

3.5.3. Метод исключения (отбраковки, режекции, Дж. Неймана)
Основой метода является следующая теорема:
Если
множество точек (x,y)
является реализацией случайного вектора
![]() ,
равномерно распределенного в области,
ограниченной осью 0X
и кривой f(x),
такой, что
,
равномерно распределенного в области,
ограниченной осью 0X
и кривой f(x),
такой, что
![]() ,
,
то одномерная плотность распределения величины ξ равна
![]() .
.
Отсюда
следует, что, если f(x)
– искомая функция плотности распределения
(т.е.
![]() ),
то, реализовав процедуру построения
множества случайных векторов, равномерно
распределенных под графиком f(x),
мы, тем самым, получим множество значений
абсцисс {xi},
распределённых в соответствии с законом,
определяемым функцией f(x).
),
то, реализовав процедуру построения
множества случайных векторов, равномерно
распределенных под графиком f(x),
мы, тем самым, получим множество значений
абсцисс {xi},
распределённых в соответствии с законом,
определяемым функцией f(x).
Однако, процедура генерирования случайных векторов может оказаться достаточно сложной в вычислительном плане (надо использовать условные функции плотности ввероятностей). Для упрощения процедуры формирования случайных чисел воспользуемся следующим достаточно очевидным утверждением.
Если
вектор
![]() равномерно распределён под кривой
равномерно распределён под кривой
![]() ,
такой, что
,
такой, что
![]()
для всей области определения f(x), то его реализации, ограниченные областью между 0X и f(x) будут равномерно распределены в этой области.
Функция g1(x) называется мажорирующей функцией по отношению к f(x) (рис. 3.9) .
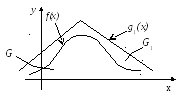
Рис. 3.9. Мажорирующая функция
Можно выбрать функцию g1(x) такой, что вектора, равномерно распределенные в области G1 , будет просто генирировать. Удобно выбирать функцию, имеющую постоянное значение на всей области определения f(x):
g1(x)= const,
как правило, равное максимальному значению fmax функции f(x).
y
fmax
f(xi)

x а b 0 . xi yi




Рис. 3.10. Метод исключения
Отсюда вытекает процедура метода (рис. 3.10):
а) если функция f(x) не ограничена, то, учитывая допустимую погрешность, область ее определения ограничивают интервалом (a,b);
б)
имитируется реализация (xi,yi)
вектора
![]() ,
равномерно распределеного в области
G1
(между OX
и g1(x)):
,
равномерно распределеного в области
G1
(между OX
и g1(x)):
– генерируется РРСЧ xi из диапазона (a,b);
– генерируется РРСЧ yi из диапазона (0, fmax(x));
в) если, yi<f(xi) то (xi,yi) является реализацией вектора, распределённого в области G (между осью 0X и f(x)) и xi – искомая реализация ξ. Иначе процедура повторяется, начиная с пункта б).
Так как в качестве базовой последовательности обычно берут числа, равномерно распределенные в диапазоне от 0 до 1, то от случайной величины ξ сискомой функцией распределения f ξ переходят к случайной величине
ξ*
=
![]() .
.
Для нее область возможных значений (0, 1), а функция плотности вероятностей имеет вид
fξ*(z) = (b-a)f ξ[a+(b-a)z]
(сжатие по оси абсцисс).
Произведем сжатие по оси ординат:
f*ξ*(z) = fξ*(z)/fmax ,
где fmax максимальное значение fξ*(z).
В результате произведенных действий функция f*ξ*(z) расположилась в единичном квадрате в начале системы координат.
Теперь процедура получения последовательности чисел с функцией плотности fξ(x) сводится к следующему.
генерируется пара РРСЧ из диапазона (0, 1) – ηi, ηi+1;
проверяется выполнение условия
ηi+1![]() f*ξ*(
ηi
)
;
f*ξ*(
ηi
)
;
если это условие выполняется, то очередное число, включаемое в выходную последовательность получаем как
xj = a+(b-a) ηi ,
иначе процедура повторяется, начиная с пункта 1.
Эффективность метода исключения характеризуется коэффициентом использования kn – отношением количества отобранных реализаций к общему числу реализаций. Очевидно, что это отношение при равномерном распределении реализаций равно отношению площадей под графиками функций f(x) и g1(x):
![]() ,
,
где
![]() ,
а
,
а
![]() .
.
Чем ближе значение kn к 1, тем эффективнее использование метода. Можно, например, использовать в качестве мажорирующей функции g1(x) ступеньчатую функцию (рис. ). При этом значение коэффициента kn увеличивается, но следует иметь в виду, что при этом одновременно увеличивается число вычислений.

g1(x)











. . . .



Рис. 3.11. Ступенчатая мажорирующая функция
Пример. 3.1.
Рассмотрим использование метода для получения чисел с треугольным распределением:
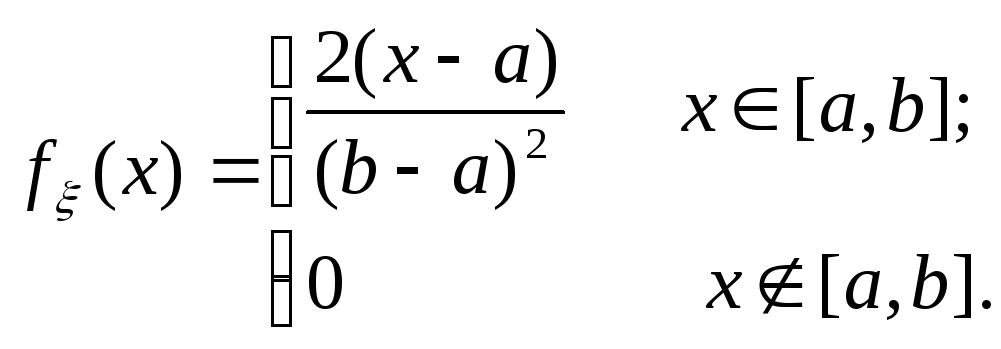
Переходим от случайной величины ξ к величине ξ*, реализацией которой является значение
z
=
![]() .
.
Значениz z лежат в диапазоне от 0 до 1 (рис. б) и для нее функция плотности распределения
fξ*(z)
= (b-a)f
ξ[a+(b-a)z]=![]() .
.
fξ(x) а) б)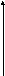


a b x
0


fξ*(z) f*ξ*(z)


z
1 1 0
Рис. 3.12. Имитация треугольного распределения
Максимальное значение эта функция принимает при z=1:
fmax=2.
Произведем масштабирование по вертикальной оси:
f*ξ*(z) = fξ*(z)/fmax =z.
Таким образом, мы пришли к функции, вписанной в единичный квадрат (рис. 3.12. б).
Теперь формирование чисел с треугольным распределением будем производить по следующему алгоритму:
1) Берём η1 и η2 − равномерно распределенные в диапазоне от0 до 1 числа;
2) Если η1 > η2, то включаем в выходную последовательность очередное число xj = a+(b-a) η1 , иначе переходим к пункту 1.
Для ускорения процедуры можно заполнять квадрат сразу парами точек , симметричными относительно диагонали с координатами (η1, η2) и (η2, η1) .
Тогда пункт 2 будет иметь вид: xj = a+(b-a)max ((η1, η2) .