

Методичка. Распознование образов
.pdfА
w xi b 1
w xi b 0
w xi b 1
В
Рисунок 2. Разделяющая полоса
Ширина разделяющей полосы равна 2 [11]. Чем w
шире полоса, тем увереннее можно классифицировать объекты, соответственно, самая широкая полоса является лучшей. В случае линейной разделимости, выбираются такие w и b, чтобы выполнялись все линейные ограничения, и при этом как можно меньше была норма вектора w (следовательно, шире разделяющая полоса), то есть необ-
ходимо минимизировать: 
 w
w
 2 w w. Таким образом, ме-
2 w w. Таким образом, ме-
тод опорных векторов сводит обучение классификатора к задаче квадратичной оптимизации - при линейных ограничениях найти минимум квадратичной функции.
Рассмотрим наглядный пример перехода к расширенному пространству (см. рис.3). Точки на рисунке нельзя
42
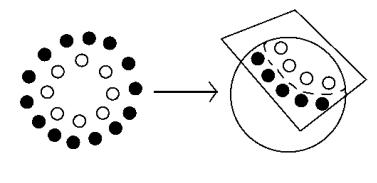
разделить никакой полосой. Если мы перенесем эти точки на сферу, то тогда они разделяются плоскостью, которая срезает часть сферы. Таким образом, выгнув пространство, можно легко найти разделяющую гиперплоскость.
Рисунок 3. Разделяющая гиперплоскость
На практике чаще всего получается, что множества объектов не являются линейно-разделимыми. В этом случае, можно позволить классификатору делить множества так, чтобы между гиперплоскостями могли оказаться точки. Отсюда появляется погрешность, которую пытаются минимизировать.
Метод опорных векторов хорошо зарекомендовал себя в распознавании рукописного текста и лиц, в задачах текстовой классификации.
Программная реализация метода опорных векто-
ров – SVM Light
Одной из наиболее широко используемых для научных исследований реализаций метода SVM приложение
SVM Light.
43
SVM Light – это готовая реализация алгоритма метода опорных векторов [3,4]. SVM Light представляет собой приложение, написанное на языке С. Программа распространяется бесплатно и предназначена только для исследовательских целей. SVM Light используется для анализа данных и распознавания шаблонов в задачах классификации и регрессионного анализа. Данная реализация алгоритма SVM работает как линейный классификатор, т.е. разделяет исходное множество документов на две категории. Пакет SVM Light включает в себя два исполняемых файла: модуль обучения и модуль классификации.
Обучающий модуль svm_learn принимает на вход текстовый файл с расширением *.dat с обучающими данными. Файл должен содержать вектора с меткой +1 или -1 в зависимости от того, какому из двух классов он принадлежит.
Входной файл имеет следующий формат:
<line> .=. <target> <feature>:<value> <feature>:<value> ... <feature>:<value> #<info> <target> .=. +1 | -1 | 0 | <float>
<feature> .=. <integer> | "qid" <value> .=. <float>
<info> .=. <string>
Здесь первое число – метка, указывающая к какому из двух классов должен относится документ, далее через пробел веса параметров. Если же мы опускаем все нулевые значения, то тогда необходимо перечислить только ненулевые значения с указанием индекса. После знака # допускается использование комментариев, которые будут проигнорированы программой.
Выглядит это так:
-1 0 0 0 0 0 0 6 0 0 0 6.56 0 0 0 0 0 0 0 45.56 0 0 0 0 0 0.5 0 0 0 0 0 0 0
Вектор может быть записан следующим образом:
-1 7:6 11:6.56 19:45.56 25:0.5
44
Синтаксис учебного модуля svm_learn: svm_learn [опции] example_file model_file
Список возможных опций доступен здесь [4].
Классифицирующий модуль svm_classify принимает на вход текстовый файл с данными, которые нужно распознать. Формат такой же, что и для обучения. В качестве указания класса можно использовать нулевые значения. После классификации создается итоговый файл result, в котором записаны прогнозируемые значения.
Чтобы представить документ в виде вектора, необходимо посчитать меру вхождения каждого выбранного параметра в документ. Этой мерой может быть количество вхождений в документ или доля этого параметра в документе. Размерность вектора – это количество всех параметров, по которым планируется классифицировать документы.
Задания для индивидуальной работы
Реализовать задания 3 – 7 параграфа 1 при помощи метода опорных векторов, сравнить полученные результаты с результатами, полученными при помощи других методов. Дополнительно решить вышеуказанные задачи при помощи приложения SVM Light, сравнить полученные результаты.
Литература
1.Котельников Е.В., Колеватов В.Ю. Методы искусственного интеллекта в задачах обеспечения безопасности компьютерных сетей / Всероссийский конкурсный отбор обзорно-аналитических статей по приори-
45
тетному направлению "Информационнотелекоммуникационные системы", 2008. - 23 с.
2.Vapnik V. N. The Nature of Statistical Learning Theory. 2- е изд.. Springer-Verlag, New York, 2000, 314c.
3.T. Joachims, Making large-Scale SVM Learning Practical. Advances in Kernel Methods - Support Vector Learning, B. Schölkopf and C. Burges and A. Smola (ed.), MITPress, , Cambridge, USA, 1999. C. 41-56.
4.SVM Light: http://svmlight.joachims.org/
5.Форсайт Д.А., Понс Ж. Компьютерное зрение. Современный подход. : Пер. с англ. – М.: Издательский дом
«Вильямс», 2004. – 928 с.
6. Журавлев Ю. И., Рязанов В. В., Сенько О. В. «Распознавание». Математические методы. Программная система. Практические применения. — М.:
Фазис, 2006.
7.Ландэ Д. В., Снарский А. А., Безсуднов И. В. Интернетика: Навигация в сложных сетях: модели и алгорит-
мы. — M.: Либроком (Editorial URSS), 2009. — 264 с.
8.Лепский А.Е., Броневич А.Г. Математические методы распознавания образов: Курс лекций. – Таганрог: Изд-
во ТТИ ЮФУ, 2009. – 155 с.
9.Воронцов К.В. Курс лекций «Математические методы обучения по прецедентам» // http://www.machinelearning.ru/wiki/images/6/6d/Voron- ML-1.pdf
10.Лифштиц Ю. Метод опорных векторов. Эл. ресурс. [Режим доступа: http://yury.name/internet/07ianote.pdf]
11.Воронцов К. В. Лекции по методу опорных векторов. Эл. ресурс. [Режим доступа: http://www.ccas.ru/voron/download/SVM.pdf]
12.Интуит - интернет-университет информационных технологий. Data Mining, 10 лекция: Методы классификации и прогнозирования. Метод опорных векторов. Эл.
46
ресурс. [Режим доступа: http://www.intuit.ru/department/database/datamining/10/da tamining_10.html]
13.Лекции Д.П. Ветрова и Д.А. Кропотова «Байесовские методы машинного обучения» // http://www.machinelearning.ru/wiki/images/e/e1/BayesM L-2007-textbook-1.pdf
47
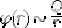
1, |
g(S) 0, |
|
|
|
g(S) 0, |
A(S) , |
||
|
0, |
g(S) 0. |
|
||
В качестве основных требований к виду функций K(S,Si) предъявляются следующие два:
1. |
K(Si,Si |
) max K(Si,S); |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
S |
|
|
|
|
|
|
|
|
|
|
|
|
2. |
K(S,Si) K(S,Sj ) при |
|
Sj S |
|
|
|
|
|
Si S |
|
|
|
(т.е. |
|
|
|
|
|
|
|
|||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
K(S,Si) монотонно убывает при 
 Si S
Si S
 ).
).
Распространенными примерами выбора K(S,Si)
являются следующие:
1. |
K(S,Si |
) |
2 |
|
|
, где σ - числовой пара- |
|||||||||||||
2 |
|
S Si |
|
2 |
|||||||||||||||
метр; |
|
|
|
|
|
|
|
|
|
|
|
|
|||||||
|
|
|
|
|
1 |
|
|
|
|
|
|
|
|
|
|
|
|
||
2. |
K(S,S |
) exp( |
|
|
|
|
S S |
|
|
|
|
2); |
|||||||
|
|
|
|
|
|
||||||||||||||
|
|||||||||||||||||||
|
i |
|
|
|
|
2 2 |
|
|
|
|
|
|
i |
|
|
|
|
||
|
|
|
|
|
|
|
|
|
|
|
|
||||||||
Таким образом, для классификации достаточно выбрать конкретный вид функции и задать неизвестные значения параметров ,q1,q2,...,qm .
Вычисление значений параметров q1,q2,...,qm при фиксированном σ (а, следовательно, и функции g(S)) осуществляется в процессе обучения согласно правилу коррекции (1.9). Пусть на некотором шаге имеется функция g(S). Для классификации предъявляется некоторый объект Si обучающей выборки. Если результат классификации правильный, предъявляется для классификации следующий объект обучающей выборки. Если классификация является неправильной, осуществляется коррекция функции g(S) согласно правилу (1.9) .
49

g(S) K(S,S |
), |
g(S |
|
) 0, |
S |
|
K , |
||
g*(S) |
i |
|
|
i |
|
|
i |
1 |
(1.9) |
g(S) K(S,Si), |
g(Si ) 0, |
Si |
K2. |
||||||
Объекты обучающей выборки предъявляются, например, циклически или в случайном порядке. Процесс обучения продолжается до достижения безошибочного распознавания всех объектов обучающей выборки полученной функцией g(S) или «стабилизации» - достижения ситуации, когда среднее число ошибок перестает уменьшаться за заданное число итераций.
K1
Si
g(x)>0
g(x)=0
K2
g(x)<0
Рис.4. Примеры возможной коррекции функции g(S) при условии g(Si ) 0, Si K2 .
На рис.4 проиллюстрирована коррекция потенциальной функции g(S) (множество точек g(S)=0 изображено жирной линией) при предъявлении некоторого объекта из второго класса, неправильно классифицируемого данной функцией. Функция g*(S) будет отличаться от g(S) практически лишь в окрестности Si (участки заметного отличия отмечены пунктирами). При повторном
50

предъявлении Si потенциальная функция может правильно классифицировать объект (жирный пунктир) или опять неправильно. Во втором случае (тонкий пунктир), тем не менее, коррекция g(S) будет сделана «в нужную сторо-
ну», g*(Si) g(Si ).
В учебном пособии [3] можно найти листинг программы для среды MatLab, реализующий метод потенциальных функций; также можно ознакомиться с кодом программы, реализующий данный метод, для среды Delphi в [7].
Пример решения задачи
Представим каждый документ обучающей выборки
идокумент (объект), который мы планируем
классифицировать, в виде вектора признаков:X1,X2, Xn . При классификации объект проверяется на
близость к объектам из обучающей выборки. Считается, что объекты из обучающей выборки «заряжены» своим классом, а мера «важности» каждого из них при классификации зависит от его «заряда» и расстояния до классифицируемого объекта.
В самом простом случае для каждого из признаков можно вычислить потенциал по формуле:
P
a
R2
где a – некоторый постоянный коэффициент (для удобства a можно приравнять к 100 или 1000).
R – расстояние от данной точки до среднего значения одного из классов.
Вычислив потенциалы по определенному признаку классифицируемого объекта (например, средней длины слова текстового документа) относительно каждого из
51