

C _Учебник_МОНУ
.pdf
|
Файли |
409 |
char buf[80]; |
// Рядок (буфер) |
|
char *s = buf; |
// і вказівник на цей рядок |
|
int n = FileRead(f, s, 80); FileClose(f);
Розглянемо приклад створення і опрацювання текстового файла через дескриптори.
Приклад 12.9 Створити файл з інформацією про чисельність населення областей України: назва області, обласний центр, кількість мешканців області. Вивести області, в яких кількість жителів перевищує 1 500 000 людей.
Розв‟язок. При створюванні текстового файла усі дані, які зчитуватимуться з компонентів Edit, записуватимуться до файла через пробіл у вигляді рядків. Для подальшого опрацювання слів цього рядка вважатимемо, що кожен рядок завершується символами "\r\n". Словом вважатимемо частину рядка, відокремлену пробілами. При опрацюванні файла, а саме, при зчитуванні даних, використовуватимемо функцію FileRead(), другим параметром якої є змінна типу *сhar, в яку записуватимуться данні, а третім – розмір у байтах зчитуваних даних.
Наведемо програмну реалізацію поставленого завдання двома способами, в яких проілюструємо різні підходи опрацювання рядків текстового файла. У першому способі для зчитування рядків з файла створено окрему функцію GetLine(), яка читає рядки посимвольно. Другий спосіб показує засоби зчитування рядка по словах у спеціально для цього створеній функції GetString().
Текст програми:
int f; |
// Дескриптор оголошено глобально |
__fastcall TForm1::TForm1(TComponent* Owner) |
|
: TForm(Owner) |
// Конструктор форми |
{SG1->Cells[0][0]="Назва області"; SG1->Cells[1][0]="Обласний центр"; SG1->Cells[2][0]="Кільк.жителів";
SG1->ColWidths[0]=80; SG1->ColWidths[1]=70; SG1->ColWidths[2]=70;
} // Тут SG1 – нове значення властивості Name компонента StringGrid1
Файли |
411 |
if(len != 0) st->printf("%s", buf); return len;
}
//Кнопка “Переглянути файл”
//Відбувається порядкове неформатоване зчитування даних з файла і виведення до
//SG1 за допомогою властивості DelimitedText, яка розбиває рядок на окремі лексеми void __fastcall TForm1::Button2Click(TObject *Sender)
{AnsiString st; bool d=true;
f=FileOpen("obl.txt", fmOpenReadWrite); if(f == -1)
{ShowMessage("Файл не відкрито"); return; } while(GetLine(f,&st) != 0)
{if(d)
{SG1->Rows[SG1->Row]->DelimitedText=st; d=false; } else
{SG1->RowCount++; SG1->Row=SG1->RowCount-1; SG1->Rows[SG1->Row]->DelimitedText=st;
}}
FileClose(f);
}
// Кнопка “Визначити розмір файла”
void __fastcall TForm1::Button3Click(TObject *Sender) { f=FileOpen("obl.txt",fmOpenReadWrite);
if(f==-1)// У разі помилки доступу до файла, вивести відповідне повідомлення
{ ShowMessage("Файл не відкрито"); return; }
int k=FileSeek(f,0,2); // Переведення позиції на кінець файла
Edit4->Text=IntToStr(k); FileClose(f);
}
//Вивести області, в яких мешкає більше 1 500 000 жителів
//Кнопка “Перший спосіб розв‟язання”
void __fastcall TForm1::Button4Click(TObject *Sender) { f=FileOpen("obl.txt", fmOpenReadWrite);
if(f == -1) { ShowMessage("Файл не відкрито"); return; }
Memo1->Clear();
char *buf, *stw, *p; AnsiString st, bt; while(GetLine(f,&st) != 0)
{stw=st.c_str(); bt=AnsiString(stw);
p=strpbrk(stw,"0123456789"); /* strpbrk() відшукує місце першого
входження в рядок stw будь-якого символу з другого рядка і повертає частину рядка s1, починаючи з цього символу і до кінця рядка, тобто в p запишеться кінцівка рядка зі значенням кількості мешканців. */
if((StrToInt(p)>=1500000)) Memo1->Lines->Add(bt);
}
FileClose(f);
}
Файли |
413 |
12.3Бінарні файли
Убінарному (двійковому) файлі число, на відміну від текстового, зберігається у внутрішньому його поданні. У двійковому форматі можна зберігати не лише числа, а й рядки та цілі інформаційні структури. Причому останні зберігати зручніше, завдяки тому що відсутня потреба явно зазначати кожен елемент структури, а зберігається вся структура як цілковита одиниця даних. Хоча цю інформацію не можна прочитати як текст, вона зберігається більш компактно і точно. Тому, що саме і в якій послідовності розміщено в бінарному файлі, має бути відомо програмі.
12.3.1 Робота з бінарними файлами у стилі С
З двійковими файлами можна виконувати ті ж самі дії, що і з текстовими. Для відкривання бінарного файла використовується та сама команда fopen(), лише у другому параметрі (режимі відкривання файла) замість літери “t” треба записати літеру “b”. Наприклад, бінарний файл з ім‟ям tmp.dat можна відкрити для зчитування такою командою:
f = fopen("tmp.dat", "rb");
де f – вказівник типу FILE*.
Записування і зчитування у двійкових файлах найчастіше здійснюються за допомогою відповідно функцій fwrite() та fread().
Прототип функції зчитування fread(): size_t fread
( char *buffer, |
// Масив для зчитування даних, |
size_t elemSize, |
// розмір одного елемента, |
size_t numElems, |
// кількість елементів для зчитування |
FILE *f |
// і вказівник потоку |
);
Тут size_t означений як беззнаковий цілий тип у системних заголовних файлах. Функція намагається прочитати numElems елементів з файла, який задається вказівником f, розмір кожного елементу становить elemSize. Функція повертає реальну кількість прочитаних елементів, яка може бути менше за numElems, у разі завершення файла чи то помилки зчитування.
Приклад використання функції fread():
FILE *f;
double buff[100]; size_t res;
f = fopen ("tmp.dat", "rb"); // Відкриття файла if(f == 0)
{ShowMessage ("Не можу відкрити файл для зчитування");
exit (1); |
// Завершення роботи з кодом 1 |
}
// Зчитування 100 дійсних чисел з файла
res = fread(buff, sizeof(double), 100, f); // res дорівнює реальній кількості прочитаних чисел
Файли |
415 |
У такий спосіб можна читати які завгодно записи в будь-якій послідовності. За допомогою переміщування позиції можна редагувати записи у файлі. Нехай, приміром, треба змінити у файлі одне з чисел, помноживши його на 10. Це можна зробити, якщо відкрити файл у режимі зчитування і записування (наприклад у форматі "rb+"), переміститись у відповідну позицію і виконати оператори
fread(&z, sizeof(double), 1, F); z *= 10;
fseek(F, -sizeof(double), 1); fwrite(&z, sizeof(double), 1, F);
Перший з цих операторів читає число з файла у дійсну змінну z типу double, другий – помножує її на 10. Третій оператор повертає позицію на один запис назад, оскільки після виконання fread() позиція просунулась уперед. Останній оператор пише в ту позицію, з якої було прочитано число, нове значення.
Те ж саме завдання можна розв‟язати в інший спосіб:
long int pos = ftell(F); // Запам‟ятовування позиці. fread(&z,sizeof(double),1,F);// Зчитування числа з файла до змінної z *= 10;
fseek(F,pos,0); // Відновлення позиції fwrite(&z,sizeof(double),1,F);//Записування числа зі змінної z до файл
Тут функція ftell() визначає поточну позицію файла, з якої читається число, а функція fseek() відновлює цю позицію перед записуванням зміненого числа.
Як було зазначено вище, за допомогою двійкових файлів можна записувати й зчитувати не лише числа та рядки, а й структури (див. приклади 12.12 та
12.14).
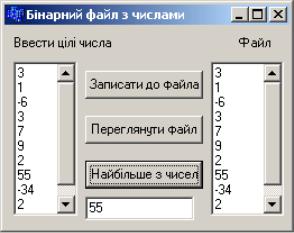
Приклад 12.11 Створити бінарний файл, який містить цілі числа, і віднайти серед них найбільше число.
Форма проекту з результатами роботи матиме вигляд
Файли |
417 |
Текст програми:
#include <stdio.h> FILE* f;
struct ved
{ char priz[20]; int oc;
}v;
//Кнопка “Переглянути файл”
void __fastcall TForm1::Button1Click(TObject *Sender)
{Memo1->Clear();
//Відкриття файла для зчитування if((f=fopen("ocіnki.dat", "rb"))==0)
{ShowMessage("Файл не відкрито"); return; } while(fread(&v, sizeof(ved),1,f)) //Зчитування з файла в змінну v
Memo1->Lines->Add(AnsiString(v.priz)+" "+IntToStr(v.oc)); fclose(f);
}
// Студенти, які отримали “Незадовільно”
void __fastcall TForm1::Button2Click(TObject *Sender)
{Memo2->Clear();
if((f=fopen("ocіnki.dat", "rb"))==0)
{ ShowMessage("Файл не відкрито"); return; } while (fread(&v, sizeof(ved),1,f))
{ if(v.oc < 60) //Якщо оцінка є менше за 60
Memo2->Lines->Add(AnsiString(v.priz)+" "+IntToStr(v.oc));
}
fclose(f);
}
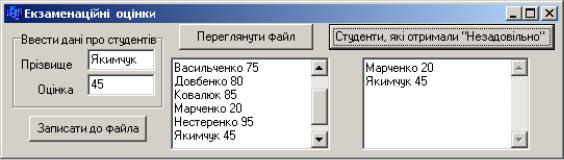
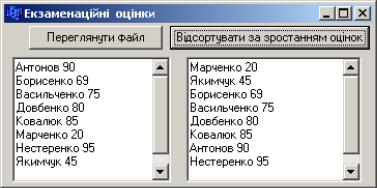
Приклад 12.13 Відсортувати дані файла з відомостями про екзаменаційні оцінки (який було створено у попередньому прикладі) за зростанням оцінок.
Розв‟язок. Вважаємо, що файл ocinki.dat вже створено і розміщено у теці з проектом. Оскільки при сортуванні файла треба кілька разів переходити до початку файла, а всі операції з файлом виконуються набагато повільніше, аніж з масивом, є сенс записати всі дані з файла до динамічного масиву, відсортувати його, а потім повернути дані з масиву до файла.
Форма проекту з результатами роботи матиме вигляд