

AOM / Tannenbaum
.pdfМультикомпьютеры с передачей сообщений |
623 |
менее стандартных узлов, которые связаны друг с другом высокоскоростной сетью. Поэтому ниже мы просто рассмотрим несколько конкретных примеров систем МРР: Cray T3E и Intel/Sandia Option Red.
СгауТЗЕ
В семейство ТЗЕ (последователя T3D) входят самые последние суперкомпьютеры, восходящие к компьютеру 6600. Различные модели — ТЗЕ, ТЗЕ-900 и ТЗЕ-1200 — идентичны с точки зрения архитектуры и различаются только ценой и производительностью (например, 600, 900 или 1200 мегафлопов на процессор). Мегафлоп — это 1 млн операций с плавающей точкой/с. (FLOP — FLoating-point OPerations — операции с плавающей точкой). В отличие от 6600 и Сгау-1, в которых очень мало параллелизма, эти машины могут содержать до 2048 процессоров. Мы используем термин ТЗЕ для обозначения всего семейства, но величины производительности будут приведены для машины ТЗЕ-1200. Эти машины продает компания Cray Research, филиал Silicon Graphics. Они применяются для разработки лекарственных препаратов, поиска нефти и многих других задач.
В системе ТЗЕ используются процессоры DEC Alpha 21164. Это суперскалярный процессор RISC, способный выдавать 4 команды за цикл. Он работает с частотой 300, 450 и 600 МГц в зависимости от модели. Тактовая частота — основное различие между разными моделями ТЗЕ. Alpha — это 64-битная машина с 64-бит- ными регистрами. Размер виртуальных адресов ограничен до 43 битов, а физических — до 40 битов. Таким образом, возможен доступ к 1 Тбайт физической памяти.
Каждый процессор Alpha имеет двухуровневую кэш-память, встроенную в микросхему процессора. Кэш-память первого уровня содержит 8 Кбайт для команд и 8 Кбайт для данных. Кэш-память второго уровня — это смежная трехвходовая ассоциативная кэш-память на 96 Кбайт, содержащая и команды и данные вместе. Кэш-память обоих уровней содержит команды и данные только из локального ОЗУ, а это может быть до 2 Гбайт на процессор. Поскольку максимальное число процессоров равно 2048, общий объем памяти может составлять 4 Тбайт.
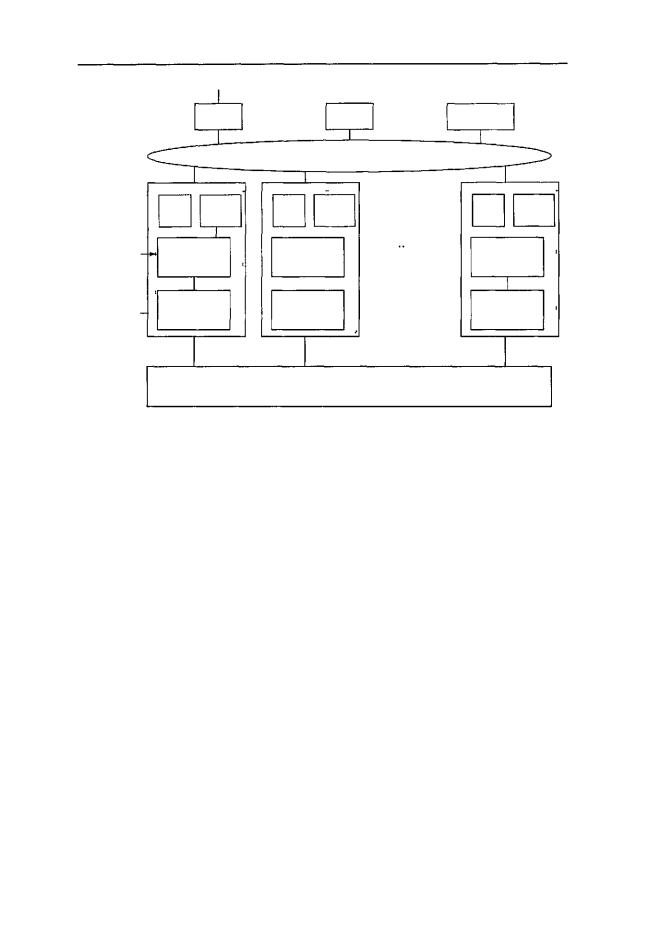
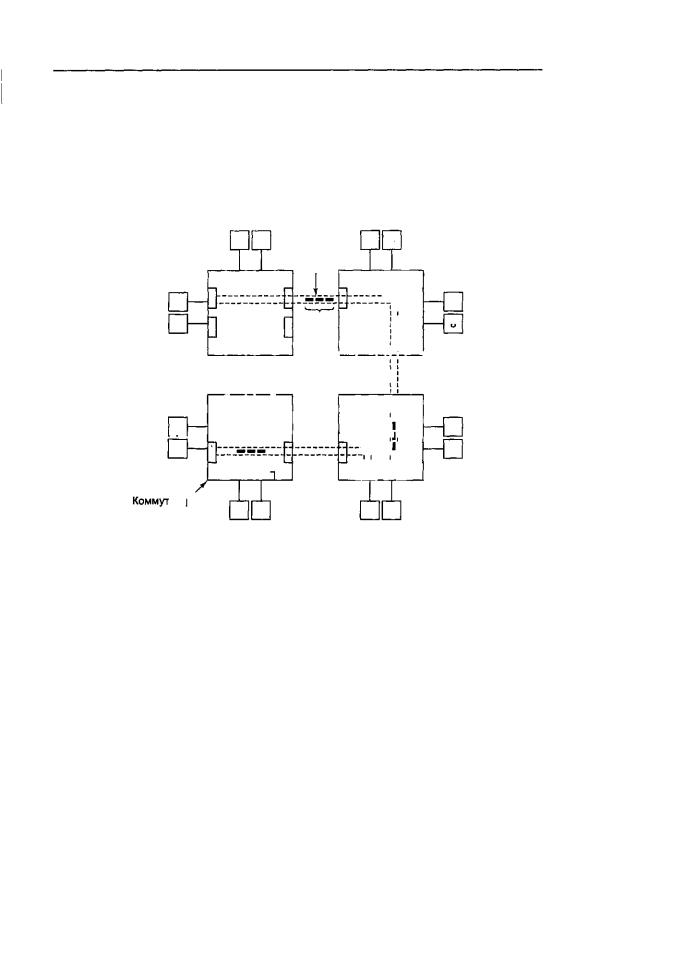
Каждый процессор Alpha заключен в особую схему, которая называется оболочкой (shell) (рис. 8.29). Оболочка содержит память, процессор передачи данных
и512 специальных регистров (так называемых Е-регистров). Эти регистры могут загружаться адресами удаленной памяти с целью чтения или записи слов из удаленной памяти (или блоков из 8 слов). Это значит, что в машине ТЗЕ есть доступ к удаленной памяти, но осуществляется он не с помощью обычных команд LOAD
иSTORE. Эта машина представляет собой гибрид между NC-NUMA и МРР, но всетаки больше похожа на МРР. Непротиворечивость памяти гарантируется, поскольку слова, считываемые из удаленной памяти, не попадают в кэш-память.
Узлы в машинеТЗЕ связаныдвумя разными способами (см. рис. 8.29). Основная топология — дуплексный 3-мерный тор. Например, система, содержащая 512 узлов, может быть реализована в виде куба 8x8x8. Каждый узел в 3-мерном торе имеет 6 каналов связи с соседними узлами (по направлению вперед, назад, вправо, влево, вверх и вниз). Скорость передачи данных в этих каналах связи равна 480 Мбайт/с в любом направлении.
6 2 4 Глава 8 Архитектуры компьютеров параллельного действия
Сеть |
Диск |
Магнитофон |
GigaRing
|
|
|
|
* |
- |
|
|
|
|
Alpha |
Память |
Alpha |
Память |
|
Alpha |
Память |
|
|
1 |
- |
4 |
- 1 |
|
4 |
- 1 |
|
Оболочка- |
Регистры |
Регистры |
|
Регистры |
|
|||
управления+ |
управления+ |
|
управления+ |
• |
||||
|
Е-регистры |
Е-регистры |
|
Е-регистры |
||||
|
|
|
||||||
|
|
|
|
1 |
|
|
|
1 |
|
|
|
|
|
Процессор |
|
||
t |
Процессор |
Процессор |
! |
|
||||
Узел |
передачи |
передачи |
|
передачи |
! |
|||
|
данных |
данных |
|
данных |
|
|||
> |
i |
|
Дуплексный трехмерный тор
Рис.8.29.CrayResearchT3E
Узлы также связаны одним или несколькими GigaRings — подсистемами вво- да-вывода с коммутацией пакетов, обладающими высокой пропускной способностью Узлы используют эту подсистему для взаимодействия друг с другом, а также с сетями, дисками и другими периферическими устройствами. Они по ней посылают пакеты размером до 256 байтов. Каждый GigaRing состоит из пары колец шириной в 32 бита, которые соединяют узлы процессоров со специальными узлами ввода-вывода. Узлы ввода-вывода содержат гнезда для сетевых карт (например, HIPPI, Ethernet, ATM, FDDI), дисков и других устройств.
В системе ТЗЕ может быть до 2048 узлов, поэтому неисправности будут происходить регулярно. По этой причине в системе на каждые 128 пользовательских узлов содержится один запасной узел. Испорченные узлы могут быть замещены запасными во время работы системы без перезагрузки Кроме пользовательских и запасных узлов есть узлы, которые предназначены для запуска серверов операционной системы, поскольку пользовательские узлы запускают не всю систему, а только ядро. В данном случае используется операционная система UNIX.
Intel/Sandia Option Red
Компьютеры с высокой производительностью и вооруженные силы идут в США рукаоб руку с 1943 года, начиная с машины ENIAC, первого электронного компьютера. Связь между американскими вооруженными силами и высокоскоростными вычислениями до сих пор продолжается. В середине 90-х годов департаменты обороны и энергетики приступили к выполнению программы разработки 5 систем МРР, которые будут работать со скоростью 1, 3, 10, 30 и 100 терафлопов/с соот-

Мультикомпьютеры с передачей сообщений |
625 |
ветственно. Для сравнения: 100 терафлопов (1014 операций с плавающей точкой в секунду) — это в 500000 раз больше, чем мощность процессора Pentium Pro, работающего с частотой 200 МГц.
В отличие от машины ТЗЕ, которую можно купить в магазине (правда, за большие деньги), машины, работающие со скоростью 1014 операций с плавающей точкой, — это уникальные системы, распределяемые в конкурентных торгахДепартаментомэнергетики,которыйруководитнациональнымилабораториями. Компания Intel выиграла первый контракт; IBM выиграла следующие два. Если вы планируете вступить в соревнование в будущем, вам понадобится 80 млн долларов. Эти машины предназначены для военных целей. Какой-то сообразительный работник Пентагона придумал патриотические названия для первых трех машин: red, white и blue (красный, белый и синий — цвета флага США). Первая машина, выполнявшая 1014 операций с плавающей точкой, называлась Option Red (Sandia National Laborotary, декабрь 1996), вторая — Option Blue (1999), а третья — Option White (2000). Ниже мы будем рассматривать первую из этих машин, Option Red.
Машина Option Red состоит из 4608 узлов, которые организованы в трехмерную сетку. Процессоры запакованы на платах двух разных типов. Платы kestrel используются в качестве вычислительных узлов, а платы eagle используются для сервисных, дисковых, сетевых узлов и узлов загрузки. Машина содержит 4536 вычислительных узлов, 32 сервисных узла, 32 дисковых узла, 6 сетевых узлов и 2 узла загрузки.
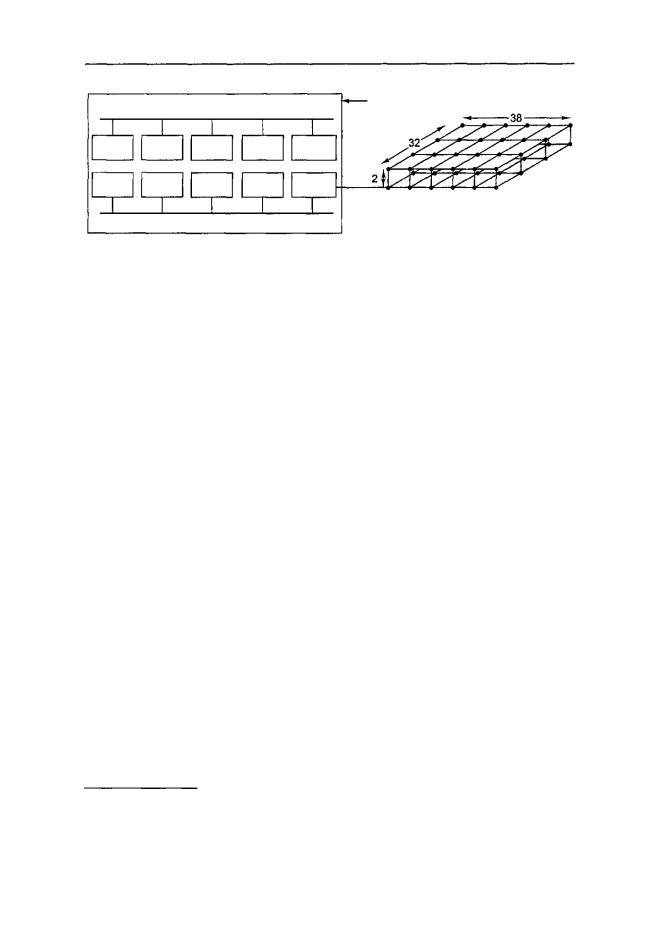
Плата kestrel (рис. 8.30, а) содержит 2 логических узла, каждый из которых включает 2 процессора Pentium Pro на 200 МГц и разделенное ОЗУ на 64 Мбайт. Каждый узел kestrel содержит собственную 64-битную локальную шину и собственную микросхему NIC (Network Interface Chip — сетевой адаптер). Две микросхемы NIC связаны вместе, поэтому только одна из них подсоединена к сети, что делает систему более компактной. Платы eagle также содержат процессоры Pentium Pro, но всего два на каждую плату. Кроме того, они отличаются высокой производительностью процесса ввода-вывода.
Платы связаны в виде решетки 32x38x2 в виде двух взаимосвязанных плоскостей 32x38 (размер решетки продиктован целями компоновки, поэтому не во всех узлах решетки находятся платы). В каждом узле находится маршрутизатор с шестью каналами связи: вперед, назад, вправо, влево, с другой плоскостью и с платой kerstel или eagle. Каждый канал связи может передавать информацию одновременно в обоих направлениях со скоростью 400 Мбайт/с. Применяется маршрутизация «червоточина», чтобы сократить время ожидания.
Применяется пространственная маршрутизация, когда пакеты сначала потенциально перемещаются в другую плоскость, затем вправо-влево, затем вперед-назад и, наконец, в нужную плоскость, если они еще не оказались в нужной плоскости. Два перемещения между плоскостями нужны для повышения отказоустойчивости. Предположим, что пакет нужно переместить в соседний узел, находящийся впереди исходного, но канал связи между ними поврежден. Тогда сообщение можно отправить в другую плоскость, затем на один узел вперед, а затем обратно в первую плоскость, минуя таким образом поврежденный канал связи.
6 2 6 Глава 8. Архитектуры компьютеров параллельного действия
|
64-битная локальная шина |
Плата |
||
|
"kestrel |
|||
Pentium |
Pentium |
64 |
Ввод- |
Сетевой |
Pro |
Pro |
Мбайт |
вывод |
адаптер |
Pentium |
Pentium |
64 |
Ввод- |
Сетевой |
Pro |
Pro |
Мбайт |
вывод |
адаптер |
|
64-битная локальная шина |
|
||
|
|
а |
|
б |
Рис. 8.30. Система Intel/Sandia Option Red: плата kestrel (а); сеть (б)
Систему можно логически разделить на 4 части: сервис, вычисление, ввод-вы- вод и система. Сервисные узлы — это машины UNIX общего назначения с разделением времени, которые позволяют программистам писать и отлаживать свои программы. Вычислительные узлы запускают большие приложения. Они запускают невсюсистему UNIX,атолькомикроядро, которое называетсякугуаром(coguar)1. Узлы ввода-вывода управляют 640 дисками, содержащими более 1 Тбайт данных. Есть два независимых набора узлов ввода-вывода. Узлы первого типа предназначены для секретной военной работы, а узлы второго типа — для несекретной работы. Эти два набора вводятся и удаляются из системы вручную, поэтому в каждый момент времени подсоединен только один набор узлов, чтобы предотвратить утечку информации с секретныхдисков на несекретные диски. Наконец, системные узлы используются для загрузки системы.
COW — Clusters of Workstations (кластеры рабочих станций)
Второй тип мультикомпьютеров — это системы COW (Cluster ofWorkstations — кластер рабочих станций) или NOW (Network of Workstations — сеть рабочих станций) [8,90]. Обычно он состоит из нескольких сотен персональных компьютеров или рабочих станций, соединенных посредством сетевых плат. Различие между МРР и COW аналогично разнице между большой вычислительной машиной и персональнымкомпьютером. Уобоихестьпроцессор, ОЗУ,диски, операционная система
ит. д. Но в большой вычислительной машине все это работает гораздо быстрее (за исключением, может быть, операционной системы). Однако они применяются
иуправляются по-разному. Это же различие справедливо для МРР и COW.
Процессоры в МРР — это обычные процессоры, которые любой человек может купить. В системе ТЗЕ используются процессоры Alpha; в системе Option Red — процессоры Pentium Pro. Ничего специфического. Используются обычные динамические ОЗУ и система UNIX.
1Кугуар (или пума), как известно, очень быстрое животное. Видимо, этот термин был использован
сцельюотметитьвысокоебыстродействиемикроядра. —Примеч. научи,ред.

Мультикомпьютеры с передачей сообщений |
|
627 |
Исторически система МРР отличалась высокоскоростной сетью. Но с появлением коммерческих высокоскоростных сетей это отличие начало сглаживаться. Например, исследовательская группа автора данной книги собрала систему COW, которая называется DAS (Distributed ASCII Supercomputer). Она состоит из 128 узлов, каждый из которых содержит процессор Pentium Pro на 200 МГц и ОЗУ на 128 Мбайт (см. http://www.cs.vu.nl/~baL/das.htmt). Узлы организованы в 2-мер- ный тор. Каналы связи могут передавать информацию со скоростью 160 Мбайт/с в обоих направлениях одновременно. Эти характеристики практически не отличаются от характеристик машины Option Red: скорость передачи информации по каналам связи в два раза ниже, но размер ОЗУ каждого узла в два раза больше. Единственное существенное различие состоит в том, что бюджет Sandia был значительно больше. Технически эти две системы практически не различаются.
Преимущество системы COW над МРР в том, что COW полностью состоит из доступных компонентов, которые можно купить. Эти части выпускаются большими партиями. Эти части, кроме того, существуют на рынке с жесткой конкуренцией, из-за которой производительность растет, а цены падают. Вероятно, системы COW постепенно вытеснят ММР, подобно тому как персональные компьютеры вытеснили большие вычислительные машины, которые применяются теперь только в специализированных областях.
Существует множество различных видов COW, но доминируют два из них: централизованные и децентрализованные. Централизованные системы COW представляют собой кластер рабочих станций или персональных компьютеров, смонтированных в большой блок в одной комнате. Иногда они компонуются более компактно, чем обычно, чтобы сократить физические размеры идлинукабеля. Как правило, эти машины гомогенны и не имеют никаких периферических устройств, кроме сетевых карт и, возможно, дисков. Гордон Белл (Gordon Bell), разработчик PDP-11 и VAX, назвал такие машины «автономными рабочими станциями» (поскольку у них не было владельцев).
Децентрализованная система COW состоит из рабочих станций или персональных компьютеров, которые раскиданы по зданию или по территории учреждения. Большинство из них простаивают много часов в день, особенно ночью. Обычно они связаны через локальную сеть. Они гетерогенны и имеют полный набор периферийных устройств. Самое важное, что многие компьютеры имеют своих владельцев.
Планирование
Возникает вопрос: чем отличается децентрализованная система COW от локальной сети, соединяющей пользовательские машины? Отличие связано с программным обеспечением и не имеет никакого отношения к аппаратному обеспечению. В локальной сети пользователи работают с персональными машинами и используют только их для своей работы. Децентрализованная система COW, напротив, является общим ресурсом, которому пользователи могут поручить работу, требующую для выполнения нескольких процессоров. Чтобы система COW могла обрабатывать запросы от нескольких пользователей, каждому из которых нужно несколько процессоров, этой системе необходим планировщик заданий.
Мультикомпьютеры с передачей сообщений |
629 |
Ethernet и gigabit Ethernet. Они работают со скоростью 10,100 и 1000 Мбит/с (1,25, 12,5 и 125 Мбайт/с)1 соответственно. Все они совместимы относительно среды, формата пакетов и протоколов2. Отличие только в производительности.
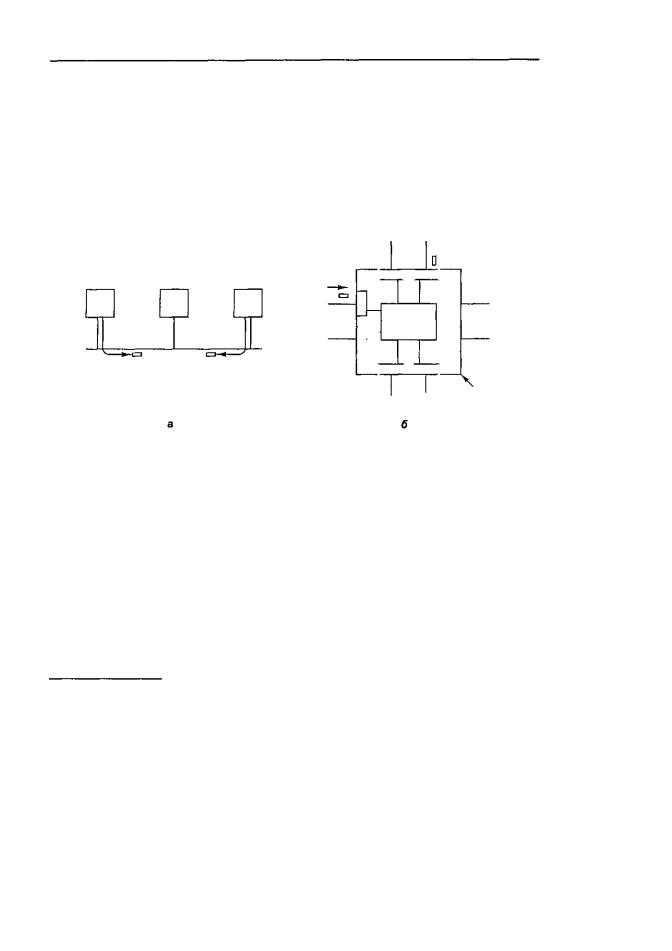
Каждый компьютер в сети Ethernet содержит микросхему Ethernet, обычно на съемной плате. Изначально провод из платы вводился в середину толстого медного кабеля, это называлось «зуб вампира». Позднее появились более тонкие кабели и Т-образные коннекторы. В любом случае платы Ethernet на всех машинах соединены электрически, как будто они соединены пайкой. Схема подсоединения трех машин к сети Ethernet изображена на рис. 8.32, а.
|
|
|
|
|
|
|
|
\ |
Процессор |
Процессор |
Процессор |
|
|
1 |
1 1 |
1 |
|
|
|
|
|
J |
|
Плата |
- С |
|
|
|
|
|
|
|
i: |
||
|
|
|
|
-| |
backplane |
|
||
Пакет, |
|
Пакет, |
|
|
|
|
|
|
|
|
|
1 |
1 1 |
i |
|||
движущийся |
движущийся |
|
|
|||||
|
|
|
|
|
||||
направо |
налево |
Канальная |
|
|
Коммутатор |
|||
|
|
|
|
карта |
|
Ethernet |
|
|
Рис. 8.32. Три компьютера в сети Ethernet (а); коммутатор Ethernet (б)
В соответствии с протоколом Ethernet, если машине нужно послать пакет, сначала она должна проверить, не совершает ли передачу в данный момент какаялибо другая машина. Если кабель свободен, то машина просто посылает пакет. Если кабель занят, то машина ждет окончания передачи и только после этого посылает пакет. Если две машины начинают передачу пакета одновременно, происходит конфликтная ситуация. Обе машины определяют, что произошла конфликтная ситуация, останавливают передачу, затем останавливаются на произвольный период времени и пробуют снова. Если конфликтная ситуация случается во второй раз, они снова останавливаются и снова начинают передачу пакетов, удваивая среднее время ожидания с каждой последующей конфликтной ситуацией.
Дело в том, что «зубы вампира» легко ломаются, а определить неполадку в кабеле очень трудно. По этой причине появилась новая разработка, в которой кабель из каждой машины подсоединяется к сетевому концентратору (хабу). По суще-
1Соотнесение автором скоростных показателей упоминаемых технологий, выраженных отношением скорости передачи бит/с, с отношениями Мбайт/с неправомочно. Ни одна их этих технологий не позволяет передать по сети соответствующее количество байтов за секунду. Даже теоретически возможная скорость для стандарта Ethernet лежит в интервале 800-850 Кбайт/с. Дело в том, что для передачи информации необходимо использовать служебные коды, к тому же передача осуществляется кадрами (фреймами) относительно небольшой длины (1500 байтов), после чего сетевой адаптер обязательно должен освободить среду передачи на фиксированный промежуток времени (с тем, чтобы другие сетевые адаптеры тоже могли воспользоваться средой передачи). — Примеч. научи, ред.
2Это высказывание является чересчур смелым. В действительности совместимость имеет очень много ограничений, и общим у них следует считать метод доступа к среде передачи. — Примеч. научн. ред.

6 3 0 Глава 8. Архитектуры компьютеров параллельного действия
ству, это то же самое, что и в первой разработке, но производить ремонт здесь проще, поскольку кабели можно отсоединять от сетевого концентратора по очереди, пока поврежденный кабель не будет изолирован.
Третья разработка — Ethernet с использованием коммутаторов — показана на рис. 8.32, б. Здесь сетевой концентратор заменен устройством, содержащим высокоскоростную плату backplane, к которой можно подсоединять канальные карты. Каждая канальная карта принимает одну или несколько сетей Ethernet, и разные карты могут воспринимать разные скорости, поэтому classic, fast и gigabit Ethernet могут быть связаны вместе.
Когда пакет поступает в канальную карту, он временно сохраняется там в буфере, пока канальная карта не отправит запрос и не получит доступ к плате backplane, которая функционирует почти как шина. Если пакет был перемещен в канальную карту, к которой подсоединена целевая машина, он может направляться к этой машине. Если каждая канальная карта содержит только один Ethernet и этот Ethernet имеет только одну машину, конфликтных ситуаций больше не возникнет, хотя пакет может быть потерян из-за переполнения буфера в канальной карте. Gigabit Ethernet с использованием коммутаторов с одной машиной на Ethernet и высокоскоростной платой backplane имеет потенциальную производительность (по крайней мере, это касается пропускной способности) в 4 раза меньше, чем каналы связи в машине ТЗЕ, но стоит значительно дешевле.
Но при большом количестве канальных карт обычная плата backplane не сможет справляться с такой нагрузкой, поэтому необходимо подсоединить несколько машин к каждой сети Ethernet, вследствие чего опять возникнут конфликтные ситуации. Однако с точки зрения соотношения цены и производительности сеть на основе gigabit Ethernet с использованием коммутаторов — серьезный конкурент на компьютерном рынке.
Следующая технология связи, которую мы рассмотрим, — это ATM (Asynch- ronousTransferMode—асинхронныйрежимпередачи). ТехнологияATMбыла разработана международным консорциумом телефонных компаний в качестве замены существующей телефонной системы на новую, полностью цифровую. Основная идея проекта состояла в том, чтобы каждый телефон и каждый компьютер в мире связать с помощью безошибочного цифрового битового канала со скоростью передачи данных 155 Мбит/с (позднее 622 Мбит/с). Но осуществить это на практике оказалось не так просто. Тем не менее многие компании сейчас выпускают съемные платы для персональных компьютеров со скоростью передачи данных 155 Мбит/с или 622 Мбит/с. Вторая скорость, ОС-12, хорошо подходит для мультикомпьютеров.
Провод или стекловолокно, отходящее от платы ATM, переходит в переключатель ATM — устройство, похожее на коммутатор Ethernet. В него тоже поступают пакеты и сохраняются в буфере в канальных картах, а затем поступают в исходящую канальную карту для передачи в пункт назначения. Однако у Ethernet и ATM есть существенные различия.
Во-первых, поскольку ATM была разработана для замещения телефонной системы, она представляет собой сеть с маршрутизацией информации. Перед отправкой пакета в пункт назначения исходная машина должна установить виртуальную цепь от исходного пункта через один или несколько коммутаторов ATM в конеч-
Мультикомпьютеры с передачей сообщений |
631 |
ный пункт. Нарис. 8.33. показаныдве виртуальные цепи. В сети Ethernet, напротив, нет никаких виртуальных цепей. Поскольку установка виртуальной цепи занимает некоторое количество времени, каждая машина в мультикомпьютере должна устанавливать виртуальную цепь со всеми другими машинами при запуске и использовать их при работе. Пакеты, отправленные по виртуальной цепи, всегда будут доставлены в правильном порядке, но буферы канальных карт могут переполняться, как и в сети Ethernet с коммутаторами, поэтому доставка не гарантируется.
|
|
Процессор |
|
|
|
|
|
|
|
|
|
|||||||||||
|
|
|
|
|
1 |
2 |
|
|
|
|
|
|
3 |
|
4 |
|
|
|||||
|
|
I |
| | |
| |
Ячейка |
|
L |
|
|
1 |
|
|
||||||||||
|
|
|
|
|
|
|
|
|||||||||||||||
|
|
|
|
|
|
|
|
|||||||||||||||
5 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
--. Г |
7 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
] |
|
|
|
|
i |
M |
|
6 |
|
|
|
|
|
|
|
|
|
|
|
|
|
Пакет |
|
|
|
|
|L |
Q |
||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
/ I |
|
1 I |
1 |
|
|
г |
|
|
1 |
гг"Л |
|
|
|||||||||
|
|
|
|
|
|
|
|
|||||||||||||||
|
|
|
1 |
1 |
|
1 |
11 1 1 |
1 |
|
|||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||
|
Порт |
|
|
|
|
|
|
|
Виртуальная цепь |
|
|
•-{ |
|
|
||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||
|
h |
L |
|
|
i |
I |
J |
|
|
L_ J |
Lj.4J |
i |
|
|||||||||
_9^ |
|
|
|
|
|
|
|
|
|
|
|
С |
|
] --, |
|
! |
11 |
|||||
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||
10 |
|
|
|
|
|
|
|
|
|
|
|
|
|
i|li |
12 |
|||||||
|
|
|
|
—i |
|
|
|
|
|
|
|
|
|
|
|
|
j |
L |
|
|||
|
|
|
|
I — |
|
|
|
|
Г |
|
|
1 |
|
|
||||||||
|
|
г |
|
|
|
|
|
|
|
^ |
|
r- |
|
|
||||||||
атоpATM |
|
|
|
13 |
14 |
|
|
|
|
|
|
15 |
1f5 |
|
|
|||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||
Рис.8.33. 16процессоров,связанныхчетырьмяпереключателямиATM. Пунктиром показаны две виртуальные цепи (канала)
Во-вторых, Ethernet может передавать целые пакеты (до 1500 байтов данных) одним блоком. В ATM все пакеты разбиваются на ячейки по 53 байта. Пять из этих байтов — это поля заголовка, которые сообщают, какой виртуальной цепи принадлежит ячейка, что это за ячейка, каков ее приоритет, а также некоторые другие сведения. Полезная нагрузка составляет 48 байтов. Разбиение пакетов на ячейки и их компоновку в конце пути совершает аппаратное обеспечение.
Наш третий пример — сеть Myrinet — съемная плата, которая производится одной калифорнийской компанией и пользуется популярностью у разработчиков систем COW [18]. Здесь используется та же модель, что и в Ethernet и ATM, где каждая съемная плата подсоединяется к коммутатору, а коммутаторы могут соединяться в любой топологии. Каналы связи сети Myrinet дуплексные, они передают информацию со скоростью 1,28 Гбит/с в обоих направлениях. Размер пакетов неограничен, а каждый коммутатор представляет собой полное пересечение, что дает малое время ожидания и высокую пропускную способность.
Myrinet пользуется популярностью у разработчиков систем COW, поскольку платы в этой сети содержат программируемый процессор и большое ОЗУ. Хотя

6 3 2 Глава 8. Архитектуры компьютеров параллельного действия
Myrinet появилась со своей стандартной операционной системой, многие исследовательские группы уже разработали свои собственные операционные системы. У них появились дополнительные функции и повысилась производительность (см., например, [17,107,155]). Из типичных особенностей можно назвать защиту, управление потоком, надежное широковещание и мультивещание, а также возможность запускать часть кода прикладной программы на плате.
Связное программное обеспечение для мультикомпьютеров
Для программирования мультикомпьютера требуется специальное программное обеспечение (обычно это библиотеки), чтобы обеспечить связь между процессами и синхронизацию. В этом разделе мы расскажем о таком программном обеспечении. Отметим, что большинство этих программных пакетов работают в системах МРРиCOW.
Всистемах с передачей сообщений два и более процессов работают независимо друг от друга. Например, один из процессов может производить какие-либо данные, а другой или несколько других процессов могут потреблять их. Если у отправителя есть еще данные, нет никакой гарантии, что получатель (получатели) готов принять эти данные, поскольку каждый процесс запускает свою программу.
Вбольшинстве систем с передачей сообщений имеется два примитива send и receive, но возможны и другие типы семантики. Ниже даны три основных варианта:
1.Синхронная передача сообщений.
2.Буферная передача сообщений.
3.Неблокируемая передача сообщений.
Синхронная передача сообщений. Если отправитель выполняет операцию send, а получатель еще не выполнил операцию recei ve, то отправитель блокируется до тех пор, пока получатель не выполнит операцию receive, а в это время сообщение копируется. Когда к отправителю возвращается управление, он уже знает, что сообщение было отправлено и получено. Этот метод имеет простую семантику и не требует буферизации. Но у него есть большой недостаток: отправитель блокируется до тех пор, пока получатель не примет и не подтвердит прием сообщения.
Буферная передача сообщений. Если сообщение отправляется до того, как получатель готов его принять, это сообщение временно сохраняется где-либо, например в почтовом ящике, и хранится там, пока получатель не возьмет его оттуда. При таком подходе отправитель может продолжать работу после операции send, даже если получатель в этот момент занят. Поскольку сообщение уже отправлено, отправитель может снова использовать буфер сообщений сразу же. Такая схема сокращает время ожидания. Вообще говоря, как только система отправила сообщение, отправитель может продолжать работу. Однако нет никаких гарантий, что сообщение было получено. Даже при надежной системе коммуникаций получатель мог сломаться еще до получения сообщения.
Неблокируемая передача сообщений. Отправитель может продолжать работу сразу после вызова. Библиотека только сообщает операционной системе, что