

НОВЫЙ КУРС БД 2013
.pdf4.1.4Ограничения ссылочной целостности.
Кограничениям ссылочной целостности относится всего один тип ограничений – ограничения внешних ключей (FOREIGN KEY сокращенно FK). Внешние ключи не только обеспечивают целостность данных, но и обеспечивают связи между таблицами. После задания FK на таблице устанавливается зависимость между таблицей, в которой определен внешний ключ и таблицей, на которую ссылается внешний ключ. При этом любая строка из таблицы с внешним ключом должна удовлетворять одному из двух условий:
Значение столбца FK должно быть равно одному из значений столбца связанной таблицы
Иметь Null-значение
Смысл внешних ключей проще понять на примере: пусть есть 2 таблицы Mans и Jobs
Таблица Mans
ID |
Surname |
Job |
1 |
Иванов |
10 |
2 |
Петров |
20 |
3 |
Сидоров |
30 |
4 |
Виейра |
Null |
|
Таблица Jobs |
|
ID |
|
JobName |
10 |
|
Менеджер |
20 |
|
Продавец |
30 |
|
Уборщик |
40 |
|
Программист |
Ограничение FK, наложенное на столбец Job таблицы Mans с согласованием по столбцу id таблицы Jobs означает, что в каждой строке в столбце Job таблицы Mans должны быть либо Nullзначения либо одно из значений столбца Id таблицы Jobs, т.е. одно из значений 10, 20, 30 или 40. В данной таблице условие соблюдаются. Однако если попытаться вставить в таблицу Mans строку такого вида:
INSERT INTO Mans (Surname, Job) Values (‘ упкин’, 50)
Мы неизбежно получим сообщение об ошибке, так как значение с id = 50 в таблице Jobs нет.
Итак, после описания принципов работы внешних ключей перейдем к тому, как они задаются.
В общем виде внешний ключ задается так:
FOREIGN KEY REFERENCES имя_таблицы (имя_столбца)
[ON DELETE {CASCADE| NO ACTION| SET NULL| SET DEFAULT}] [ON UPDATE {CASCADE| NO ACTION| SET NULL| SET DEFAULT}]
Следует обозначить несколько важных моментов:
Столбец, на который ссылается внешний ключ, должен иметь уникальные значения (т.е. на нем должно быть задано ограничение Primary Key или Unique)
Столбец должен иметь тот же тип данных, что и связываемый столбец
На одном и том же столбце можно задать и внешний и первичный ключ
Для любой таблицы может быть задано до 253 внешних ключей
Каждый столбец таблицы может входить только в один внешний ключ
Создание FK при создании таблицы
В целом пример задания внешнего ключа для указанных выше таблиц выглядит так:
CREATE TABLE Jobs
( ID int identity not null PRIMARY KEY, JobName varchar(80) not null UNIQUE
)
CREATE TABLE Mans
( ID int identity not null PRIMARY KEY, Surname varchar(80) not null,
Job FOREIGN KEY REFERENCES Jobs (id)
)
61
Создание FK на существующей таблице
Для создания ограничения на существующей таблице используется практически тот же синтаксис, что и для создания ограничения при создании таблицы.
Alter Table Mans
ADD CONSTRAINT FK_Mans_Jobs FOREIGN KEY Job REFERNCES Jobs(id)
Данный код накладывает ограничение на столбец Job таблицы Man, согласуя его значения со значениями столбца id таблицы Jobs.
Особое использование внешних ключей (рекурсия – ссылка на саму себя)
В этом подпункте я бы хотел рассмотреть возможность использования внешних ключей ссылающихся на одну и туже таблицу, т.е. ссылающейся на себя. Это означает, что одна и та же таблица будет играть роль ссылающейся таблицы и таблицы указанной в ссылке ограничения. Данные связи встречаются не очень часто, однако имеют место быть.
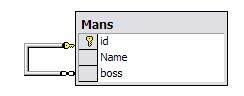
Например, пусть есть все та же таблица Mans и в ней мы укажем начальника человека, при этом начальник также будет храниться в таблице Mans (можно было бы конечно создать отдельную таблицу для начальников и связать ее с Man, но мы поступим проще и замкнем таблицу саму на себя по полю id -> boss):
Create Table Mans
(
id int identity not null PRIMARY KEY, Name varchar(10) not null UNIQUE,
boss int FOREIGN KEY REFERENCES Mans(id)
)
Выглядеть в СУБД MS SQL Server это будет немного странно и непривычно:
Но, тем не менее, мы создали внешний ключ на основе первичного ключа той же таблицы, и теперь при попытке назначить начальника человеку будет проверяться, существует ли такой начальник в таблице Mans. (Примечательно, что человек при этом может быть сам себе начальником). Еще одно замечание по поводу таблиц ссылающихся на самих себя: прежде чем создать ограничение внешнего ключа, ссылающегося на первичный ключ той же таблицы, крайне необходимо внести в таблицу хотя бы одну строку и только после этого задавать внешний ключ. Дело в том, что первичный ключ заполняется, после того, как была осуществлена проверка ограничения внешнего ключа. На практике это означает, что при отсутствии строк таблицы в таблице еще отсутствует значение, на которое могла бы указывать ссылка из первой строки. Из этой ситуации есть еще один выход – создать внешний ключ, а затем запретить его использование при вводе первой строки. Как отменить действия ограничений будет рассмотрено позже.
Каскадное осуществление действий
С первой частью синтаксиса первичного ключа мы разобрались:
FOREIGN KEY REFERENCES имя_таблицы (имя_столбца)
, но что означают строки ниже?
[ON DELETE {CASCADE| NO ACTION| SET NULL| SET DEFAULT}]
[ON UPDATE {CASCADE| NO ACTION| SET NULL| SET DEFAULT}]
Давайте устраним этот пробел в знаниях. Дело в том, что внешние ключи в отличие от всех остальных ключей (первичных и индексных, которые здесь не рассматривались) имеют двунаправленное действие, т.е. они влияют не только на таблицу, в которой определены, но и на
62
таблицу «родителя». На практике это означает, что при изменении строк «родительской» таблицы разработчик может управлять связанными строками в «подчиненной» таблице. Конструкция представленная выше как раз и позволяет управлять поведением связанных строк таблицы при удалении или обновлении строк «родительской» таблицы.
Давайте теперь рассмотрим по порядку все возможные действия, которые могут возникнуть
между двумя связанными таблицами: |
|
Итак, пусть у нас есть все те же таблицы Mans и Jobs: |
|
Таблица Mans |
Таблица Jobs |
ID |
Surname |
Job |
1 |
Иванов |
10 |
2 |
Петров |
20 |
3 |
Сидоров |
30 |
4 |
Виейра |
Null |
ID |
JobName |
10 |
Менеджер |
20 |
Продавец |
30 |
Уборщик |
40 |
Программист |
1)Удаление строки из таблицы Mans
Delete from Mans where id=3
2)Удаление строки из таблицы Jobs
Delete from Jobs where id=10
3)Обновление столбца Job в таблице Mans
Update Mans Set Job=50 Where Surname=’Виейра’
4)Обновление столбца Id в таблице Jobs
Update Jobs Set Id=50 Where Id=10
В первом случае, - т.е. при удалении строки из таблицы Mans, ограничение внешнего ключа никак не сказывается на «родительской» таблице Jobs и строка будет успешно удалена без какихлибо проблем. А вот во всех остальных случаях (2,3,4) возникнут проблемы, поскольку перечень значений столбца Job (Mans) не будет соответствовать перечню столбца Id (Jobs). Поэтому по умолчанию СУБД запрещает удалять или обновлять связанные строки из «родительской» таблицы (или добавлять значения не указанные в родительской таблице), если в связанной таблице есть хотя бы одна запись с удаляемым значением. Несомненно, такой способ организации данных очень удобен, поскольку поддерживает целостность данных, но что делать, если нам нужно удалить или обновить, скажем, id всех менеджеров? Можно конечно поступить в несколько этапов: сначала обнулить Job в таблице Mans, затем изменить id в таблице Jobs, а потом присвоить новые id удаленным сотрудникам и т.д., но, во-первых, это порождает потенциальные ошибки, а во-вторых, приходится делать слишком много запросов.
Процесс автоматического удаления/обновления строк в зависимой таблице известен под названием каскадного выполнения действий. СУБД MS SQL Server позволяет отдельно выполнять различные действия для обновления и удаления строк. Для того чтобы добавить действия на эти события достаточно дописать в определение внешнего ключа фразу ON на каждое действие:
ON Update действия ON Delete действия
Вкачестве действий здесь могут быть указаны:
CASCADE (при удалении/обновлении строки из родительской таблицы удаляются/обновляются все строки связанной таблицы)
NO ACTION (действие предлагаемое СУБД по умолчанию. Удаление/обновление строки в родительской таблице запрещено, если есть связанные с ней строки в подчиненной таблице. Если не указать слово NO ACTION, то ничего не измениться, так как этот вариант предлагает сама СУБД изначально)
SET NULL (начиная с MS SQL Server 2005) (при удалении/обновлении строки из родительской таблицы все столбцы внешних ключей связанных строк в подчиненной таблице заменяются Null-значениями)
63

SET DEFAULT (начиная с MS SQL Server 2005) (при удалении/обновлении строки из родительской таблицы все столбцы внешних ключей связанных строк в подчиненной таблице заменяются значениями по умолчанию)
Таким образом, полный пример определения внешнего ключа может выглядеть так:
Alter Table Mans
ADD CONSTRAINT FK_Mans_Jobs FOREIGN KEY Job REDERNCES Jobs(id)
ON UPDATE CASCADE
ON DELETE SET NULL
Приведенный выше пример означает, что при удалении строки из таблицы Jobs значения столбца Job таблицы Mans, согласующихся строк, будут заменены на Null. А при обновлении id в таблице Jobs эти значения также будут обновлены и в таблице Mans. Чтобы стало еще понятнее, покажем это на примере:
Таблица Mans
ID |
Surname |
Job |
1 |
Иванов |
10 |
2 |
Петров |
20 |
3 |
Сидоров |
30 |
4 |
Виейра |
Null |
|
Таблица Jobs |
|
ID |
|
JobName |
10 |
|
Менеджер |
20 |
|
Продавец |
30 |
|
Уборщик |
40 |
|
Программист |
Выполним код, который обновит id строки должности менеджер и сделает его равным 50 (данный код сработает при условии, что столбец id задан без указания авто инкремента identity):
Update Jobs Set id=50 where JobName Like’%Менеджер%’
После выполнения кода, таблицы примут такой вид:
Таблица Mans
ID |
Surname |
Job |
1 |
Иванов |
50 |
2 |
Петров |
20 |
3 |
Сидоров |
30 |
4 |
Виейра |
Null |
|
Таблица Jobs |
|
ID |
|
JobName |
50 |
|
Менеджер |
20 |
|
Продавец |
30 |
|
Уборщик |
40 |
|
Программист |
Выполним код, который бы удалил должность менеджера из таблицы Jobs:
Delete from Jobs where JobName Like’%Менеджер%’
При этом в таблицах Mans и Jobs произойдут следующие изменения:
Таблица Mans Таблица Jobs
ID |
Surname |
Job |
1 |
Иванов |
Null |
2 |
Петров |
20 |
3 |
Сидоров |
30 |
4 |
Виейра |
Null |
ID |
JobName |
20 |
Продавец |
30 |
Уборщик |
40 |
Программист |
64
4.1.5 Отмена действий ограничений.
Во время эксплуатации БД иногда возникает необходимость отменить ограничения навсегда или на какое-то время. Если мы попытаемся ввести ограничение на уже заполненной таблице, то значения столбца, на которое накладывается ограничение, будет проверено на соответствие этому ограничению и если есть хоть одна строка с «неправильным» значением столбца, то будет сообщение об ошибке. Т.е. мы должны либо поправить все строки, не удовлетворяющие требованиям ограничения, либо изменить само ограничение, фактически, подгоняя его под значения столбцов таблицы, что в корне не верно. Конечно же, MS SQL Server предлагает инструменты для решения подобных вопросов. Давай их рассмотрим:
Временная отмена ограничения оператор – NOCHECK
Игнорирование неправильных данных при создании ограничения – WITH NOCHECK Давайте рассмотрим эти способы более подробно:
Итак, первый способ (NOCHECK) позволяет временно отменить ограничение, чтобы появилась возможность ввести данные, не удовлетворяющие требованиям этого ограничения. На первый взгляд такая возможность ставит в тупик – зачем нарочно нарушать целостность базы, выключая ограничение, тем самым, создавая возможность вводить «неправильные» данные?
Но так кажется только на первый взгляд. Дело в том, что требования к данным в жизни меняются очень часто (выходят новые законы, меняется начальство и т.д.), и поэтому часто возникает такая ситуация, когда нужно занести в базу данных устаревшие данные, скажем телефоны фирм Нижнего Новгорода, существовавших до 2000 года. Немного поясню задачу: раньше все телефоны были шестизначными (XX-XX-XX), а с вводом новых АТС, весной 2007 года, номера стали семизначными (XXX-XX-XX) и разработчики современных баз ориентируются
уже на это значение цифр в телефоне. Пусть при вставке номера, срабатывает такое ограничение:
CHECK CH_Mans_Phone (Phone Like '([0-9][0-9][0-9])[0-9][0-9][0-9]-[0-9][0-9]-[0-9][0-9]')
Поясним действия данного ограничения, оно проверят, чтобы вставляемое значение было длиной 14 символов и первый символ был скобкой, далее шли три числа от 0 до 9, далее шла закрывающая скобка, затем еще три числа от 0 до 9, потом тире, затем два числа от 0 до 9, потом опять тире и два числа от 0 до 9.
Это означает, что в базу могут быть вставлены лишь номера такого типа:
(852)222-22-22, (908)456-45-45 и т.д.
А номера вида: 4564544, 234534, 89081122334 и т.д. будут отвергаться.
Поскольку нам нужно вставить номера вида (XXX)XX-XX-XX, то на первый взгляд задача кажется невыполнимой без удаления или изменения ограничения. Однако конструкция:
ALTER Table Mans NOCHECK CONSTRAINT CH_Mans_Phone
позволяет отключить ограничение и спокойно вставлять любые данные в поле Phone. После того как требуемые данные были вставлены, можно опять включить это ограничение опцией CHECK:
ALTER Table Mans CHECK CONSTRAINT CH_Mans_Phone
В итоге при включении ограничения, будут проверяться только вновь вводимые данные, а те, что были введены ранее, проверке подвергаться не будут.
Второй способ (WITH NOCHECK) заключается в том, что можно создавать ограничение без проверки уже существующих данных. Как было сказано выше при наложении ограничения на столбец, если в таблице уже есть данные, то значения в этом столбце должны соответствовать условиям ограничения. Конструкция WITH NOCHECK как раз и отменяет эту проверку. Например, возьмем все те же номера телефонов, пусть у нас в базу вбиты номера вида XXX-XX- XX, а заказчик хочет, чтобы теперь к номерам обязательно добавлялись коды городов. Т.е. нужно
65
чтобы все номера были в формате (XXX)XXX-XX-XX. Если мы просто попытаемся наложить такое ограничение:
ALTER TABLE MANS ADD CONSTRAINT
CHECK CH_Mans_Phone (Phone Like '([0-9][0-9][0-9])[0-9][0-9][0-9]-[0-9][0-9]-[0-9][0-9]'),
то возникнет ошибка, поскольку существующие номера формата XXX-XX-XX не соответствуют требованиям ограничения. Однако, добавив всего два слова - WITH NOCHECK мы легко проделаем данную операцию:
ALTER TABLE MANS WITH NOCHECK ADD CONSTRAINT
CHECK CH_Mans_Phone (Phone Like '([0-9][0-9][0-9])[0-9][0-9][0-9]-[0-9][0-9]-[0-9][0-9]'),
Таким образом, мы сохранили часть номеров в старом формате (XXX-XX-XX), но вводить новые номера можно в только в формате (XXX)XXX-XX-XX.
4.2Сценарии, пакеты и специальные команды SQL.
Кэтому моменту мы написали очень много запросов в среде MS SQL Server и теперь вплотную подошли к созданию сценариев. Давайте вначале определимся, что такое сценарий:
Сценарий - один или несколько операторов TSQL хранящийся в виде текстового файла, который может неоднократно вызываться на исполнение.
По сути, все, что мы писали раньше, также является сценарием, просто мы не сохраняли наши запросы в текстовые файлы. Как правило, сценарии сохраняются как обычный текстовый файл, однако указывается расширение – .sql
Для того чтобы создать наш первый сценарий необходимо выбрать в меню SQL Server’a пункт Инструменты (Tools) и выбрать SQL Query Analyzer (Рис. 4.2.1). После этого появится окно анализатора запросов, представленное на рисунке 4.2.2
Рис. 4.2.1 ункт меню анализатор запросов SQL
66

Рис. 4.2.2 Окно анализатора запросов
67
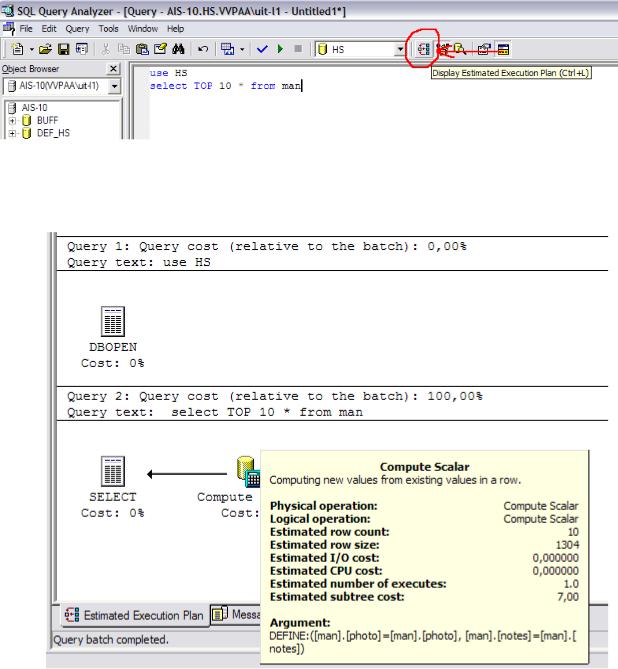
В окне анализатора мы можем писать запросы к базе, при этом он дает несколько бОльшие возможности, чем просто создание представления или запрос в визуальном виде. Он позволяет увидеть, как строится запрос, какие ресурсы тратятся и другую полезную информацию для оптимизации запросов. Для того чтобы посмотреть эту информацию достаточно нажать на кнопку показать план выполнения, представленную на рисунке 4.2.3
Рис. 4.2.3 Окно анализатора запросов. Кнопка план выполнения запроса
После этого в нижней части окна появится план выполнения запроса, он виден на рисунке 4.2.4, на нем можно посмотреть много полезной информации при наведении на различные иконки.
Рис. 4.2.4 Окно плана выполнения запроса
Однако мы немного отвлеклись от темы создания сценариев. Для того чтобы создать сценарий достаточно выполнить сохранение набранного в окне анализатора запроса. Т.е. как в любой программе выполнить пункт меню File-SaveAs (Файл-СохранитьКак) и задать имя нашему сценарию при этом файлу присвоиться расширение .sql. Поздравляю, мы создали наш первый сценарий!
Теперь мы можем вызвать его через функцию File-Open (Файл-Открыть) и выбрать соответствующий файл.
4.2.1 Специальные команды SQL в сценариях
До этого мы создавали все запросы в рамках одной базы данных, однако сценарий может работать с несколькими базами данных, содержать логику работы скриптов и даже записывать логи! По сути, сценарий является написанной на высокоуровневом языке программирования программой. Первый оператор, с которым мы познакомимся это оператор USE.
Оператор USE сообщает СУБД, с какой базой в данный момент мы будем работаем. Синтаксис использования довольно прост:
USE [имя базы данных]
После этого все операции будут происходить именно с той базой которую мы указали в операторе USE. Давайте рассмотрим типичный пример сценария:
USE NewOrders Select * from Orders
Здесь идет обращение к базе данных NewOrders, и из таблицы Orders этой базы выбираются все строки. Надеюсь применение этого оператора не вызовет каких либо осложнений.
Следующая не менее употребляемая команда, это команда DECLARE. На данном этапе мы начинаем потихоньку подходить к динамическому созданию запросов. Все, что мы писали раньше было определено на этапе написания запроса, т.е. грубо говоря, мы пользовались только константами, теперь пора исправить этот пробел и начать уже использовать переменные. Любая сколь угодно сложная программа, написанная на языке программирования, содержит переменные, так и большинство сложных запросов содержат переменные. Не нужно, однако, кидаться в панику и применять их везде, где только можно, следует использовать переменные там, где это действительно необходимо. А служат они, как и в других языках программирования, для отслеживания динамически изменяемых данных. Однако перейдем от слов к делу и рассмотрим синтаксис команды DECLARE:
DECLARE
@<имя переменной_1><тип переменной_1>, @<имя переменной_2><тип переменной_2>,
…
@<имя переменной_N><тип переменной_N>
Из синтаксиса видно что мы можем объявить как одну переменную, так и несколько просто указав их через запятую. Приведем пример объявления переменной:
DECLARE @MyVar int
Здесь мы объявили переменную с именем MyVar целочисленного типа. Самым важным вопросом здесь, будет какое значение получит эта переменная? Поскольку в разных языках программирования переменные изначально получают различные умолчания, где-то 0, где-то случайное число, что требует дополнительно инициализировать переменную в начале программы. Однако здесь всегда по умолчанию для любого типа переменных используется значение NULL.
Для того чтобы использовать эту переменную, т.е. присвоить ей какое-нибудь значение применяются два оператора – SET и SELECT. Почему используется 2 оператора, а не один до сих пор не понятно. Однако давайте посмотрим, как их применить:
SET @MyVar = 10
SET @MyVar = @MyVar * 0,13
или
SELECT @MyVar = 10
SELECT @MyVar = @MyVar * 0,13
Никакой разницы, какой оператор применить нет.
Еще более интересной предоставляется возможность в качестве значения переменной указывать запросы, которые возвращают 1 запись. Например:

SET @MyVar = (Select Max(Id) From Mans)
В результате выполнения этого запроса переменной MyVar будет присвоено максимальное значение столбца Id из таблицы Mans. Использование таких возможностей открывает очень богатые перспективы. Однако и это еще не все в SQL Server заложено очень много (около 40) глобальных переменных, которые хранят множество полезной информации. Системные переменные обозначаются двойным знаком @@ и их изменение крайне не желательно, и может привести к печальным последствиям. Поэтому чтобы использовать глобальную переменную лучше перестраховаться и присвоить ее значение созданной нами переменной. Типичный пример:
DECLARE @MyVar int
SET @MyVar = @@IDENTITY
Ниже приведен обзор системных переменных и их использование из книги Роберта Виейры:
70