

AOM / Tannenbaum
.pdfМультипроцессоры с памятью совместного использования |
613 |
1 М строк, в каталоге содержится 1 М элементов, по одному элементу на каждую строку. Каждый элемент содержит битовое отображение по одному биту на кластер. Этот бит показывает, имеется ли в данный момент строка данного кластера в кэшпамяти. Кроме того, элементсодержит 2-битное поле, которое сообщаето состоянии строки.
1 М элементов по 18 битов каждый означает, что общий размер каждого каталога превышает 2 Мбайт. При наличии 16 кластеров вся память каталога будет немного превышать 36 Мбайт, что составляет около 14% от 256 Мбайт. Если число процессоров на кластер возрастает, объем памяти каталога не меняется. Большое число процессоров на каждый кластер позволяет погашать стоимость памяти каталога, а также контроллера шины при наличии большого числа процессоров, сокращая стоимость на каждый процессор. Именно поэтому каждый кластер имеет несколько процессоров.
Каждый кластер в DASH связан с интерфейсом, который дает возможность кластеру обмениваться информацией с другими кластерами. Интерфейсы связаны через межкластерные каналы в прямоугольную решетку, как показано нарис. 8.25, а. Чем больше добавляется кластеров в систему, тем больше нужно добавлять межкластерных каналов, поэтому пропускная способность системы возрастает. В системе используется маршрутизация «червоточина», поэтому первая часть пакета может быть направлена дальше еще до того, как получен весь пакет, что сокращает задержку в каждом транзитном участке. Существует два набора межкластерных каналов: один — для запрашивающих пакетов, а другой — для ответных пакетов (на рисунке это не показано). Межкластерные каналы нельзя отслеживать.
Каждая строка кэш-памяти может находиться в одном из трех следующих состояний:
1.UNCACHED (некэшированная) — строка находится только в памяти.
2.SHARED (совместно используемая) — память содержит новейшие данные; строка может находиться в нескольких блоках кэш-памяти.
3.MODIFIED(измененная) —строка,содержащаясявпамяти,неправильная; данная строка находится только в одной кэш-памяти.
Состояние каждой строки кэш-памяти содержится в поле Состояние в соответствующем элементе каталога, как показано на рис. 8.25, б.
Протоколы DASH основаны на обладании и признании недействительности. В каждый момент у каждой строки имеется уникальный владелец. Для строк в состоянии UNCHANGED или SHARED владельцем является собственный кластер данной строки. Для строк в состоянии MODIFIED владельцем является тот кластер, в котором содержится единственная копия этой строки. Прежде чем записать что-либо в строку в состоянии SHARED, нужно найти и объявить недействительными все существующие копии.
Чтобы понять, как работает этот механизм, рассмотрим, как процессор считывает слово из памяти. Сначала он проверяет свою кэш-память. Если там слова нет, на локальную шину кластера передается запрос, чтобы узнать, содержит ли какойнибудь другой процессор того же кластера строку, в которой присутствует нужное слово. Если да, то происходит передача строки из одной кэш-памяти в другую. Если строка находится в состоянии SHARED, то создается ее копия. Если строка нахо-

6 1 4 Глава 8. Архитектуры компьютеров параллельного действия
дится в состоянии MODIFIED, нужно проинформировать исходный каталог, что строка теперь SHARED. В любом случае слово берется из какой-то кэш-памяти, но это не влияет на битовое отображение каталогов (поскольку каталог содержит 1 бит на кластер, а не 1 бит на каждый процессор).
Если нужная строка не присутствует ни в одной кэш-памяти данного кластера, то пакет с запросом отправляется в исходный кластер, содержащий данную строку. Этот кластер определяется по 4 старшим битам адреса памяти, и им вполне может оказаться кластер запрашивающей стороны. В этом случае сообщение физически не посылается. Аппаратное обеспечение в исходном кластере проверяет свои таблицы и выясняет, в каком состоянии находится строка. Если она UNCACHED или SHARED, аппаратное обеспечение, которое управляет каталогом, вызывает эту строку из глобальной памяти и посылает ее обратно в запрашивающий кластер. Затем аппаратное обеспечение обновляет свой каталог, помечая данную строку как сохраненную в кэш-памяти кластера запрашивающей стороны.
Если нужная строка находится в состоянии MODIFIED, аппаратное обеспечение находит кластер, который содержит эту строку, и посылает запрос туда. Затем кластер, который содержит данную строку, посылает ее в запрашивающий кластер и помечает ее копию как SHARED, поскольку теперь эта строка находится более чем в одной кэш-памяти. Он также посылает копию обратно в исходный кластер, чтобы обновить память и изменить состояние строки на SHARED.
Запись происходит по-другому. Перед тем как осуществить запись, процессор должен убедиться, что он является единственным обладателем данной строки кэшпамяти в системе. Если в кэш-памяти данного процессора уже есть эта строка и она находится в состоянии MODIFIED, то запись можно осуществить сразу же. Если строка в кэш-памяти есть, но она находится в состоянии SHARED, то сначала в исходный кластер посылается пакет, чтобы объявить все остальные копии недействительными.
Если нужной строки нет в кэш-памяти данного процессора, этот процессор посылает запрос на локальную шину, чтобы узнать, нет ли этой строки в соседних процессорах. Если данная строка там есть, то она передается из одной кэш-памяти в другую. Если эта строка SHARED, то все остальные копии должны быть объявлены недействительными.
Если строка находится где-либо еще, пакет посылается в исходный кластер. Здесь может быть три варианта. Если строка находится в состоянии UNCACHED, она помечается как MODIFIED и отправляется к запрашивающему процессору. Если строка находится в состоянии SHARED, все копии объявляются недействительными, и после этого над строкой совершается та же процедура, что и над UNCASHED строкой. Если строка находится в состоянии MODIFIED (изменена), то запрос направляется в тот кластер, в котором строка содержится в данный момент. Этот кластер удовлетворяет запрос, а затем объявляет недействительной свою собственную копию.
Сохранить согласованность памяти в системе DASH довольно трудно, и происходит это очень медленно. Для одного обращения к памяти порой нужно отправлять большое количество сообщений. Более того, чтобы память была согласованной, доступ нельзя завершить, пока прием всех пакетов не будет подтвержден, а это плохо влияет на производительность. Для разрешения этих проблем в систе-

6 1 6 Глава 8. Архитектуры компьютеров параллельного действия
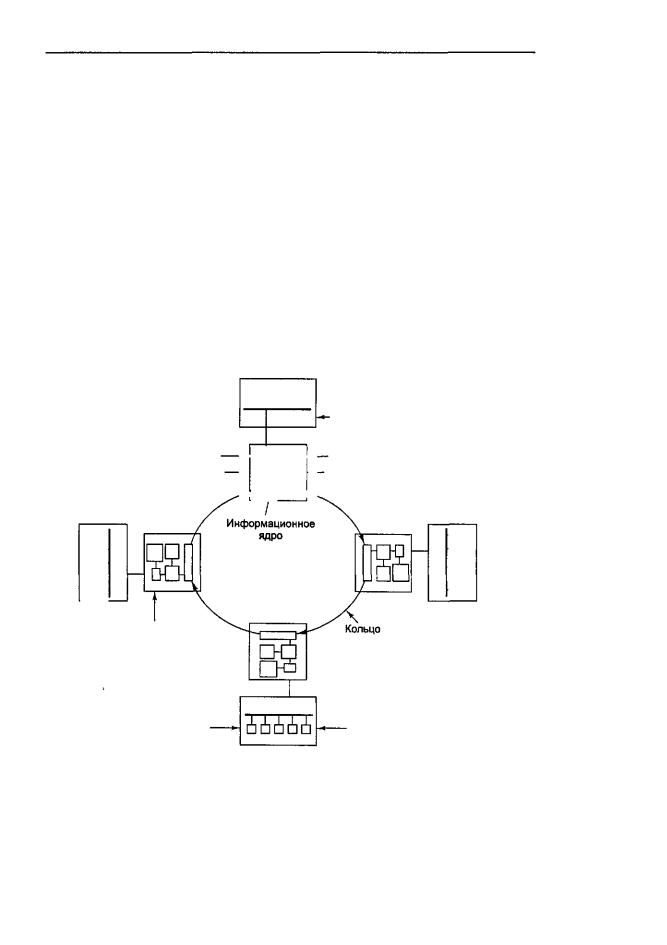
плата IQ-Link, соединяет все платы quad board в один мультипроцессор. Ее главная задача — реализовать протокол SCI. Каждая плата IQ-Link содержит 32 Мбайт кэш-памяти, каталог, который следит за тем, что находится в кэш-памяти, интерфейс с локальной шиной платы quad board и микросхему, называемую информационным ядром, соединяющую плату IQ-Link с другими платами IQ-Link. Эта микросхема подкачивает данные от входа к выходу, сохраняя те данные, которые направляются в данный узел, и передавая все прочие данные далее без изменений.
Все платы IQ-Link в совокупности формируют кольцо, как показано на рис. 8.26. В данной разработке присутствует два уровня протокола когерентности кэширования. Протокол SCI поддерживает непротиворечивость всех кэшей платы IQ-Link, используя это кольцо. Протокол MESI используется для сохранения непротиворечивости между четырьмя процессорами и кэш-памятью на 32 Мбайт в каждом узле.
В качестве связи между платами quad board используется интерфейс SCI. Этот интерфейс был разработан для того, чтобы заменить шину в больших мультипроцессорах и мультикомпьютерах (например, NUMA-Q). SCI поддерживает непротиворечивость кэшей, которая необходима в мультипроцессорах, а также позволяет быстро передавать блоки, что необходимо в мультикомпьютерах. SCI выдерживает нагрузку до 64 К узлов, адресное пространство каждого из которых может быть до 248 байтов. Самая большая система NUMA-Q состоит из 63 плат quad board, которые содержат 252 процессора и почти 238 байтов физической памяти. Как видим, возможности SCI гораздо выше.
Кольцо, которое соединяет платы IQ-Link, соответствует протоколу SCI. В действительности это вообще не кольцо, а отдельные двухточечные кабели. Ширина кабеля составляет 18 битов: 1 бит синхронизации, 1 флаговый бит и 16 битов данных. Все они передаются параллельно. Каналы синхронизируются с тактовой частотой 500 МГц, при этом скорость передачи данных составляет 1 Гбайт/с. По каналам передаются пакеты. Каждый пакет содержит заголовок из 14 байтов, 0, 16, 64 или 256 байтов данных и контрольную сумму на 2 байта. Трафик состоит из запросов и ответов.
Физическая память в машине NUMA-Q 2000 распределена по узлам, так что каждая страница памяти имеет свою собственную машину. Каждая плата quad board может вмещать до 4 Гбайт ОЗУ. Размер строки кэш-памяти равен 64 байтам, поэтому каждая плата quad board содержит 226 строк кэш-памяти. Когда строка не используется, она находится только в одном месте — в собственной памяти.
Однако строки могут находиться в нескольких разных кэшах, поэтому для каждого узла должна существовать таблица локальной памяти из 226 элементов, по которой можно находить местоположение строк. Один из возможных вариантов — иметь на каждый элемент таблицы битовое отображение, которое показывает, какие платы IQ-Link содержат эту строку. Но в SCI не используется такое битовое отображение, поскольку оно плохо расширяется. (Напомним, что SCI может выдерживать нагрузку до 64 К узлов, и иметь 226 элементов по 64 К битов каждый было бы слишком накладно.)
Вместо этого все копии строки кэш-памяти собираются в дважды связанный список. Элемент в таблице локальной памяти исходного узла показывает, в каком узле содержится головная часть списка. В машине NUMA-Q 2000 достаточно 6-бит- ного номера, поскольку здесь может быть максимум 63 узла. Для системы SCI максимального размера достаточно будет 16-битного номера. Такая схема подходит
Мультипроцессоры с памятью совместного использования |
6 1 7 |
для больших систем гораздо лучше, чем битовое отображение. Именно это свойство делает SCI более расширяемой по сравнению с системой DASH.
Кроме таблицы локальной памяти, каждая плата IQ-Link содержит каталог с одним элементом для каждой строки кэш-памяти, которую плата в данный момент содержит. Поскольку размер кэш-памяти составляет 32 Мбайт, а строка кэш-памяти включает 64 байта, каждая плата IQ-Link может содержать до 219 строк кэш-памяти. Поэтому каждый каталог содержит 21Э элементов, по одному элементу на каждую строку кэш-памяти.
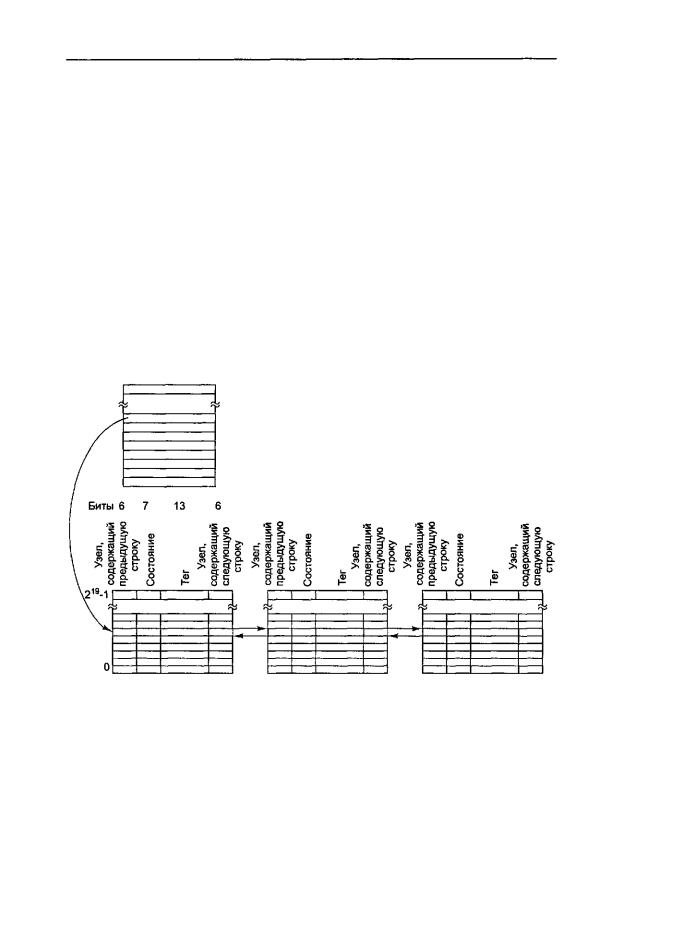
Если строка находится только в одной кэш-памяти, то тот узел, в котором находится строка, указывается в таблице локальной памяти исходного узла. Если после этого данная строка появится в кэш-памяти другого узла, то в соответствии с новым протоколом исходный каталог будет указывать на новый элемент, который, в свою очередь, указывает на старый элемент. Таким образом формируется двухэлементный список. Все новые узлы, содержащие ту же строку, прибавляются к началу списка. Следовательно, все узлы, которые содержат эту строку, связываются в сколь угодно длинный список. На рис. 8.27 проиллюстрирован этот процесс (в данном случае строка кэш-памяти содержится в узлах 4, 9 и 22).
Таблица локальной памяти в узле
Каталог кэш-памяти узла 4 Каталог кэш-памяти узла 9 Каталог кэш-памяти узла 22
Рис. 8.27. Протокол SCI соединяет всехдержателей данной строки в дважды связанный список. Вданном примерестроканаходитсяодновременновтрехузлах
Каждый элемент каталога состоит из 36 битов. Шесть битов указывают на узел, который содержит предыдущую строку цепочки. Следующие шесть битов указывают на узел, содержащий следующую строку цепочки. Ноль указывает на конец цепочки, и именно поэтому максимальный размер системы составляет 63 узла, а не 64. Следующие 7 битов предназначены для записи состояния строки.

6 1 8 Глава 8. Архитектуры компьютеров параллельного действия
Последние 13 битов — это тег (нужен для идентификации строки). Напомним, что самая большая система NUMA-Q2000 содержит 63х232=238 байтов ОЗУ, поэтому имеется почти 232 строк кэш-памяти. Все кэши прямого отображения, поэтому 232 строк отображаются на 219 элементов кэш-памяти, существует 213 строк, которые отображаются на каждый элемент. Следовательно, 13-битный тег нужен для того, чтобы показывать, какая именно строка находится там в данный момент.
Каждая строка имеет фиксированную позицию только в одном блоке памяти (исходном). Эти строки могут находиться в одном из трех состояний: UNCACHED (некэшированном), SHARED (совместногоиспользования) и MODIFIED (измененном). В протоколе SCI эти состояния называются HOME, FRESH и GONE соответственно, но мы во избежание путаницы будем использовать прежнюю терминологию. Состояние UNCACHED означает, что строка не содержится ни в одном из кэшей на плате IQ-Link, хотя она может находиться в локальной кэш-памя- ти на той же самой плате quad board. Состояние SHARED означает, что строка находится по крайней мере в одной кэш-памяти платы IQ-Link, а память содержит обновленные данные. Состояние MODIFIED означает, что строка находится в кэш-памяти на какой-то плате IQ-Link, но, возможно, эта строка была изменена, поэтому память может содержать устаревшие данные.
Блоки кэш-памяти могут находиться в одном из 29 устойчивых состояний или
водном из переходных состояний (их более 29). Для записи состояния каждой строки необходимо 7 битов (рис. 8.27). Каждое устойчивое состояние показывается двумя полями. Первое поле указывает, где находится строка — в начале списка,
вконце, в середине или вообще является единственным элементом списка. Второе поле содержит информацию о том, изменялась ли строка, находится ли она только
вэтой кэш-памяти и т. п.
Впротоколе SCI определены 3 операции со списком: добавление узла к списку, удаление узла из списка и очистка всех узлов кроме одного. Последняя операция нужна в том случае, если разделяемая строка изменена и становится единственной.
Протокол SCI имеет три варианта сложности. Протокол минимальной степени сложности разрешает иметь только одну копию каждой строки в кэш-памяти (см. рис. 8.24). В соответствии с протоколом средней степени сложности каждая строка может кэшироваться в неограниченном количестве узлов. Полный протокол включает различные особенности для увеличения производительности. В системе NUMA-Q используется протокол средней степени сложности, поэтому ниже мы рассмотрим именно его.
Разберемся, как обрабатывается команда READ. Если процессор, выполняющий эту команду, не может найти нужную строку на своей плате, то плата IQ-Link посылает пакет исходной плате IQ-Link, которая затем смотрит на состояние этой строки. Еслисостояние UNCACHED,онопревращаетсявSHARED,инужнаястрока берется из основной памяти. Затем таблица локальной памяти в исходном узле обновляется. После этого таблица содержит одноэлементный список, указывающий на узел, в кэш-памяти которого в данный момент находится строка.
Предположим, что состояние строки SHARED. Эта строка также берется из памяти, и ее номер сохраняется в элементе каталога в исходном узле. Элемент каталога в запрашивающем узле устанавливается на другое значение — чтобы указывать на старый узел. Эта процедура увеличивает список на один элемент. Новая кэш-память становится первым элементом.

Мультипроцессоры с памятью совместного использования |
619 |
Представим теперь, что требуемая строка находится в состоянии MODIFIED. Исходный каталог не может вызвать эту строку из памяти, поскольку в памяти содержится недействительная копия. Вместо этого исходный каталог сообщает запрашивающей плате IQ-Link, в какой кэш-памяти находится нужная строка, и отдает приказ вызвать строку оттуда. Каталог также изменяет элемент таблицы локальной памяти, поскольку теперь он должен указывать на новое местоположение строки.
Обработка команды WRITE происходит немного по-другому. Если запрашивающий узел уже находится в списке, он должен удалять все остальные элементы, чтобы остаться в списке единственным. Если его нет в списке, он должен удалить все элементы, а затем войти в список в качестве единственного элемента. В любом случае в конце концов этот элемент остается единственным в списке, а исходный каталог указывает на этот узел. В действительности обработка команд READ и WRITE довольно сложна, поскольку протокол должен работать правильно, даже если несколько машин одновременно выполняют несовместимые операции на одной линии. Все переходные состояния были введены именно для того, чтобы протокол работал правильно даже во время одновременно выполняемых операций. В этой книге мы не можем изложить полное описание протокола. Если вам это необходимо, обратитесь к стандарту IEEE 1596.
Мультипроцессоры СОМА
Машины NUMA и CC-NUMA имеют один большой недостаток: обращения к удаленной памяти происходят гораздо медленнее, чем обращения к локальной памяти. В машине CC-NUMA эта разница в производительности в какой-то степени нейтрализуется благодаря использованию кэш-памяти. Однако если количество требуемых удаленных данных сильно превышает вместимость кэш-памяти, промахи будут происходить постоянно и производительность станет очень низкой.
Мы видим, что машины UMA, например Sun Enterprise 10000, имеют очень высокую производительность, но ограничены в размерах и довольно дорого стоят. Машины NUMA могут расширяться до больших размеров, но в них требуется ручное или полуавтоматическое размещение страниц, а оно не всегда проходит удачно. Дело в том, что очень трудно предсказать, где какие страницы могут понадобиться, и кроме того, страницы трудно перемещать из-за большого размера. Машины CC-NUMA, например Sequent NUMA-Q, могут работать с очень низкой производительностью, если большому числу процессоров требуется много удаленных данных. Так или иначе, каждая из этих разработок имеет существенные недостатки.
Однако существует процессор, в котором все эти проблемы разрешаются за счет того, что основная память каждого процессора используется как кэш-память. Такая разработка называется СОМА (Cache Only Memory Access). В ней страницы не имеют собственных фиксированных машин, как в системах NUMA и CC-NUMA.
Вместо этого физическое адресное пространство делится на строки, которые перемещаются по системе в случае необходимости. Блоки памяти не имеют собственных машин. Память, которая привлекает строки по мере необходимости, называется attraction memory. Использование основной памяти в качестве большой кэш-памяти увеличивает частоту успешных обращений в кэш-память, а следовательно, и производительность.

6 2 0 Глава 8. Архитектуры компьютеров параллельного действия
К сожалению, ничего идеального не бывает. В системе СОМА появляется две новых проблемы:
1.Как размещаются строки кэш-памяти?
2.Если строка удаляется из памяти, что произойдет, если это последняя копия?
Первая проблема связана со следующим фактом. Если блок управления памятью транслировал виртуальный адрес в физический и если строки нет в аппаратной кэш-памяти, то очень трудно определить, есть ли вообще эта строка в основной памяти. Аппаратное обеспечение здесь не поможет, поскольку каждая страница состоит из большого количества отдельных строк кэш-памяти, которые перемещаются в системе независимо друг от друга. Даже если известно, что строка отсутствует в основной памяти, как определить, где она находится? В данном случае нельзя спросить об этом собственную машину, поскольку таковой машины в системе нет.
Было предложено несколько решений этой проблемы. Можно ввести новое аппаратное обеспечение, которое будет следить за тегом каждой строки кэш-памя- ти. Тогда блок управления памятью может сравнивать тег нужной строки с тегами всех строк кэш-памяти, пока не обнаружит совпадение.
Другое решение — отображать страницы полностью, но при этом не требовать присутствия всех строк кэш-памяти. В этом случае аппаратному обеспечению понадобится битовое отображение для каждой страницы, где один бит для каждой строки указывает на присутствие или отсутствие этой строки. Если строка присутствует, она должна находиться в правильной позиции на этой странице. Если она отсутствует, то любая попытка использовать ее вызовет прерывание, что позволит программному обеспечению найти нужную строку и ввести ее.
Таким образом, система будет искать только те строки, которые действительно находятся в удаленной памяти. Одно из решений — предоставить каждой странице собственную машину (ту, которая содержит элемент каталога данной страницы, а не ту, в которой находятся данные). Затем можно отправить сообщение в собственную машину, чтобы найти местоположениеданной строки. Другое решение — организовать память в виде дерева и осуществлять поиск по направлению вверх, пока не будет обнаружена требующаяся строка.
Вторая проблема связана с удалением последней копии. Как и в машине ССNUMA, строка кэш-памяти может находиться одновременно в нескольких узлах. Если происходит промах кэша, строку нужно откуда-то вызвать, а это значит, что ее нужно отбросить. А что произойдет, если выбранная строка окажется последней копией? В этом случае ее нельзя отбрасывать.
Одно из возможных решений — вернуться к каталогу и проверить, существуют ли другие копии. Если да, то строку можно смело выбрасывать. Если нет, то ее нужно переместить куда-либо еще. Другое решение — пометить одну из копий каждой строки кэш-памяти как главную копию и никогда ее не выбрасывать. При таком подходе не требуется проверка каталога. Машина СОМА обещает обеспечить лучшую производительность, чем CC-NUMA, нодело в том, что было построено очень мало машин СОМА, и нужно больше опыта. До настоящего момента создано всего две машины СОМА: KSR-1 [20] и Data Diffusion Machine [53]. Дополнительную информацию о машинах СОМА можно найти в книгах [36, 67,98, 123].

Мультикомпьютеры с передачей сообщений |
621 |
Мультикомпьютеры с передачей сообщений
Как видно из схемы на рис. 8.12, существует два типа параллельных процессоров MIMD: мультипроцессоры и мультикомпьютеры. В предыдущем разделе мы рассматривали мультипроцессоры. Мы увидели, что мультипроцессоры могут иметь разделенную память, доступ к которой можно получить с помощью обычных команд LOAD и STORE. Такая память реализуется разными способами, включая отслеживающие шины, многоступенчатые сети, а также различные схемы на основе каталога. Программы, написанные для мультипроцессора, могут получать доступ к любому месту в памяти, не имея никакой информации о внутренней топологии или схеме реализации. Именно благодаря такой иллюзии мультипроцессоры весьма популярны.
Однако мультипроцессоры имеют и некоторые недостатки, поэтому мультикомпьютеры тоже очень важны. Во-первых, мультипроцессоры нельзя расширить до больших размеров. Чтобы расширить машину Interprise 10000 до 64 процессоров, пришлось добавить огромное количество аппаратного обеспечения.
В Sequent NUMA-Q дошли до 256 процессоров, но ценой неодинакового времени доступа к памяти. Ниже мы рассмотрим два мультикомпьютера, которые содержат 2048 и 9152 процессора соответственно. Через много лет кто-нибудь сконструирует мультипроцессор, содержащий 9000 узлов, но к тому времени мультикомпьютеры будут содержать уже 100 000 узлов.
Кроме того, конфликтная ситуация при обращении к памяти в мультипроцессоре может сильно повлиять на производительность. Если 100 процессоров постоянно пытаются считывать и записывать одни и те же переменные, конфликтная ситуация для различных модулей памяти, шин и каталогов может сильно ударить по производительности.
Вследствие этих и других факторов разработчики проявляют огромный интерес к параллельным компьютерам, в которых каждый процессор имеет свою собственную память, к которой другие процессоры не могут получить прямой доступ. Это мультикомпьютеры. Программы на разных процессорах в мультикомпьютере взаимодействуют друг с другом с помощью примитивов send и receive, которые используются для передачи сообщений (поскольку они не могут получить доступ к памятидругих процессоров с помощью команд LOADи STORE). Эторазличие полностью меняет модель программирования.
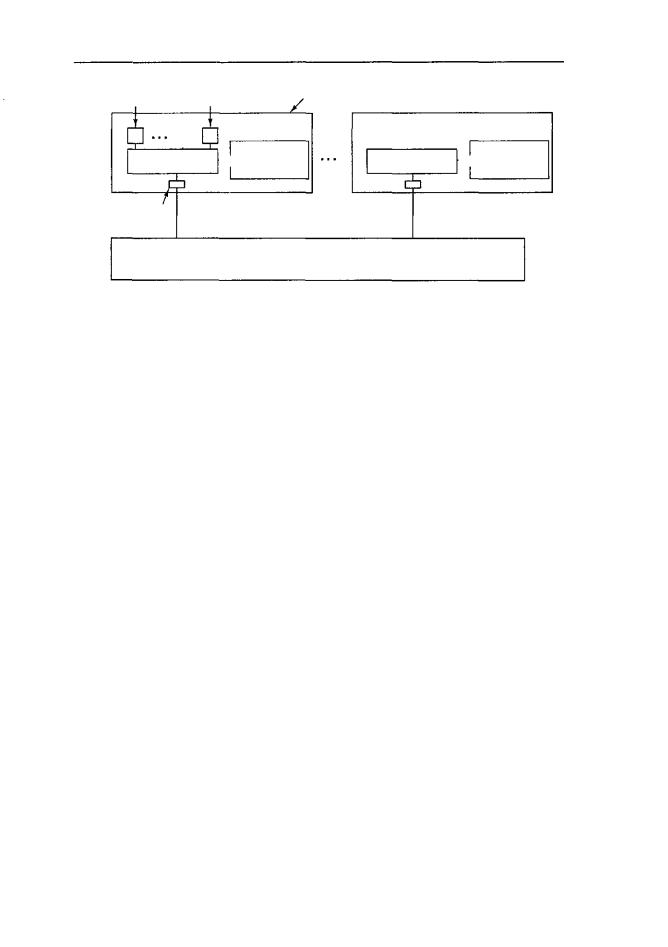
Каждый узел в мультикомпьютере состоит из одного или нескольких процессоров, ОЗУ (общее для процессоров только данного узла), диска и(или) других устройств ввода-вывода, а также процессора передачи данных. Процессоры передачи данных связаны между собой по высокоскоростной коммуникационной сети (см. раздел «Сети межсоединений»). Используется множество различных топологий, схем коммутации и алгоритмов выбора маршрута. Все мультикомпьютеры сходны в одном: когда программа выполняет примитив send, процессор передачи данных получает уведомление и передает блок данных в целевую машину (возможно, после предварительного запроса и получения разрешения). Схема мультикомпьютера показана на рис. 8.28.
6 2 2 Глава 8. Архитектуры компьютеров параллельного действия
Процессор |
Память |
Узел |
|
|
|
|
|
|
|||
|
Р |
|
Диск |
Р-РР |
Диск |
Локальная |
—| и устройства |
Локальная |
—| и устройства |
||
коммуникация |
коммуникация |
||||
|
|
|
ввода-вывода |
|
ввода-вывода |
Процессор
передачиданных
Высокоскоростная коммуникационная сеть
Рис. 8.28. Схемамультикомпьютера
Мультикомпьютеры бывают разных типов и размеров, поэтому очень трудно привести хорошую классификацию. Тем не менее можно назвать два общих типа: МРР и COW. Ниже мы рассмотрим каждый из этих типов.
МРР — процессоры с массовым параллелизмом
МРР (Massively Parallel Processors — процессоры с массовым параллелизмом) — это огромные суперкомпьютеры стоимостью несколько миллионов долларов. Они используются в различных науках и промышленности для выполнения сложных вычислений, для обработки большого числа транзакций в секунду или для хранения больших баз данных и управления ими.
В большинстве таких машин используются стандартные процессоры. Это могут быть процессоры Intel Pentium, Sun UltraSPARC, IBM RS/6000 и DEC Alpha. Отличает мультикомпьютеры то, что в них используется сеть, по которой можно передавать сообщения, с низким временем ожидания и высокой пропускной способностью. Обе характеристики очень важны, поскольку большинство сообщений малы по размеру (менее 256 байтов), но при этом суммарная нагрузка в большей степени зависит от длинных сообщений (более 8 Кбайт).
Еще одна характеристика МРР — огромная производительность процесса вво- да-вывода. Часто приходится обрабатывать огромные массивы данных, иногда терабайты. Эти данные должны быть распределены по дискам, и их нужно перемещать в машине с большой скоростью.
Следующая специфическая черта МРР — отказоустойчивость. При наличии не одной тысячи процессоров несколько неисправностей в неделю неизбежны. Прекращать работу системы из-за неполадок в одном из процессоров было бы неприемлемо, особенно если такая неисправность ожидается каждую неделю. Поэтому большие МРР всегда содержат специальное аппаратное и программное обеспечение для контроля системы, обнаружения неполадок и их исправления.
Было бы неплохо теперь рассмотреть основные принципы разработки МРР, но, по правде говоря, их не так много. МРР представляет собой набор более или