

AOM / Tannenbaum
.pdf

Разработка микроархитектурного уровня |
285 |
прохождение через тракт данных, фиксировано (по крайней мере, с нашей точки зрения). Тем не менее у нас есть некоторая свобода действий, и далее мы используем ее в полной мере.
Еще один вариант усовершенствования — ввести в машину больше параллелизма. В данный момент микроархитектура Mic-2 выполняет большинство операций последовательно. Она помещает значения регистров на шины, ждет, пока АЛУ и схема сдвига обработают их, а затем записывает результаты обратно в регистры. Если не учитывать работу блока выборки команд, никакого параллелизма здесь нет. Внедрение дополнительных средств параллельной обработки дает нам большие возможности.
Как мы уже говорили, длительность цикла определяется временем, необходимым для прохождения сигнала через тракт данных. На рис. 4.2 показано распределение этой задержки между различными компонентами во время каждого цикла.
Вцикле тракта данных есть три основных компонента:
1.Время, которое требуется на передачу значений выбранных регистров в шины АиВ.
2.Время, которое требуется на работу АЛУ и схемы сдвига.
3.Время, которое требуется на передачу полученных значений обратно в регистры и сохранение этих значений.
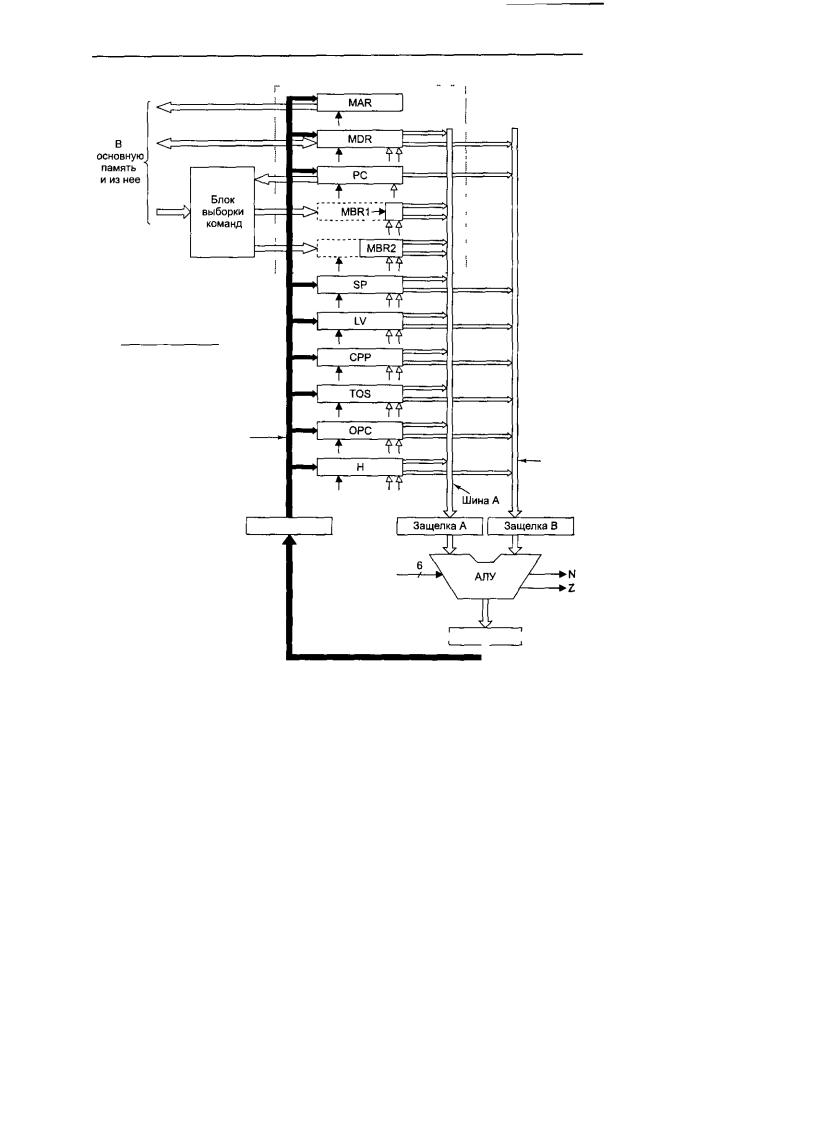
На рис. 4.21 показана новая трехшинная архитектура с блоком выборки команд и тремя дополнительными защелками (регистрами), каждая из которых расположена в середине каждой шины. Эти регистры записываются в каждом цикле. Они делят тракт данных на отдельные части, которые теперь могут функционировать независимо друг от друга. Мы будем называть такую архитектуру конвейерной моделью или Mic-3.
Зачем нужны эти три дополнительных регистра? Ведь теперь для прохождения сигнала через тракт данных требуется три цикла: один — для загрузки регистров А и В, второй — для запуска АЛУ и схемы сдвига и загрузки регистра С, и третий — для сохранения значения регистра-защелки С обратно в нужные регистры. Мы что, сумасшедшие? (Подсказка: нет). Существует целых две причины введения дополнительных регистров:
1. Мы можем повысить тактовую частоту, поскольку максимальная задержка теперь стала короче.
2. Во время каждого цикла мы можем использовать все части тракта данных.
После разбиения тракта данных на три части максимальная задержка прохождения сигнала уменьшается, и в результате тактовая частота может повыситься. Предположим, что если разбить цикл тракта данных на три примерно равных интервала, тактовая частота увеличится втрое. (На самом деле это не так, поскольку мы добавили в тракт данных еще два регистра, но в качестве первого приближения это допустимо.)
Поскольку мы предполагаем, что все операции чтения из памяти и записи в память выполняются с использованием кэш-памяти первого уровня и эта кэшпамять построена из того же материала, что и регистры, то следовательно, операция с памятью занимает один цикл. На практике, однако, этого не так легко достичь.
286 |
Глава4 Микроархитектурный уровень |
Регистры
управления
памятью
Сигналыуправления
АРазрешающий сигнал ' на шину В
АЗапись сигнала
' с шины С в регистр
Шина С
Шина В
Защелка С
Управление
АЛУ
— и Схема сдвигам—
I
Рис.4.21,ТрактданныхстремяшинамивмикроархитектуреMic-3
Второй пункт связан с общей производительностью, а не со скоростью выполнения отдельной команды В микроархитектуре Mic-2 во время первой и третьей части каждого цикла АЛУ простаивает Если разделить тракт данных на три части, то появляется возможность использовать АЛУ в каждом цикле, вследствие чего производительность машины увеличивается в три раза
А теперь посмотрим, как работает тракт данных Mic-З. Перед тем как начать, нужно ввести определенные обозначения для защелок Проще всего назвать за-


2 88 Глава 4. Микроархитектурный уровень
А теперь вернемся к циклу 2. Мы можем разбить микрокоманду swap2 на микрошаги и начать их выполнение. В цикле 2 мы копируем значение SP в регистр В, затем пропускаем значение через АЛУ в цикле 3 и, наконец, сохраняем его в регистре MAR в цикле 4. Пока все хорошо. Должно быть ясно, что если мы сможем начинать новую микрокоманду в каждом цикле, скорость работы машины увеличится в три раза. Такое повышение скорости происходит за счет того, что машина Mic-З производит в три раза больше циклов в секунду, чем Mic-2. Фактически мы построили конвейерный процессор.
К сожалению, мы наткнулись на преграду в цикле 3. Мы бы рады начать микрокоманду swap3, но эта микрокоманда сначала пропускает значение MDR через АЛУ, а значение MDR не будет получено из памяти до начала цикла 5. Ситуация, когда следующий микрошаг не может начаться, потому что перед этим нужно получить результат выполнения предыдущего микрошага, называется реальной взаимозависимостью или RAW-взаимозависимостью (Read After Write — чтение после записи). В такой ситуации требуется считать значение регистра, которое еще не записано. Единственное разумное решение в данном случае — отложить начало микрокоманды swap3 до того момента, когда значение MDR станет доступным, то есть до пятого цикла. Ожидание нужного значения называется простаиванием. После этого мы можем начинать выполнение микрокоманд в каждом цикле, поскольку таких ситуаций больше не возникает, хотя имеется пограничная ситуация: микрокоманда swap6 считывает значение регистра Н в цикле, который следует сразу после записи этого регистра в микрокоманде swap3. Если бы значение этого регистра считывалось в микрокоманде swap5, машине пришлось бы простаивать один цикл.
Хотя программа Mic-З занимает больше циклов, чем программа Mic-2, она работает гораздо быстрее. Если время цикла микроархитектуры Mic-З составляет ДТ наносекунд, то для выполнения команды SWAP машине Mic-З требуется 11ДТ не, а машине Mic-2 нужно 6 циклов по ЗДТ не каждый, то есть всего 18ДТ не. Конвейеризация увеличивает скорость работы компьютера, даже несмотря на то, что один раз приходится простаивать из-за явления взаимозависимости.
Конвейеризация является ключевой технологией во всех современных процессорах, поэтому важно хорошо понимать эту технологию. На рис. 4.22 графически проиллюстрирована конвейеризация тракта данных, изображенного на рис. 4.21. В первой колонке демонстрируется, что происходит во время цикла 1, вторая колонка представляет цикл 2 и т. д. (предполагается, что простаиваний нет). Закрашенная область на рисунке для цикла 1 и команды 1 означает, что блок выборки команд занят вызовом команды 1. В цикле 2 значения регистров, вызванных командой 1, загружаются в А и В, а в это время блок выборки команд занимается вызовом команды 2. Все это также показано с помощью закрашенных серым прямоугольников.
Во время цикла 3 команда 1 использует АЛУ и схему сдвига, регистры А и В загружаются для команды 2, а команда 3 вызывается. Наконец, во время цикла 4 работают все 4 команды одновременно. Сохраняются результаты выполнения команды 1, АЛУ выполняет вычисления для команды 2, регистры А и В загружаются для команды 3, а команда 4 вызывается.

|
|
|
|
Разработка микроархитектурного уровня |
289 |
||||
Блок |
Блок |
|
Блок |
Блок |
|
|
|
||
выборки |
выборки |
|
выборки |
выборки |
|
|
|
||
команд |
команд |
Reg |
команд Reg |
команд |
= : |
Req |
|
||
П= |
|
¥* Reg |
|
1Г4 |
|ГГ=5 |
1 |
|
||
|
|
|
|
||||||
|
|
|
|
||||||
Цикл 1 |
Цикл 2 |
Цикл 3 |
Цикл4 |
Время
Рис. 4.22. Графическое изображение работы конвейера
Если бы мы показали цикл 5 и следующие, модель была бы точно такой же, как в цикле 4: все четыре части тракта данных работали бы независимо друг от друга. Данный конвейер содержит 4 стадии: для вызова команд, для доступа к операндам, для работы АЛУ и для записи результата обратно в регистры. Он похож на конвейер, изображенный на рис. 2.3, а, только у него отсутствует стадия декодирования (расшифровки). Здесь важно подчеркнуть, что хотя выполнение одной команды занимает 4 цикла, в каждом цикле начинается новая команда и завершается предыдущая.
Можно рассматривать схему на рис. 4.22 не вертикально (по колонкам), а горизонтально (по строчкам). При выполнении команды 1 в цикле 1 функционирует блок выборки команд. В цикле 2 значения регистров помещаются на шины А и В. В цикле три происходит работа АЛУ и схемы сдвига. Наконец, в цикле 4 полученные результаты сохраняются в регистрах. Отметим, что имеется 4 доступные части

290 Глава 4. Микроархитектурный уровень
аппаратного обеспечения, и во время каждого цикла определенная команда использует только одну из них, оставляя свободными другие части для других команд.
Проведем аналогию с конвейером на заводе по производству машин. Чтобы изложить основную суть работы такого конвейера, представим, что ровно каждую минуту звучит гонг, и в этот момент все машины передвигаются по линии на один пункт. В каждом пункте рабочие выполняют определенную операцию с машиной, которая находится перед ними, например ставят колеса или тормоза. При каждом ударе гонга (это 1 цикл) одна новая машина поступает на конвейер и одна собранная машина сходит с конвейера. Завод выпускает одну машину в минуту независимо от того, сколько времени занимает сборка одной машины. В этом и состоит суть работы конвейера. Такой подход в равной степени применим и к процессорам, и к производству машин.
Конвейер с 7 стадиями: Mic-4
Мы не упомянули о том факте, что каждая микрокоманда выбирает следующую за ней микрокоманду. Большинство из них просто выбирают следующую команду в текущей последовательности, но последняя из них, например swap6, часто совершает межуровневый переход, который останавливает работу конвейера, поскольку после этого перехода вызывать команды заранее уже становится невозможно. Поэтому нам нужно придумать лучшую технологию.
Следующая (и последняя) микроархитектура — Mic-4. Ее основные части проиллюстрированы на рис. 4.23, но значительное количество деталей не показано, чтобы сделать схему более понятной. Как и Mic-З, эта микроархитектура содержит блок выборки команд, который заранее вызывает слова из памяти и сохраняет различные значения MBR.
Блок выборки команд передает входящий поток байтов в новый компонент — блок декодирования. Этот блок содержит внутреннее ПЗУ, которое индексируется кодом операции IJVM. Каждый элемент (ряд) блока состоит из двух частей: длины команды IJVM и индекса в другом ПЗУ— ПЗУ микроопераций. Длина команды IJVM нужна для того, чтобы блок декодирования мог разделить входящий поток байтов и установить, какие байты являются кодами операций, а какие операндами. Если длина текущей команды составляет 1 байт (например, длина команды POP), то блок декодирования определяет, что следующий байт — это код операции. Если длина текущей команды составляет 2 байта, блок декодирования определяет, что следующий байт — это операнд, сразу за которым следует другой код операции. Когда появляется префиксная команда WIDE, следующий байт преобразуется в специальный расширенный код операции, например, WIDE+ILOAD превращается в WIDE_ILOAD.
Блок декодирования передает индекс в ПЗУ микроопераций, который он находит в своей таблице, следующему компоненту, блоку формирования очереди. Этот блок содержит логические схемы и две внутренние таблицы: одна — для ПЗУ и одна — для ОЗУ. В ПЗУ находится микропрограмма, причем каждая команда IJVM содержит набор последовательных элементов, которые называются микроопераци-
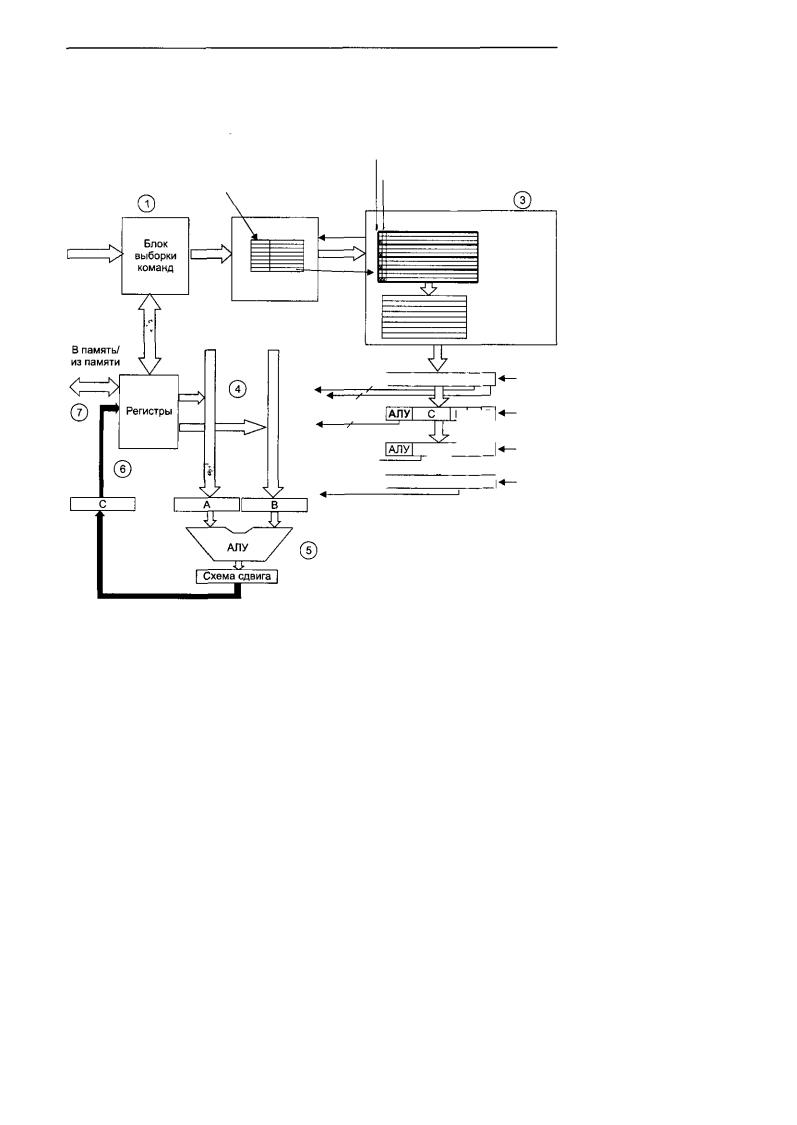
Разработка микроархитектурного уровня |
291 |
ями. Эти элементы должны быть расположены в строгом порядке, и, например, переход из wide_iload2 в iload2, который допустим в микроархитектуре Mic-2, не разрешается. Каждая последовательность микроопераций должна выполняться полностью, в некоторых случаях последовательности дублируются.
|
|
|
Бит завершения |
|
|||
|
Длина |
Индекс |
Бит перехода |
|
|||
|
командыILVM |
|
Блок формирования |
||||
|
© |
микрооперации |
|||||
|
|
очереди |
|
||||
|
I |
|
|
|
|||
Из памяти |
7 |
, л. ОЗУ микроопераций |
|
||||
|
|
|
|
IADD |
|||
|
|
|
|
|
|||
|
|
|
|
|
|
|
ISUB |
|
|
|
|
|
|
|
ILOAD |
|
Блок |
|
|
|
|
|
IFLT |
|
|
|
|
|
|
|
|
|
декодирования |
|
|
|
Очередь |
||
|
|
|
|
|
|
||
|
|
|
|
|
|
незаконченных |
|
|
|
|
|
|
|
микроопераций |
|
|
Стадия передачи 4 |АЛУ| |
С |
| М JA| В |
MIR1 |
|||
|
Стадияпередачи5 |
|
|
|
MIR2 |
||
|
Стадияпередачи6 |
|
С |
|М|А|В| |
MIR3 |
||
|
Стадия передачи 7 |АЛУ| |
С |
|М|А|В| |
MIR4 |
|||
Рис. 4.23. Основныекомпоненты микроархитектуры Mic-4
Структура микрооперации сходна со структурой микрокоманды (см. рис. 4.4), только в данном случае поля NEXT_ADDRESS и JAM отсутствуют и требуется новое поле для определения входа на шину А. Имеется также два новых бита: бит завершения (Final bit) и бит перехода (Goto bit). Бит завершения устанавливается на последней микрооперации каждой последовательности (чтобы обозначить эту операцию). Бит перехода нужен для указания на микрооперации, которые являются условными микропереходами. По формату они отличаются от обычных микроопераций. Они состоят из битовJAM и индекса в ПЗУ микроопераций. Микрокоманды, которые раньше осуществляли какие-либо действия с трактом данных, а также выполняли условные микропереходы (например, iflt4), теперь нужно разбивать на две микрооперации.

292 Глава 4. Микроархитектурный уровень
Блок формирования очереди работает следующим образом. Он получает от блока декодирования индекс микрооперации ПЗУ. Затем он отыскивает микрооперацию и копирует ее во внутреннюю очередь. Затем он копирует следующую микрооперацию в ту же очередь, а также следующую за этой микрооперацией. Так продолжается до тех пор, пока не появится микрооперация с битом завершения. Тогда блок копирует эту последнюю микрооперацию и останавливается. Если блоку не встретилась микрооперация с битом перехода и у него осталось достаточно свободного пространства, он посылает сигнал подтверждения приема блоку декодирования. Когда блок декодирования воспринимает сигнал подтверждения, он посылает блоку формирования очереди следующую команду IJVM.
Таким образом, последовательность команд IJVM в памяти в конечном итоге превращается в последовательность микроопераций в очереди. Эти микрооперации передаются в регистры MIR, которые посылают сигналы тракту данных. Но есть еще один фактор, который нам нужно рассмотреть: поля каждой микрооперации не действуют одновременно. Поля А и В активны во время первого цикла, поле АЛУ активно во время второго цикла, поле С активно во время третьего цикла, а все операции с памятью происходят в четвертом цикле.
Чтобы все эти операции выполнялись правильно, мы ввели 4 независимых регистра MIR в схему на рис. 4.23. В начале каждого цикла (на рис. 4.2 это время Aw) значение MIR3 копируется в регистр MIR4, значение MIR2 копируется в регистр MIR3, значение MIR1 копируется в регистр MIR2, а в MIR1 загружается новая микрооперация из очереди. Затем каждый регистр MIR выдает сигналы управления, но используются только некоторые из них. Поля А и В из регистра MIR1 применяются для выбора регистров, которые запускают защелки А и В, а поле АЛУ
врегистре MIR1 не используется и не связано ни с чем на тракте данных.
Вследующем цикле микрооперация передается в регистр MIR2, а выбранные регистры в данный момент находятся в защелках А и В. Поле АЛУ теперь используется для запуска АЛУ. В следующем цикле поле С запишет результаты обратно
врегистры. После этого микрооперация передается в регистр MIR4 и инициирует любую необходимую операцию памяти, используя загруженное значение регистра MAR (или MDR для записи).
Нужно обсудить еще один аспект микроархитектуры Mic-4: микропереходы. Некоторым командам IJVM нужен условный переход, который осуществляется
спомощью бита N. Когда происходит такой переход, конвейер не может продолжать работу. Именно поэтому нам пришлось добавить в микрооперацию бит перехода. Когда в блок формирования очереди поступает микрооперация с таким битом, блок воздерживается от передачи сигнала о получении данных блоку декодирования. В результате машина будет простаивать до тех пор, пока этот переход не разрешится.
Предположительно, некоторые команды IJVM, не зависящие от этого перехода, уже переданы в блок декодирования, но не в блок формирования очереди, поскольку он еще не выдал сигнал о получении. Чтобы разобраться в этой путанице
ивернуться к нормальной работе, требуется специальное аппаратное обеспечение
иособые механизмы, но мы не будем рассматривать их в этой книге. Э. Дейкстра, написавший знаменитую работу «GOTO Statement Considered Harmful» («Выражение GOTO губительное), был прав.