

3.3. Грамматики с ограничениями на правила
Грамматики можно классифицировать по виду их правил: пусть G=(N, Σ, P, S) – грамматика.
Определение.ГрамматикаGназывается:
праволинейной,если каждое правило из Р имеет вид АxB или Аx, где А, В;
контекстно-свободной(илибесконтекстной), если каждое правило из Р имеет вид А, где АN,(N)*;
контекстно-зависимой(илинеукорачивающей), если каждое правило из Р имеет вид..
Грамматика, не удовлетворяющая ни одному из заданных ограничений, называется грамматикой общего вида (грамматика без ограничений).
Рассмотренный ранее пример – множество арифметических выражений, построенных из символов а+ *, является примером контекстно–свободной грамматики.
Заметим, что согласно введённым определениям, каждая праволинейная грамматика – контекстно-свободная грамматика. Контекстно-зависимая грамматика запрещает правило Ае(е– правило).
Соглашение.Если языкLпорождается грамматикой типаx, тоLназывается языком типаx. Это соглашение относится ко всем «типамx».
Определённые нами выше типы грамматик и языков называют иерархией Хомского.
3.4. Распознаватели
Второй распространённый метод, обеспечивающий задание языка конечными средствами, состоит в использовании распознавателей. В сущности, распознаватель – это схематизированный алгоритм, определяющий некоторое множество.
Распознаватель состоит из трёх частей (рис 3.1) - входнойленты,управляющего устройствас конечной памятью ивспомогательнойилирабочей, памяти.
Входную ленту можно рассматривать как линейную последовательность клеток, каждая ячейка которой содержит один символ из некоторого конечного входного алфавита. Самую левую и самую правую ячейки обычно занимают (хотя и необязательно) маркеры.
Входная головка в каждый данный момент читает (обозревает) одну входную ячейку. За один шаг работы распознавателя входная головка может двигаться на одну ячейку влево, оставаться неподвижной, либо двигаться на одну ячейку вправо.
Памятью распознавателя может быть любого типа хранилище информации. Предполагается, что алфавит памяти конечен и хранящаяся в памяти информация построена только из символов этого алфавита. Предполагается также, что в любой момент времени можно конечными средствами описать содержимое и структуру памяти, хотя с течением времени память может становиться сколь угодно большой.
Поведение вспомогательной памяти для заданного класса распознавателей можно охарактеризовать с помощью двух функций: функции доступа и функция преобразования памяти.
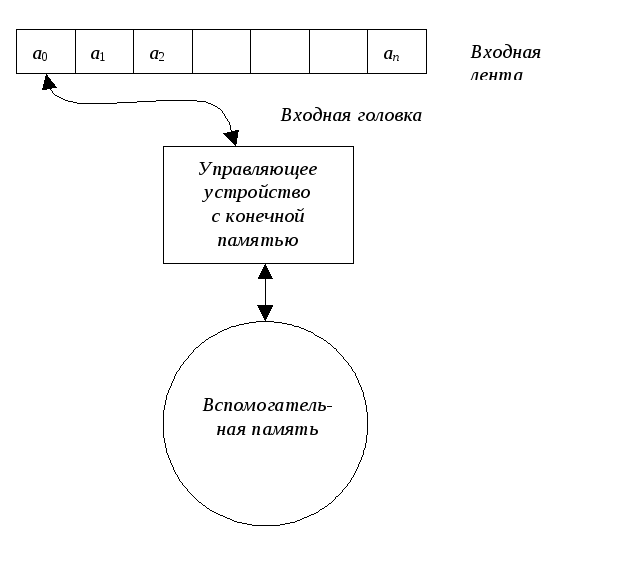
Рис. 3.1. Распознаватель
Функция доступа к памяти – это отображение множества возможных состояний или конфигураций памяти в конечное множество информационных символов.
Функция преобразования памяти – это отображения, описывающие её изменения. Вообще, именно тип памяти определяет название распознавателя (распознаватель магазинного типа).
Управляющее устройство – это программа, управляющая поведением распознавателя. Управляющее устройство представляет собой конечное множество состояний вместе с отображением, которое описывает, как меняются состояния в соответствии с текущим входным символом (т.е. находящимся под входной головкой) и текущей информацией, извлечённой из памяти. Управляющее устройство определяет также, в каком направлении сдвинуть головку и какую информацию поместить в память.
Распознаватель работает, проделывая некоторую последовательность шагов или тактов.
В начале такта читается текущий входной символ и с помощью функций доступа исследуется память. Текущий символ и информация, извлечённая из памяти, вместе с текущим состоянием управляющего устройства определяет, каким должен быть такт. Собственно такт состоит из следующих моментов:
входная головка сдвигается на одну ячейку влево, вправо или остаётся в исходном положении;
в памяти помещается некоторая информация;
изменяется состояние управляющего устройства.
Поведение распознавателя обычно описывается в терминах конфигураций распознавателя. Конфигурация – это «мгновенный снимок» распознавателя, на котором изображены:
состояние управляющего устройства;
содержимое входной ленты вместе с положением головки;
содержимое памяти.
Управляющее устройство может быть детерминированным либо недетерминированным.
В детерминированном устройстве для каждой конфигурации существует не более одного возможного следующего шага.
Недетерминированное устройство – это просто удобная математическая абстракция, не реализуемая на практике.
Конфигурация называется начальной, если управляющее устройство находится в начальном состоянии – входная головка обозревает самый левый символ, и память имеет заранее установленное начальное содержимое.
Конфигурация называется заключительной, если управляющее устройство находится в одном из состояний заранее выделенного множества заключительных состояний, а входная головка обозревает правый концевой маркер.
Распознаватель допускает входную цепочку , если, начиная с начальной конфигурации, в которой цепочка записана на входной ленте, распознаватель может проделать конечную последовательность шагов, заканчивающуюся конечной конфигурацией.
Язык, определяемый распознавателем – это множество входных цепочек, которые он допускает.
Для каждого класса грамматик из иерархии Хомского существует естественный класс распознавателей:
язык L праволинейный тогда и только тогда, когда он определяется односторонним детерминирванным конечным автоматом;
язык L – контекстно-свободный тогда и только тогда, когда он определяется односторонним недетерминированным автома-том с магазинной памятью;
язык L контекстно-зависимый тогда и только тогда, когда он определяется двусторонним недетерминированным линейно-ограниченным автоматом;
язык L рекурсивно перечисляемый тогда и только тогда, когда он определяется машиной Тьюринга.