

2.7. Генератор кода
Дерево, построенное синтаксическим анализатором, используется для того, чтобы получить перевод входной программы. Этот перевод может быть программой в машинном коде, но чаще всего он бывает программой на промежуточном языке, таком как ассемблер или трехадресный код (из операторов, содержащих не более 3 идентификаторов).
Если требуется, чтобы компилятор произвел существенную оптимизацию кода, то предпочтительно использовать трехадресный код, т.к. он не использует промежуточные регистры, привязанные к конкретному типу машин.
В качестве примера рассмотрим машину с одним регистром и команды языка типа «ассемблер» (табл. 2.2).
Запись С(m)сумматор – означает, что содержимое ячейки памятиmнадо поместить в сумматор. Запись =mозначает численное значениеm.
Таблица 2.2. - Команды «типа запись ассемблер»
|
Команда |
Действие |
|
LOAD m |
C(m)сумматор |
|
ADD m |
С(сумматор)+C(m)сумматор |
|
MPY m |
С(сумматор)*C(m)сумматор |
|
STORE m |
С(сумматор)m |
|
LOAD=a |
mсумматор |
|
ADD=m |
С(сумматор)+mсумматор |
|
MPY=m |
С(сумматор)*mсумматор |
С помощью дерева, полученного синтаксическим анализатором, и информации, хранящейся в таблице имен, можно построить объектный код.
Существует несколько методов построения промежуточного кода по синтаксическому дереву. Наиболее изящный из них называется синтаксическим управляемым переводом. В нем с каждой вершинойnсвязывается цепочкаC(n) промежуточного кода. Код для этой вершиныnстроится сцеплением в фиксированном порядке кодовых цепочек, связанных с прямыми потомками вершиныn, и некоторых фиксированных цепочек. Процесс перевода идет, таким образом, снизу вверх (от листьев к корню). Фиксированные цепочки и фиксированный порядок задаются используемым алгоритмом перевода.
Здесь возникает важная проблема: для каждой вершины nнеобходимо выбрать кодC(n) так, чтобы код, приписываемый корню, оказывался искомым кодом всего оператора. Вообще говоря, нужна какая-то интерпретация кодаC(n),которой можно было бы единообразно пользоваться во всех ситуациях, где встретится вершинаn.
Для математических операторов присвоения нужная интерпретация получается весьма естественно. В общем случае при применении синтаксически управляемой трансляции интерпретация должна задаваться создателем компилятора.
В качестве примера рассмотрим синтаксически управляемую трансляцию арифметических выражений. Вернемся к исходному дереву.

Допустим, что есть три типа внутренних вершин, зависящих от того, каким из знаков помечен средний потомок =, +, *. Эти три типа вершин можно изобразить:
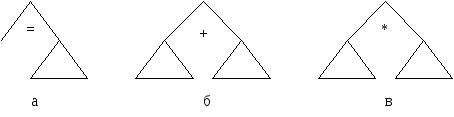
где - произвольные поддеревья (в том числе состоящие из единственной вершины).
Для любого арифметического оператора присвоения, включающего только арифметические операции + и *, можно построить дерево с одной вершиной (типаа) и остальными вершинами только типовбив.
Код соответствующей вершины будет иметь следующую интерпретацию:
если n– вершина типаа, тоC(n) будет кодом, который вычисляет значение выражения, соответствующее правому поддереву, и помещает его в ячейку, зарезервированную для идентификатора, которым помечен левый поток;
если n– вершина типабилив, то цепочка LOAD C(n) будет кодом, засылающим в сумматор значение выражения, соответствующего поддереву, над которым доминирует вершинаn.
Так, для нашего дерева код LOAD C(n1) засылает в сумматор значение выражения <ИД2>+<ИД3>,код LOADC(n2) засылает в сумматор значение выражения (<ИД2>+<ИД3>)*<ИД4>, а кодC(n3) засылает в сумматор значение последнего выражения и помещает его в ячейку, предназначенную для <ИД1>.
Теперь надо
показать, как код C(n) строится
из кодов потомков вершиныn. В
дальнейшем мы будем предполагать, что
операторы языка ассемблера записываются
в виде одной цепочки и отделяются друг
от друга точкой с запятой или началом
новой строки. Кроме того, мы будем
предполагать, что каждой вершинеnдерева приписывается числоl(n),
называемое уровнем, которое означает
максимальную длину пути от этой вершины
до листа, т.е. l(n)=0, еслиn– лист, а еслиn имеет потомковn1,
n2,…, n k, то![]() .
.
Уровни l(n) можно вычислить снизу вверх одновременно с вычислением кодовC(n) (рис. 2.3).
Уровни записываются, для того чтобы контролировать использование временных ячеек памяти. Две нужные нам величины нельзя заслать в одну и ту же ячейку памяти.
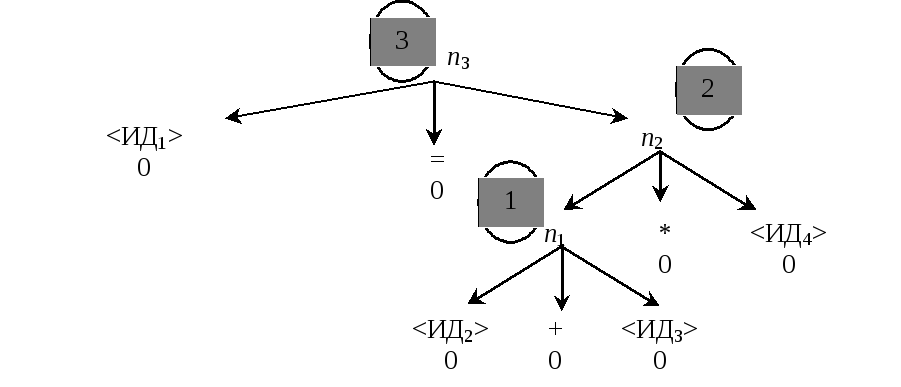
Рис. 2.3. Дерево с уровнями
Теперь определим синтаксически управляемый алгоритм генерации кода, предназначенный для вычисления кода C(n) всех вершин дерева, состоящих из листьев корня типааи внутренних вершин типабив.