреса клиенту. Конкретная сеть применяет один или более этих механизмов, в зависимости от политики сетевого администратора.
Динамическое присвоение адресов представляет собой единственный механизм, который автоматически позволяет повторно использовать адрес, который не нужен клиенту.
Динамическое присвоение адресов является оптимальной схемой для клиентов, подключаемых к сети временно, или совместно использующих один и тот же набор IP-адресов и не нуждающихся в постоянных адресах.
Протокол DHCP предназначен для предоставления клиентам конфигурационных параметров, описанных в RFC Host Requirements. После получения через DHCP необходимых параметров, клиент должен быть готов к обмену пакетами с любой другой ЭВМ в Интернет. Не все эти параметры необходимы для первичной инициализации клиента. Клиент и сервер могут согласовывать список необходимых параметров.
Протокол DHCP позволяет, но не требует конфигурации параметров клиента, не имеющих прямого отношения к IP-протоколу. DHCP не обращается к системе DNS для регистрации адреса. DHCP не может использоваться для конфигурации маршрутизаторов.
DHCP должен:
гарантировать, что любой специфический сетевой адрес не будет использоваться более чем одним клиентом одновременно
поддерживать DHCP конфигурацию клиента при стартовой перезагрузке DHCP-клиента. Клиенту DHCP должен, при каждом запросе по мере возможности, присваиваться один и тот же набор конфигурационных параметров (например, сетевой адрес)
поддерживать конфигурацию DHCP-клиента при перезагрузке сервера, и, по мере возможности, DHCP-клиенту должен присваиваться один и тот же набор конфигурационных параметров
позволять автоматически присваивать конфигурационные параметры новым клиентам, чтобы избежать ручной конфигурации
поддерживать фиксированное или постоянное присвоение конфигурационных параметров для заданного клиента
Первым видом сервиса, предоставляемого DHCP, является запоминание сетевых параметров для клиента. Модель DHCP памяти характеризуется записями ключзначение для каждого клиента, где ключ представляет собой некоторый уникальный идентификатор (например, номер IP-субсети и уникальный идентификатор в пределах субсети), а значение содержит набор конфигурационных параметров клиента.
Например, ключ может представлять собой пару (номер IP-субсети, аппаратный адрес), чтобы допустить повторное или даже одновременное применение одних и тех же аппаратных адресов в различных субсетях. Заметим, что должен быть определен тип аппаратного адреса, чтобы можно было решить проблему возможного дублирования при изменении порядка бит в случае смешения типов оборудования. В качестве альтернативы ключ может представлять собой пару (номер IP-субсети, имя ЭВМ), позволяя серверу присвоить параметры DHCPклиенту, который переместился в другую субсеть или сменил свой аппаратный адрес (возможно, изза выхода из строя и замены сетевого интерфейса). Протокол определяет то, что ключ представляет собой (номер IP-субсети, аппаратный адрес), если только клиент не предлагает идентификатор в явном виде, используя опцию client identifier. Клиент может запросить DHCPсервис, чтобы получить свои конфигурационные параметры. Интерфейс клиента к депозитарию конфигурационных параметров реализуется с помощью протокольных сообщений запроса и откликов серверов, несущих в себе конфигурационные параметры.
Вторым видом сервиса, предоставляемым DHCP, является временное или постоянное выделение клиенту сетевого (IP) адреса. Основной механизм для динамического присвоения сетевых адресов достаточно прост: клиент запрашивает использование адреса на определенный период времени. Механизм выделения адреса (ассоциация DHCPсерверов) гарантирует, что адрес в течение оговоренного времени не будет использован для других целей, и пытается прислать тот же сетевой адрес всякий раз, когда клиент его запрашивает. Клиент может расширить это время последующими запросами. Клиент может послать серверу сообщение об освобождении адреса, когда клиент более не нуждается в этом адресе. Клиент может запросить постоянное присвоение адреса, потребовав бесконечное значение времени выделения адреса. Даже при постоянном выделении адресов сервер может определить большой, но не бесконечный срок аренды адреса — тогда будет возможно детектировать факт, что клиент перестал работать.
При некоторых обстоятельствах может оказаться необходимым повторно присваивать сетевые адреса из-за отсутствия свободных адресов. При таких условиях механизм выделения будет повторно присваивать адреса, чье время действительности истекло. Сервер должен использовать информацию, которая доступна в конфигурационном депозитарии, чтобы выбрать адрес, который может быть использован повторно. Например, сервер может выбрать последний из присвоенных адресов. В качестве контроля совместимости сервер должен проверить повторно используемые адреса, прежде чем снова пускать их в оборот. Это может быть, например, контроль посредством ICMP эхозапроса, а клиент должен проверить вновь полученный адрес, например, посредством ARP.
При использовании DHCP применяется следующая процедура:
Клиент широковещательно пересылает сообщение DHCPDISCOVER по локальной физической субсети. Сообщение DHCPDISCOVER может включать опции, которые предлагают значения для сетевого адреса и длительности его использования. Агент транспортировки BOOTP может передать сообщение DHCP-серверам, которые размещены за пределами данной физической субсети
Каждый сервер может откликнуться сообщением DHCPOFFER, которое содержит сетевой адрес в поле yiaddr (и другие конфигурационные параметры в опциях DHCP). При выделении нового адреса серверы должны проверять, чтобы предлагаемый сетевой адрес не использовался гдето еще; например, сервер может протестировать предлагаемый адрес с помощью эхозапроса ICMP. Сервер отправляет клиенту сообщение DHCPOFFER.
Клиент получает одно или более сообщений DHCPOFFER от одного или более серверов. Клиент выбирает один сервер, которому пошлет запрос конфигурационных параметров, согласно предложению, содержащемуся в сообщении DHCPOFFER. Клиент широковещательно отправляет сообщение DHCPREQUEST, которое должно содержать опцию server identifier, чтобы указать, какой сервер им выбран, и которое может включать в себя другие опции, специфицирующие желательные конфигурационные значения. Клиент реализует таймаут и повторно посылает сообщение DHCPDISCOVER, если не получает сообщений DHCPOFFER
Серверы получают широковещательное сообщение DHCPREQUEST от клиента. Серверы, не выбранные сообщением DHCPREQUEST, используют сообщение как уведомления о том, что клиент отверг предложение сервера. Сервер, выбранный сообщением DHCPREQUEST, осуществляет запись конфигурационного набора клиента в постоянную память и реагирует сообщением DHCPACK, содержащим конфигурационные параметры для клиента, приславшего запрос. Если выбранный сервер не может адекватно реагировать на сообщение DHCPREQUEST (например, запрошенный сетевой адрес уже выделен), сервер должен ответить посылкой сообщения DHCPNAK. Сервер должен пометить адрес, предложенный клиенту в сообщении DHCPOFFER, как доступный, если сервер не получил от клиента никакого сообщения DHCPREQUEST.
Клиент получает сообщение DHCPACK, содержащее конфигурационные параметры. Клиент должен выполнить окончательную проверку параметров (например, запустить ARP для выделенного сетевого адреса) и фиксировать длительность предоставления конфигурационных параметров, прописанную в сообщении DHCPACK. Клиент окончательно сконфигурирован. Если клиент обнаруживает, что адрес уже используется (например, с помощью ARP), он должен послать серверу сообщение DHCPDECLINE и повторно запустить процесс конфигурации. Клиент должен подождать как минимум 10 секунд, прежде чем заново начинать конфигурационную процедуру, чтобы избежать возникновения лишнего сетевого трафика. Если клиент получает сообщение DHCPNAK, он перезапускает конфигурационный процесс.
Клиент реализует таймаут и повторно посылает сообщение DHCPREQUEST, если он не получает ни сообщения DHCPACK ни DHCPNAK. Клиент повторно посылает DHCPREQUEST согласно алгоритму повторной пересылки. Клиент должен выбрать число повторных передач сообщения DHCPREQUEST адекватным, чтобы обеспечить достаточную вероятность доступа к серверу, не заставляя клиента (и пользователя этого клиента) ждать слишком долго; например, клиент может повторно послать сообщение DHCPREQUEST четыре раза, при полной задержке 60 секунд, прежде чем повторно запустит процедуру инициализации. Если клиент не получает ни сообщения DHCPACK ни DHCPNAK после применения алгоритма повторной пересылки, клиент возвращается в исходное состояние и перезапускает процесс инициализации. Клиент должен уведомить пользователя о том, что процесс инициализации не прошел и делается повторная попытка.
Клиент может решить отказаться от аренды сетевого адреса путем посылки серверу сообщения DHCPRELEASE. Клиент идентифицирует набор параметров, от которого он отказывается, с помощью своего идентификатора, или chaddr и сетевого адреса в сообщении DHCPRELEASE. Если клиент использовал идентификатор клиента, когда он получил набор конфигурационных параметров, клиент должен использовать тот же идентификатор клиента (client identifier) в сообщении DHCPRELEASE.
Структурная организация корпоративных сетей.
Корпоративная сеть - система, обеспечивающая передачу информации между различными приложениями, используемыми в системе корпорации. Сеть должна быть максимально универсальной, то есть допускать интеграцию уже существующих и будущих приложений с минимально возможными затратами и ограничениями.
Корпоративная сеть, как правило, является территориально распределенной, т.е. объединяющей офисы, подразделения и другие структуры, находящиеся на значительном удалении друг от друга. Часто узлы корпоративной сети оказываются расположенными в различных городах, а иногда и странах. Принципы, по которым строится такая сеть, достаточно сильно отличаются от тех, что используются при создании локальной сети, даже охватывающей несколько зданий. Основное отличие состоит в том, что территориально распределенные сети используют достаточно медленные (на сегодня - десятки и сотни килобит в секунду, иногда до 2 Мбит/с.) арендованные линии связи. Если при создании локальной сети основные затраты приходятся на закупку оборудования и прокладку кабеля, то в территориально-распределенных сетях наиболее существенным элементом стоимости оказывается арендная плата за использование каналов, которая быстро растет с увеличением качества и скорости передачи данных. Это ограничение является принципиальным, и при проектировании корпоративной сети следует предпринимать все меры для минимизации объемов передаваемых данных. В остальном же корпоративная сеть не должна вносить ограничений на то, какие именно приложения и каким образом обрабатывают переносимую по ней информацию.
Первая проблема, которую приходится решать при создании корпоративной сети - организация каналов связи. Если в пределах одного города можно рассчитывать на аренду выделенных линий, в том числе высокоскоростных, то при переходе к географически удаленным узлам стоимость аренды каналов становится просто астрономической, а качество и надежность их часто оказывается весьма невысокими.
Естественным решением этой проблемы является использование уже существующих глобальных сетей. В этом случае достаточно обеспечить каналы от офисов до ближайших узлов сети. Задачу доставки информации между узлами глобальная сеть при этом возьмет на себя. Даже при создании небольшой сети в пределах одного города следует иметь в виду возможность дальнейшего расширения и использовать технологии, совместимые с существующими глобальными сетями. Часто первой, а то и единственной такой сетью, мысль о которой приходит в голову, оказывается Internet.
Корпоративные сети, как правило, развиваются вместе с развитием предприятия, поэтому наблюдается некая хаотичность в построении таких сетей, зачастую добавляются новые абоненты, серверы, сети отделов, которые не наносятся на первычный план сети. Всвязи с этим управление такой сетью усложняется, поиск неисправностей и сбоев занимает много времени, чтобы избежать этого необходимо планировать развитие сети, предусматривать выделение сетей отделов, кампусов, групп и т.д. Очень часто при построении больших сетей использование типовых структур сетей порождает ряд ограничений, основными из которых являются:
ограничение на длину связи между абонентами или узлами;
ограничение на количество узлов в сети;
ограничение на интенсивность траффика порождаемого узлами;
сложность обслуживания сетей.
Структуризация корпоративных сетей.
Для расширения количества абонентов в сети, можно использовать повторители (hub).

Рис. 11.1. Структура сети с повторителями.
Однако,
в случае интенсивного обмена такой
принцип не приемлем, кроме того наличие
протяженного общего канала снижает
надежность сети. Для повышения надежности,
можно использовать звездообразную
топологию:

Рис. 11.2. Звездообразная топология.
В работе концентраторов (switch) любых технологий, много общего, они повторяют сигнал пришедший с одних портов на другие свои порты. Небольшие корпоративные сети можно строить с использованием нескольких концентраторов:
 Рис.
11.3. Сеть с несколькими концентраторами.
Рис.
11.3. Сеть с несколькими концентраторами.
Что бы разгрузить линию, вместо К5 используют мост (он фильтрует пакеты).
В дальнейшем используют маршрутизатор. Он имеет специальные порты для выхода в глобальные сети. Для соединения сетей с различными протоколами используют шлюзы.
Структуризацию можно выполнить по-комнатно, поэтажно, по зданиям, по площадкам.
Для соединения отдельных подсетей могут использоваться распределенные магистрали или стянутые в точку магистрали.
 Рис.
11.4. Структуризация сети по этажам.
Рис.
11.4. Структуризация сети по этажам.
В качестве позвоночника можно использовать маршрутизатор.

Рис. 11.5. Структуризация через маршрутизатор.
Сети рабочих групп и отделов.
Сети отделов – это такие сети, которые используются сравнительно небольшой группой сотрудников, работающих в одном отделе предприятия.
Количество компьютеров и других вычислительных средств в таких сетях порядка 50-60 штук.
Главной целью сети отдела, является разделение локальных ресурсов: приложения, данные, принтеры и модемы, между собой.
Обычно сети отделов имеют: 1-2 файловых сервера, сервер печати, сервер приложений.
Упрощенную структуру можно представить следующим образом:

Рис. 11.6. Структура сети отдела.
Сети отделов обычно создаются на основе одной технологии. Для такой сети характерен один или два типа операционных систем. Задачи управления сетью на уровне отдела просты и сводятся к добавлению или исключению пользовательских станций, инсталляции новых узлов и установке новых версий операционной системы.
Специального администратора не назначают, а указанные функции возлагают на одного из сотрудников.
Более мелкой единицей, являются сети рабочих групп, в таких сетях порядка 10-20 рабочих станций.
Сеть кампусов это сеть предприятия, подразделения которого располагаются на небольшой территории.
Количество рабочих станций до 1000, территория порядка нескольких квадратных километров.
Особенностями таких сетей являются:
Они объединяют сети различных отделов одного предприятия, в пределах одного здания или нескольких рядом располагающихся.
Наличие специальных служб в сети, обеспечивающих взаимодействие между программными и аппаратными средствами отдельно от сетей.
Структурно сеть можно представить:

Рис. 11.7. Сеть кампуса.
По сравнению с сетями отделов, данная является составной, может включать компьютеры разных фирм с разными операционными системами. Технологии отдельных подсетей могут быть разные.
Необходимо решать проблемы сопряжения неоднородных элементов в единую интегрированную сеть. Администратор сети должен быть высококвалифицированный, а средства оперативного управления сетью более совершенными. Глобальные связи не используются.
Корпоративными сетями называются сети масштаба предприятий.
Данные сети объединяют более 1000 компьютеров, отдельные площадки могут находиться друг от друга на значительном расстоянии, поэтому в них часто используют глобальные связи. Для этого могут использоваться следующие линии связи: телефонный канал, радио канал, спутниковая связь, телеграфная связь.
Такую сеть можно представить в виде островков локальных сетей, объединенных различными телекоммуникационными средствами.
Структурно сеть можно представить:
Рис. 11.8. Сеть предприятия.
Корпоративные сети могут объединять города, регионы и даже континенты. Они могут использовать глобальные связзи для соединения локальных сетей или отдельных компьютеров.
К наиболее существенным особенностям корпоративных сетей можно отнести:
1) гетерогенность (неоднородность оборудования, протоколов, операционных систем, приложений);
2) использование разнообразных глобальных связей;
3) интегрированность (работа неоднородных элементов как единое целое);
4) повышенные требования к надежности (выполняются важные функции);
5) масштабность системы;
6) повышенные требования к управляемости сети;
7) широта охвата технических проблем при развертывании и эксплуатации;
8) потребность в наличии специалистов различных профилей, для обслуживания.