

8. Эквивалентность мп-автоматов и кс-грамматик
В практических приложениях нас больше будут интересовать детерминированные МП-автоматы, т.е. такие, которые в каждой конфигурации могут сделать не более одного очередного такта. Языки, определяемые детерминированными МП-автоматами, называются детерминированными КС-языками, а их грамматики - LR(k)-грамматиками.
Определение.
МП-автомат
![]() называетсядетерминированным
(ДМП),
если для каждых
называетсядетерминированным
(ДМП),
если для каждых
![]() и
и![]() либо
либо
 содержит
не более одного элемента для каждого
содержит
не более одного элемента для каждого
 и
и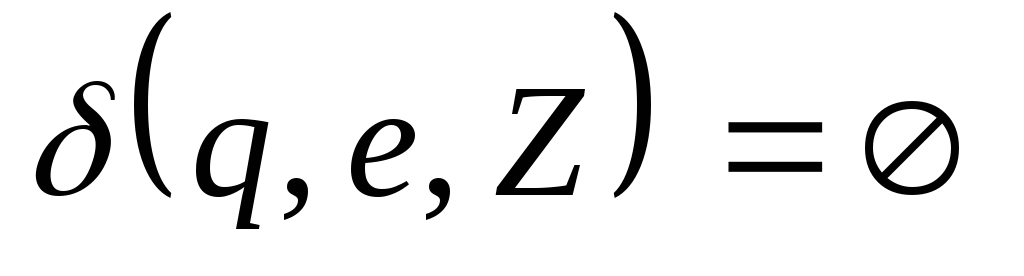 ,
либо
,
либо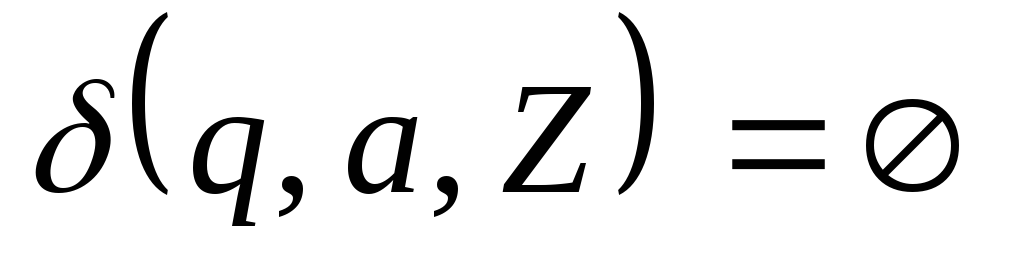 для
всех
для
всех
 и
и содержит не более одного элемента.
содержит не более одного элемента.
Соглашение.
Так
как ДМП-автомат содержит не более одного
элемента, мы будем писать
![]() вместо
вместо![]() .
.
Как уже отмечалось, однотактовые детерминированные МП-автоматы порождают КС-языки, которые называются LR(k)-грамматиками. Те в свою очередь являются частным случаем s-грамматик.
Определение. s-грамматика представляет собой грамматику, в которой:
правые части каждого порождающего правила начинаются с терминала;
в тех случаях, когда в левой части более чем одного порождающего правила появляется нетерминал, соответствующие правые части начинаются с различных терминалов.
Первое условие аналогично утверждению, что грамматика находится в нормальной форме Грейбах, только за терминалом в начале каждой правой части правила могут следовать нетерминалы и/или терминалы.
Второе условие соответствует существованию детерминированного одношагового МП-автомата.
Пример.
|
SpX SqY XaXb |
Xx YaYd Yy |
Рассмотрим проблему разбора строки paaaxbbb с помощью заданной s-грамматики. Начав с символа S, попытаемся генерировать строку, применяя левосторонний вывод. Результаты приведены в табл. 4.1.
Таблица 4.1.
|
Исходная строка |
Вывод |
|
paaaxbbb paaaxbbb paaaxbbb paaaxbbb paaaxbbb paaaxbbb |
S PX PaXb PaaXbb PaaaXbbb Paaaxbbb |
9. Разбор снизу вверх
Мы рассмотрели проблему левостороннего разбора как частный случай синтаксического анализа. Обобщая выводы, можно констатировать, что методы разбора могут быть нисходящими, т.е. идущими от стартового символа к предложению, и восходящими - от предложения к стартовому символу. Предложения, читаемые слева направо, норма для большинства естественных языков, хотя проблема разбора в них не всегда тривиальна. Однако ряд естественных языков и языков программирования имеют другую структуру. В этом случае удобнее использовать правосторонний вывод и соответствующие грамматики. Эти грамматики называются LR-грамматиками и в синтаксическом разборе используют технологию снизу вверх.
Синтаксические анализаторы, работающие по этому принципу, сводят предложения языка к начальному символу путем последовательного применения правил грамматики.
Рассмотрим, например, язык, генерируемый правилами
S real IDLIST
IDLIST IDLIST, ID
IDLIST ID
ID A B C D.
Предложение real A, B, C принадлежит этому языку и может быть разобрано по следующей схеме. Каждый символ, считанный анализатором, немедленно помещается в стек анализатора.
real A, B, C real
real A, B, C A
real
Стрелка ставится непосредственно после последнего считанного символа. Затем анализатор заменяет А с помощью правила 4). Это действие называется приведение. Правые части правил заменяются их соответствующими левыми частями.
real A, B, C ID
real
Далее применяется правило (3) для выполнения другого приведения.
real A, B, C IDLIST
real
Теперь анализатор считывает следующий символ
,
real A, B, C IDLIST
real
и другой
В
,
real A, B, C IDLIST
real
Очередные два действия – приведение с использованием правил 4) и 2)
ID
,
real A, B, C IDLIST
real
real A, B, C IDLIS
real
и последующим считыванием еще двух символов
,
real A, B, C IDLIST
real
С
,
real A, B, C IDLIST
real
Последние три действия – это приведение с использованием правил 4), 2) и 1).
ID
,
real A, B, C IDLIST
real
real A, B, C IDLIST
real
real A, B, C S
Разбор считается завершенным, когда в стеке останется только начальный символ и предложение считано целиком. Стек разбора соответствует части автомата с магазинной памятью.
Синтаксический анализатор, работающий по принципу «снизу вверх», выполняет действия двух типов:
сдвиг, во время которого считывается и помещается в стек символ. Это соответствует движению на один пункт вдоль какого-нибудь правила грамматики;
приведение, во время которого множество элементов в верхней части стека замещаются каким-либо нетерминалом грамматики с помощью одного из порождающих правил этой грамматики.