

6.2. Работа с таблицей символов
Поскольку синтаксические анализаторы обычно используют контекстно – свободную грамматику, необходимо найти метод определения контекстно – зависимых частей языка. Например, во многих языках идентификаторы не могут применяться, если они ранее не описаны, и имеются ограничения в отношении способов употребления в программе значений различного типа. Кроме того, в языках программирования имеются ограничения на употребление различных знаков. Для запоминания описанных идентификаторов и их типов большинство компиляторов использует таблицу символов. В принятой формализации описания
int a
является определяющейреализациейа, а использованиеав другом контексте
a=4 или a+ b или read(a)
говорит, что имеется прикладная реализацииа.
Во многих языках программирования один и тот же идентификатор может использоваться для представления в различных частях программы различных объектов (например, в «голове» int, ав подпрограммеchar). В этом случае в таблице символов - это два разных объекта.
Таблица символов имеет ту же блочную структуру, что и сама программа, чтобы различать виды употребления одного и того же идентификатора. При построении таблицы символов учитываются основные свойства большинства языков:
определяющая реализация идентификатора появляется раньше любой прикладной реализации;
все описания в блоке помещаются раньше всех операторов и предложений;
при наличии прикладной реализации идентификатора, соответствующая определяющая реализация находится в наименьшем включающем блоке, в котором содержится описание этого идентификатора;
в одном и том же блоке идентификатор не может описываться более одного раза.
Пусть синтаксис описания идентификаторов задается правилами:
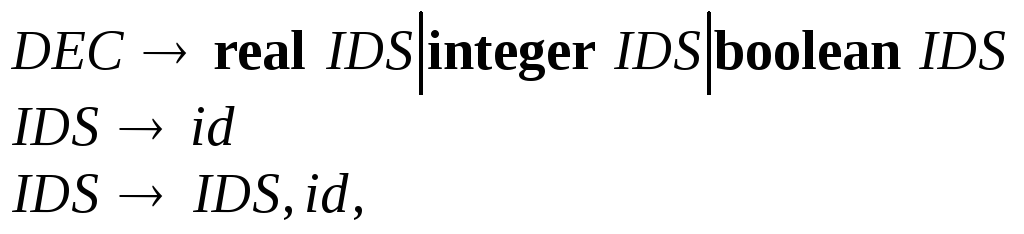
а блок определяется как
![]() ,
,
где

В этом случае структуру таблицы символов можно представить в виде
|
|
Levno |
|
|
|
levno |
|
|
|
levno |
|
|
|
|
|
Type |
|
|
|
type |
|
|
|
type |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Type |
|
|
|
type |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
type |
|
|
|
|
|
Таким образом, в любой точке разбора в цепи находятся те блоки, в которые делается текущее вхождение, а уже описанные идентификаторы помещаются в список идентификаторов для того блока, где они описаны.
Для описания таблиц задаются структуры строго фиксированной конфигурации. Обычно в этих структурах идентификаторы и типы представляются целыми числами. Имеется указатель на элемент таблицы символов, соответствующих наименьшему включающему блоку.
В языке, обладающем описанными выше четырьмя свойствами, в качестве структуры данных для таблицы символов удобно использовать стек, каждым элементом которого служит элемент этой таблицы символов.
При встрече с описанием соответствующий элемент таблицы символов помещается в верхнюю часть стека, а при выходе из блока все элементы таблицы символов, соответствующие описаниям в этом блоке, удаляются из стека. Указатель стека понижается до положения, которое он имел до вхождения в блок. В результате в любой момент разбора элементы таблицы символов, соответствующие всем текущим идентификаторам, находятся в стеке, а связанные с ними прикладные и определяющие реализации идентификаторов требуют поиска в стеке в направлении сверху вниз.
Рассмотренный метод иллюстрируется следующим примером
|
Вид программы |
|
|
|
begin int a, b . begin int c, d . end begin int e, f . end end |
|
|
|
|
| |
|
f |
int | |
|
e |
int | |
|
b |
int | |
|
a |
int |
Таким образом, включение действий в грамматику позволяет получить простой и элегантный компилятор. При этом действия выполняются на соответствующем уровне в грамматике.
Контрольные вопросы
Технология включения действий в грамматику.
Получение четверок, грамматика для четверок.
Разбор арифметического выражения с одновременной генерацией кода.
Метод определения контекстно – зависимых частей языка.
Синтаксис описания идентификаторов и блоков.
Структура таблицы символов.
Программная реализация таблицы символов.