

3.11.2. Эквивалентность мп-автоматов и кс-грамматик
В теории перевода можно показать, что языки определяемые МП-автоматами, – это в точности КС-языки. Начнем с построения естественного (недетерминированного) «нисходящего» распознавателя, эквивалентного данной КС-грамматике.
Лемма.
Пусть
![]() - КС-грамматика. По грамматике
G
можно построить такой МП-автомат R,
что
- КС-грамматика. По грамматике
G
можно построить такой МП-автомат R,
что
![]() .
.
Доказательство.
Построим R так, чтобы он моделировал все левые выводы в G.
Пусть
![]() ,
где
определяется следующим образом:
,
где
определяется следующим образом:
если А а принадлежит Р, то
 содержит
содержит
 ;
; для
всех
для
всех
 .
.
Мы
хотим показать, что
![]() тогда и только тогда, когда
тогда и только тогда, когда
![]() ⊢n
⊢n
![]() для
некоторых
для
некоторых
![]() .
.
Необходимость
этого условия докажем индукцией по m.
Допустим, что
![]() .
Если m=1
и
.
Если m=1
и
![]() ,
то
,
то
![]() ⊢
⊢
![]() ⊢k
⊢k![]() .
.
Теперь
предположим, что
![]() для некоторого m>1.
Первый шаг этого вывода должен иметь
вид
для некоторого m>1.
Первый шаг этого вывода должен иметь
вид
![]() ,
где
,
где
![]() для некоторого
для некоторого
![]() и
и
![]() .
Тогда
.
Тогда
![]() ⊢
⊢
![]() .
Если
.
Если
![]() ,
то по предложению индукции
,
то по предложению индукции
![]() ⊢*
⊢*![]() .
.
Если
![]() ,
то
,
то
![]() ⊢
⊢
![]() .
Объединяя вместе эти последовательности
тактов, видим, что
.
Объединяя вместе эти последовательности
тактов, видим, что
![]() ⊢+
⊢+
![]() .
.
Для
доказательства достаточности покажем
индукцией по n,
что, если
![]() ⊢n
⊢n
![]() ,
то
,
то
![]() .
.
Если
n=1,
то w=e
и Ae
принадлежит Р.
Предположим, что утверждение верно для
всех
![]() .
Тогда первый такт, сделанный МП-автоматом
R,
должен иметь вид
.
Тогда первый такт, сделанный МП-автоматом
R,
должен иметь вид
![]() ⊢
⊢
![]() ,
причем
,
причем
![]() ⊢ni
⊢ni
![]() для
для
![]() и
и
![]() .
Тогда
.
Тогда
![]() - правило из Р,
и по предложению индукции
- правило из Р,
и по предложению индукции
![]() для
для
![]() .
Если
.
Если
![]() ,
то
,
то
![]() .
Таким образом
.
Таким образом

- вывод цепочки w из А в грамматике G.
Контрольные вопросы
Способы определения языков.
Грамматики.
Грамматики с ограничениями на правила.
Распознаватели.
Регулярные множества, их распознавание и порождения.
Алгоритм решения системы линейных выражений с регулярными выражениями.
Регулярные множества и конечные автоматы.
Проблема разрешимости.
Графическое представление конечных автоматов.
Минимизация конечных автоматов.
Алгоритм построения канонического конечного автомата. Контекстно-свободные грамматики.
Деревья выводов. Преобразование КС-грамматик.
Алгоритм устранения недостижимых символов.
Алгоритм устранения бесполезных символов.
Алгоритм преобразования в грамматику без е-правил. Алгоритм устранения цепных правил.
Грамматики без циклов. Нормальная форма Хомского. Алгоритм преобразования к нормальной форме Хомского.
Нормальная форма Грейбах.
Алгоритм устранения левой рекурсии.
Автоматы с магазинной памятью.
4. КС-грамматики и синтаксический анализ сверху вниз
4.1. Эквивалентность мп-автоматов и кс-грамматик
В практических приложениях нас больше будут интересовать детерминированные МП-автоматы, т.е. такие, которые в каждой конфигурации могут сделать не более одного очередного такта. Языки, определяемые детерминированными МП-автоматами, называются детерминированными КС-языками, а их грамматики - LR(k)-грамматиками.
Определение.
МП-автомат
![]() называется детерминированным
(ДМП),
если для каждых
называется детерминированным
(ДМП),
если для каждых
![]() и
и
![]() либо
либо
 содержит
не более одного элемента для каждого
содержит
не более одного элемента для каждого
 и
и
 ,
либо
,
либо для
всех
для
всех
 и
и
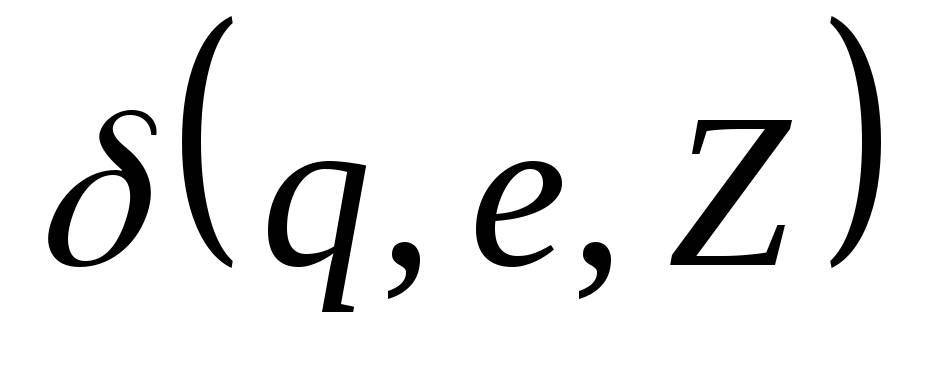 содержит не более одного элемента.
содержит не более одного элемента.
Соглашение.
Так
как ДМП-автомат содержит не более одного
элемента, мы будем писать
![]() вместо
вместо
![]() .
.
Как уже отмечалось, однотактовые детерминированные МП-автоматы порождают КС-языки, которые называются LR(k)-грамматиками. Те в свою очередь являются частным случаем s-грамматик.
Определение. s-грамматика представляет собой грамматику, в которой:
правые части каждого порождающего правила начинаются с терминала;
в тех случаях, когда в левой части более чем одного порождающего правила появляется нетерминал, соответствующие правые части начинаются с различных терминалов.
Первое условие аналогично утверждению, что грамматика находится в нормальной форме Грейбах, только за терминалом в начале каждой правой части правила могут следовать нетерминалы и/или терминалы.
Второе условие соответствует существованию детерминированного одношагового МП-автомата.
Пример.
|
SpX SqY XaXb |
Xx YaYd Yy |
Рассмотрим проблему разбора строки paaaxbbb с помощью заданной s-грамматики. Начав с символа S, попытаемся генерировать строку, применяя левосторонний вывод. Результаты приведены в табл. 4.1.
Таблица 4.1.
|
Исходная строка |
Вывод |
|
paaaxbbb paaaxbbb paaaxbbb paaaxbbb paaaxbbb paaaxbbb |
S PX PaXb PaaXbb PaaaXbbb Paaaxbbb |