

AOM / Tannenbaum
.pdfСвязывание и загрузка |
543 |
Здесь возникает проблема перераспределения памяти, поскольку каждый объектный модуль на рис. 7.3 занимает отдельное адресное пространство. В машине с сегментированным адресным пространством (например, в Pentium II) каждый объектный модуль теоретически может иметь свое собственное адресное пространство, если его поместить в отдельный сегмент. Однако для Pentium II только система OS/2 поддерживает такую структуру1. Все версии Windows и UNIX поддерживают только одно линейное адресное пространство, поэтому все объектные модули должны быть слиты вместе в одно адресное пространство.
Более того, команды вызова процедур (см. рис. 7.4, а) вообще не будут работать. В ячейке с адресом 400 программист намеревается вызвать объектный модуль В, но поскольку каждая процедура транслируется отдельно, ассемблер не может определить, какой адрес вставлять в команду CALL В. Адрес объектного модуля В не известен до времени связывания. Такая проблема называется проблемой внешней ссылки. Обе проблемы решаются с помощью компоновщика.
Компоновщик сливает отдельные адресные пространства объектных модулей
вединое линейное адресное пространство. Для этого совершаются следующие шаги:
1.Компоновщик строит таблицу объектных модулей и их длин.
2.На основе этой таблицы он приписывает начальные адреса каждому объектному модулю.
3.Компоновщик находит все команды, которые обращаются к памяти, и прибавляет к каждой из них константу перемещения, которая равна начальному адресу этого модуля.
4.Компоновщик находит все команды, которые обращаются к процедурам, и вставляет в них адрес этих процедур.
Ниже показана таблица объектных модулей рис. 7.4, построенная на первом шаге. В ней дается имя, длина и начальный адрес каждого модуля.
Модуль |
Длина |
Начальный адрес |
А |
400 |
100 |
В |
600 |
500 |
С |
500 |
1100 |
D |
300 |
1600 |
На рисунке 7.4, б показано, как адресное пространство выглядит после выполнения компоновщиком всех шагов.
Структура объектного модуля
Объектные модули обычно состоят из шести частей (рис. 7.5). В первой части содержится имя модуля, некоторая информация, необходимая компоновщику (например, длины различных частей модуля), а иногда дата ассемблирования.
Необходимо отметить,что сегментный способ организации был использован только в первой версии OS/2, которая была 16-битовой и разрабатывалась для 286-го микропроцессора. Поэтому относить эту системукPentium II представляетсяневполнеправильно. Начинаяс 1993годавсепоследующиеверсии OS/2 были 32-битовыми и, как и остальные современные операционные системы, перестали поддерживать сегментирование, а стали использовать только страничный механизм. — Примеч. научн.ред.

5 4 4 Глава 7. Уровень языка ассемблера
Конец модуля
Словарь перемещений
Машинныекомандыиконстанты
Таблица внешних ссылок Таблица точек входа Идентификация
Рис. 7.5. Внутренняяструктураобъектного модуля
Вторая часть объектного модуля — это список символов, определенных в модуле, вместе с их значениями. К этим символам могут обращаться другие модули. Например, если модуль состоит из процедуры bigbug, то элемент таблицы будет содержать цепочку символов «bigbug», за которой будет следовать соответствующий адрес. Программист наязыке ассемблера с помощью директивы PUBLIC указывает, какие символьные имена считаются точками входа.
Третья часть объектного модуля состоит из списка символьных имен, которые используются в этом модуле, но определены в других модулях. Здесь также имеется список, который показывает, какие именно символьные имена используются теми или иными машинными командами. Второй список нужен для того, чтобы компоновщик мог вставить правильные адреса в команды, которые используют внешние имена. Процедура может вызывать другие независимо транслируемые процедуры, объявив имена вызываемых процедур внешними. Программист на языке ассемблера с помощьюдирективы EXTERN указывает, какие символы нужно объявить внешними. В некоторых компьютерах точки входа и внешние ссылки объединены в одной таблице.
Третья часть объектного модуля — это машинные команды и константы. Это единственная часть объектного модуля, которая будет загружаться в память для выполнения. Остальные 5 частей используются компоновщиком, а затем отбрасываются еще до начала выполнения программы.
Пятая часть объектного модуля — это словарь перемещений. К командам, которые содержат адреса памяти, должна прибавляться константа перемещения (см. рис. 7.4). Компоновщик сам не может определить, какие слова в четвертой части содержат машинные команды, а какие — константы. Поэтому в этой таблице содержится информация о том, какие адреса нужно переместить. Это может быть битовая таблица, где на каждый бит приходится потенциально перемещаемый адрес, либо явный список адресов, которые нужно переместить.
Шестая часть содержит указание на конец модуля, а иногда — контрольную суммудля определения ошибок, сделанныхво время чтения модуля, и адрес, с которого нужно начинать выполнение.
Большинству компоновщиков требуется два прохода. На первом проходе компоновщик считывает все объектные модули и строит таблицу имен и длин модулей и глобальную таблицу символов, которая состоит из всех точек входа и внешних ссылок. На втором проходе модули считываются, перемещаются в памяти и связываются.

Связывание и загрузка |
545 |
Время принятия решения и динамическое перераспределение памяти
В мультипрограммной системе программу можно считать в основную память, запустить ее на некоторое время, записать на диск, а затем снова считать в основную память для выполнения. В большой системе с большим количеством программ трудно быть уверенным, что программа считывается каждый раз в одно и то же место в памяти.
На рис. 7.6 показано, что произойдет, если уже перемещенная программа (см. рис. 7.4, б) будет загружена в адрес 400, а не в адрес 100, куда ее изначально поместил компоновщик. Все адреса памяти будут неправильными. Более того, информация о перемещении уже давно удалена. Даже если эта информация была бы доступна, перемещать все адреса при каждой перекачке программы было бы неудобно.
Проблема перемещения программ, уже связанных и размещенных в памяти, близко связана с моментом времени, в который совершается финальное связывание символических имен с абсолютными адресами физической памяти. В программе содержатся символические имена для адресов памяти (например, BR L). Время, в которое определяется адрес в основной памяти, соответствующий L, называется временем принятия решения. Существует по крайней мере шесть вариантов для времени принятия решения относительно привязок:
1.Когда пишется программа.
2.Когда программа транслируется.
3.Когда программа компонуется, но еще до загрузки.
4.Когда программа загружается.
5.Когда загружается базовый регистр, который используется для адресации.
6.Когда выполняется команда, содержащая адрес.
Если команда, содержащая адрес памяти, перемещается после связывания, этот адрес будет неправильным (предполагается, что объект, на который происходит ссылка, тоже перемещен). Если транслятор производит исполняемый двоичный код, то связывание происходит во время трансляции и программа должна быть запущена в адресе, в котором этого ожидает транслятор. При применении метода, описанного в предыдущем разделе, во время связывания символические имена соотносятся с абсолютными адресами, и именно по этой причине перемещать программы после связывания нельзя (см. рис. 7.6).
Здесь возникают два вопроса. Первый — когда символические имена связываются с виртуальными адресами, а второй — когда виртуальные адреса связываются с физическими адресами? Только после двух этих операций процесс связывания можно считать завершенным. Когда компоновщик связывает отдельные адресные пространства объектных модулей в единое линейное адресное пространство, он фактически создает виртуальное адресное пространство. Перемещение в памяти и связывание нужно для связи символических имен с определенными виртуальными адресами. Это наблюдение верно независимо от того, используется виртуальная память или нет.

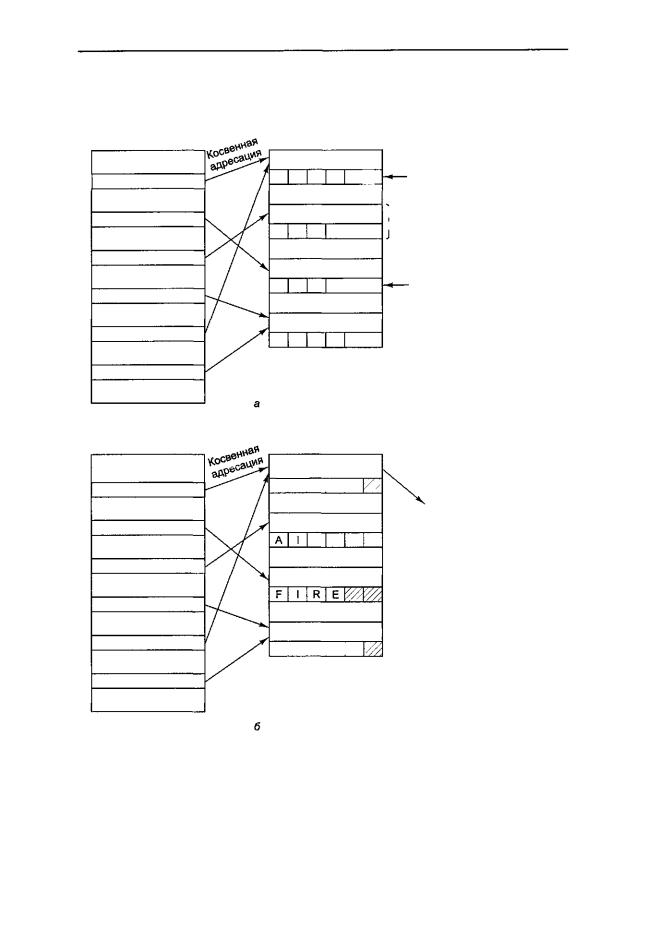

Связывание и загрузка |
549 |
ются к первому слову соответствующего блока, как показано на рис. 7.7, а. Компилятор заполняет это слово либо недействительным адресом, либо специальным набором битов, который вызывает системное прерывание (ловушку).
Когда вызывается процедура в другом сегменте, попытка косвенно обратиться к недействительному слову вызывает системное прерывание компоновщика. Затем компоновщик находит цепочку символов в слове, которое следует за недействительным адресом, и начинает искать пользовательскую директорию для скомпилированной процедуры с таким именем. Затем этой процедуре приписывается виртуальный адрес (обычно в ее собственном сегменте), и этот виртуальный адрес записывается поверх недействительного адреса, как показано на рис. 7.7, б. После этого команда, которая вызвала ошибку, выполняется заново, что позволяет программе продолжать работу с того места, где она находилась до системного прерывания.
Все последующие обращения к этой процедуре будут выполняться без ошибок, поскольку слово с косвенным адресом теперь содержит действительный виртуальный адрес. Следовательно, компоновщик вызывается только тогда, когда некоторая процедура вызывается впервые. После этого вызывать компоновщик уже не нужно.
Динамическое связывание в системе Windows
Все версии операционной системы Windows, в том числе NT, поддерживают динамическое связывание. При динамическом связывании используется специальный файловый формат, который называется DLL (Dynamic Link Library — динамически подключаемая библиотека). Динамически подключаемые библиотеки могут содержать процедуры, данные или и то и другое вместе. Обычно они используются для того, чтобы два и более процессов могли разделять процедуры и данные библиотеки. Большинство файлов DDL имеют расширение .dll, но встречаются
идругие расширения, например .drv (для библиотек драйверов — driver libraries)
и.fon (для библиотек шрифтов — font libraries).
Самая распространенная форма динамически подключаемой библиотеки — библиотека, состоящая из набора процедур, которые могут загружаться в память
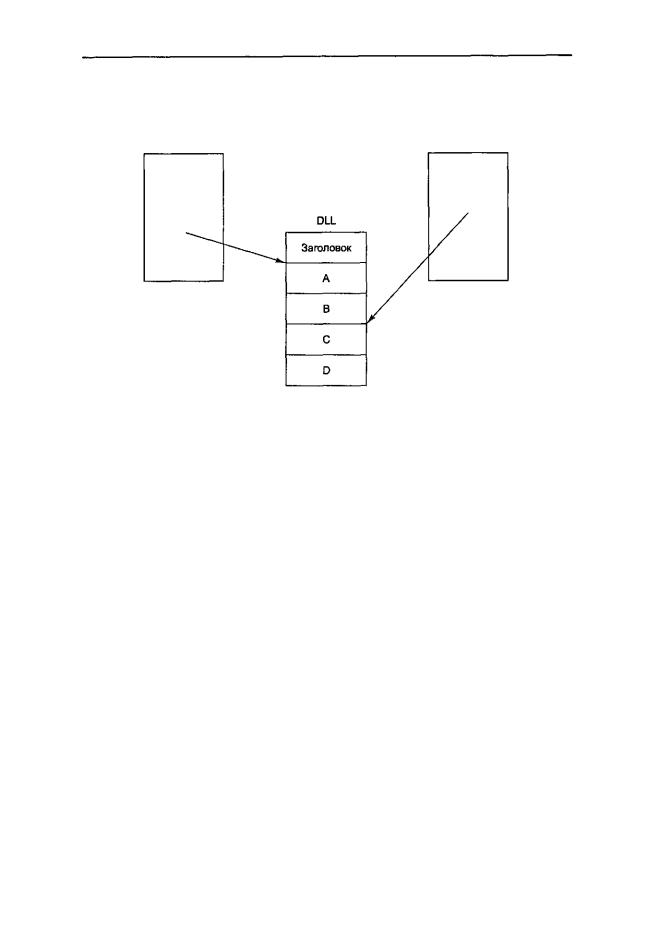
ик которым имеют доступ несколько процессов одновременно. На рис. 7.8 показаны два процесса, которые разделяют файл DLL, содержащий 4 процедуры, А, В, С
иD. Программа 1 использует процедуру А; программа 2 использует процедуру С, хотя они вполне могли бы использовать одну и ту же процедуру.
Файл DLL строится компоновщиком из коллекции входных файлов. Построение файла DDL очень похоже на построение исполняемого двоичного кода, только при создании файла DLL компоновщику передается специальный флаг, который сообщает ему, что создается именно файл DLL. Файлы DLL обычно конструируются из набора библиотечных процедур, которые могут понадобиться нескольким процессорам. Типичными примерами файлов DLL являются процедуры сопряжения с библиотекой системных вызовов Windows и большими графическими библиотеками. Применяя файлы DDL, мы можем сэкономить пространство в памяти и на диске. Если какая-то библиотека была связана с каждой программой, использующей ее, то она будет появляться во многих исполняемых двоичных программах в памяти и на диске, а забивать пространство такими дубликатами неэко-
5 5 0 Глава 7. Уровень языка ассемблера
номно. Если мы будем использовать файлы DLL, то каждая библиотека будет появляться один раз на диске и один раз в памяти.
Пользовательсий |
Пользовательский |
процесс 1 |
процесс 2 |
Рис. 7.8. Два процесса используют один файл DLL
Этот подход, кроме того, упрощает обновление библиотечных процедур и позволяет осуществлять обновление процедур, даже после того как программы, использующие их, были скомпилированы и связаны. Для коммерческих программных пакетов, где пользователям обычно недоступна входная программа, использование файлов DLL означает, что поставщик программного обеспечения может обнаруживать ошибки в библиотеках и исправлять положение, просто распространяя новые файлы DLL по Интернету, причем при этом не требуется производить никаких изменений в основных бинарных программах.
Основное различие между файлом DLL и исполняемой двоичной программой состоит в том, что файл DLL не может запускаться и работать сам по себе (поскольку у него нет ведущей программы). Он также содержит совершенно другую информацию в заголовке. Кроме того, файл DLL имеет несколько дополнительных процедур, не связанных с процедурами в библиотеке. Например, существует одна процедура, которая вызывается автоматически всякий раз, когда новый процесс связывается с файлом DLL, и еще одна процедура, которая вызывается автоматически всякий раз, когда связь процесса с файлом DLL отменяется. Эти процедуры могут выделять и освобождать память или управлять другими ресурсами, которые необходимы файлу DLL.
Программа может установить связь с файлом DLL двумя способами: с помощью неявного связывания и с помощью явного связывания. При неявном связывании пользовательская программа статически связывается со специальным файлом, так называемой библиотекой импорта, которая образована обслуживающей программой (утилитой), извлекающей определенную информацию из файла DLL. Библиотека импорта обеспечивает связующий элемент, который позволяет пользовательской программе получать доступ к файлу DLL. Пользовательская програм-


5 52 Глава 7. Уровень языка ассемблера
чеством ресурсов (например, кредитные карточки, различные приборы и портативные цифровые устройства). Программа на языке ассемблера — это символическая репрезентация программы на машинном языке. Она транслируется на машинный язык специальной программой, которая называется ассемблером.
Если для успеха какого-либо аппарата требуется быстрое выполнение программы, то лучше всего сначала написать программу на языке высокого уровня, затем путем измерений установить, выполнение какой части программы занимает большую часть времени, и переписать на языке ассемблера только эту часть программы. Практика показывает, что часто небольшая часть всей программы занимает большую часть всего времени выполнения этой программы.
Во многих ассемблерах предусмотрены макросы, которые позволяют программистам давать символические имена целым последовательностям команд. Обычно эти макросы могут быть параметризированы прямым путем. Макросы реализуются с помощью алгоритма обработки строковых литералов.
Большинство ассемблеров двухпроходные. Во время первого прохода строится таблица символов для меток, литералов и объявляемых идентификаторов. Символьные имена можно либо не сортировать и искать путем последовательного просмотра таблицы, либо сначала сортировать, а потом применять двоичный поиск, либо хэшировать. Если символьные имена не нужно удалять во время первого прохода, то хэширование — это лучший метод. Во время второго прохода происходит порождение программы. Одни директивы выполняются при первом проходе, а другие — при втором.
Программы, которые ассемблируются независимо друг от друга, можно связать вместе и получить исполняемую двоичную программу, которую можно запускать. Эту работу выполняет компоновщик. Его задачи — это перемещение в памяти и связывание имен. Динамическое связывание — это технология, при которой определенные процедуры не связываются до тех пор, пока они не будут вызваны. Библиотеки коллективного пользования в системе UNIX и файлы DLL (динамически подсоединяемые библиотеки) в системе Windows используют технологию динамического связывания.
Вопросы и задания
1.1% определенной программы отвечает за 50% времени выполнения этой программы. Сравните следующие три стратегии с точки зрения времени программирования и времени выполнения. Предположим, что для написания программы на языке С потребуется 100 человеко-месяцев, а программу на языке ассемблера написать в 10 раз труднее, но зато она работает в 4 раза эффективнее.
1. Вся программа написана на языке С.
2.Вся программа написана на ассемблере.
3.Программа сначала написана на С, а затем нужный 1% программы переписан на ассемблере.
2.Для двухпроходных ассемблеров существуют определенные соглашения. Подходят ли они для компиляторов?