

1.3. Множества цепочек
Алфавитомбудем называть любое множество символов (оно не обязательно конечно и даже счетно), но в наших приложениях оно конечно. Предполагается, что слово «символ» имеет достаточно ясный интуитивный смысл.
Символ – (синонимы: буква, знак) элемент алфавита.
Пример:
01011 – цепочка в бинарном алфавите {0, 1}.
Особый вид цепочки – пустая цепочка, обозначается e. Пустая цепочка не содержит символов.
Соглашение.
Прописные буквы греческого алфавита – алфавиты.
a, b, c иd– отдельные символы.
t, u, v, w, x, y и z– цепочка символов.
Если цепочку из iсимволов обозначитьa![]() ,тогда a0=e – пустая
цепочка.
,тогда a0=e – пустая
цепочка.
Определение:
Цепочки в алфавите определяются следующим образом:
е– цепочка в;
если xцепочка виа, тоxa – цепочка в;
y– цепочка втогда и только тогда, когда она является таковой в силу 1) и 2).
Операции над цепочками
Пусть x, y– цепочки.
Цепочка xy– называется сцепленной (конкатенацией). Например,x=ab;y=cd;xy=abcd. Для любой цепочкиx xе=еx=x.
Обращением цепочки x
 называется цепочкаx, записанная
в обратном порядке:
называется цепочкаx, записанная
в обратном порядке:
 ,
,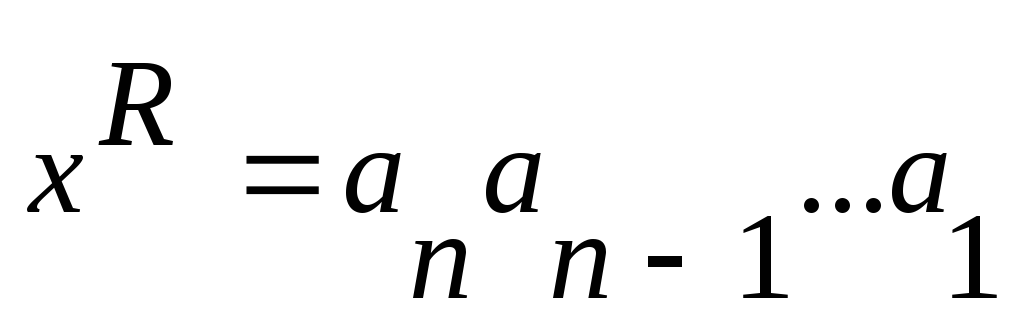 ,
, .
.Пусть x, y, z– цепочки в некотором алфавите, тогда:
x– префикс цепочкиxy;
y– суффикс цепочкиxy;
y– называется подцепочкой цепочкиxyz.
Префикс и суффикс цепочки являются ее подцепочками.
Если xy, x – префикс (суффикс) цепочкиy, тоx- собственный префикс (суффикс) цепочкиy.
Длина цепочки –
это число символов в ней. Если
![]() ,
то длина цепочкиn. Длину цепочки
обозначают|x|, например|abc|=3;|e|=0.
,
то длина цепочкиn. Длину цепочки
обозначают|x|, например|abc|=3;|e|=0.
1.4. Языки
Языком в алфавите называют множество цепочек в.
Определение.
Через *обозначается множество, содержащее все цепочки в алфавите, включаяе.
Например.- бинарный алфавит {0,1}, тогда*={e, 0, 1, 00, 01, 10, 11, 000, …,}.
Каждый язык в алфавите является подмножеством*. Множество всех цепочек в, за исключениеме, обозначают+.
Определение. Если языкLтаков, что полная цепочка вLне является собственным подмножеством (суффиксом) никакой другой цепочки вL, тоLобладает префиксным (суффиксным) свойством.
Операции над языком
Так как языки являются множествами, то все операции над множествами применимы к ним. Операцию конкатенации можно применять к языкам так же, как и к цепочкам.
Определение.
Пусть L1язык в1.,
L2язык в2.
Тогда языкL1L2называется конкатенацией языковL1
иL2 - это язык
![]() .Итерация языкаLобозначаетсяL*,
определяется:
.Итерация языкаLобозначаетсяL*,
определяется:
L0={e};
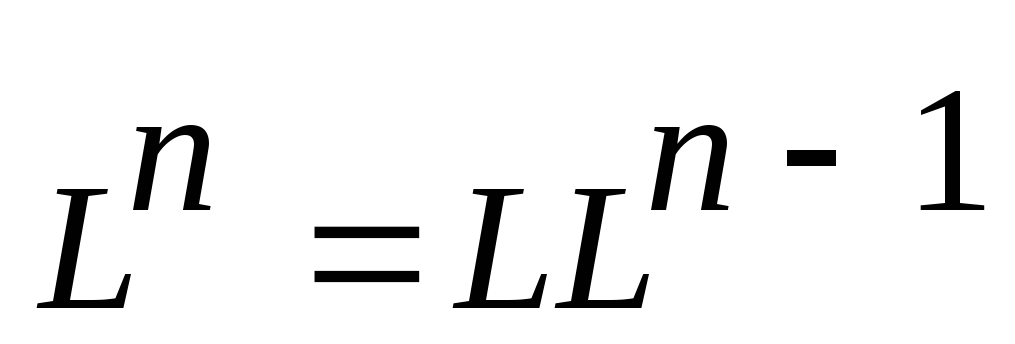 для
n1;
для
n1; .
.
Позитивная
итерация языка L
обозначается L+
- это язык
![]() ,
т.е.
,
т.е.
![]()
Определение.
Пусть 1 и 2 - алфавиты. Гомоморфизмом называется любое отображение h: 1 *2.
Область
гомоморфизма можно расширить до
![]() полагаяh(e)=e
и h(xa)=h(x)h(a)
для всех x
полагаяh(e)=e
и h(xa)=h(x)h(a)
для всех x![]() ,
и а
,
и а![]() .
.
Пример.
Если
мы хотим заменить каждое вхождение в
цепочку символа 0 на а,
а каждое вхождение символа 1 на bb,
то можно определить гомоморфизм h
так: h(0)=a,
h(1)=bb. Если
![]() ,
то
,
то![]() .
.
Определение.
Если
h: 1
![]() ,
то отношениеh-1:
,
то отношениеh-1:
![]()
P(
P(![]() )
называется обращением гомоморфизма.
)
называется обращением гомоморфизма.
Если
y![]() ,
тоh-1(y)
– это множество цепочек в алфавите 1,
т.е.
,
тоh-1(y)
– это множество цепочек в алфавите 1,
т.е.
![]() .
ЕслиL
– язык в алфавите 2,
то
.
ЕслиL
– язык в алфавите 2,
то
![]() - язык в алфавите
- язык в алфавите![]() состоящий из тех же цепочек, которыеh
отображает в цепочки из L.
Формально
состоящий из тех же цепочек, которыеh
отображает в цепочки из L.
Формально
![]()
Пример.
h – гомоморфизм h(0)=a и h(1)=а, тогда
![]()