

Лабораторная работа №6
.pdfПостроение дерева решений
Методика построения дерева решения основана на рекурсивном разбиении множества объектов из обучающей выборки на подмножества, содержащие объекты, относящиеся к одинаковым классам. В первую очередь выбирается независимая переменная, которая помещается в корень дерева. Из вершины строятся ветви, соответствующие всем возможным значениям выбранной независимой переменной. Множество объектов из обучающей выборки разбивается на несколько подмножеств в соответствии со значением выбранной независимой переменной. Таким образом, в каждом подмножестве будут находиться объекты, у которых значение выбранной независимой переменной будет одно и то же.
Пусть нам задано некоторое множество T, содержащее объекты (примеры),
каждый из которых характеризуется m атрибутами, причем один из них указывает на принадлежность объекта к определенному классу. Идею построения деревьев решений из множества T, впервые высказанную Хантом, приведем по Р.
Куинлену (R. Quinlan). Пусть через {C1, C2, ... Ck} обозначены классы (значения метки класса), тогда существуют 3 ситуации:
1.Множество T содержит один или более примеров, относящихся к одному классу Ck. Тогда дерево решений для Т – это лист, определяющий класс Ck;
2.Множество T не содержит ни одного примера, т.е. пустое множество. Тогда это снова лист, и класс, ассоциированный с листом, выбирается из другого множества отличного от T, скажем, из множества, ассоциированного с родителем;
3.Множество T содержит примеры, относящиеся к разным классам. В этом случае следует разбить множество T на некоторые подмножества. Для этого выбирается один из признаков, имеющий два и более отличных друг от друга значений O1, O2, ... On. T разбивается на подмножества T1, T2, ... Tn, где каждое подмножество Ti содержит все примеры, имеющие значение Oi для
11

выбранного признака. Это процедура будет рекурсивно продолжаться до тех пор, пока конечное множество не будет состоять из примеров,
относящихся к одному и тому же классу.
Вышеописанная процедура лежит в основе многих современных алгоритмов построения деревьев решений, этот метод известен еще под названием разделения и захвата (divide and conquer). Очевидно, что при использовании данной методики, построение дерева решений будет происходить сверху вниз. Поскольку все объекты были заранее отнесены к известным нам классам, такой процесс построения дерева решений называется обучением с учителем (supervised learning). Процесс обучения также называют индуктивным обучением или индукцией деревьев (tree induction).
В машинном обучении популярными алгоритмами построения деревьев решений являются: ID3, C4.5, CART, CHAID и другие.
Этапы построения деревьев решений
При построении деревьев решений особое внимание уделяется следующим вопросам: выбору критерия атрибута, по которому пойдет разбиение, остановки обучения и отсечения ветвей. Рассмотрим все эти вопросы по порядку.
1.Правило разбиения. Для построения дерева на каждом внутреннем узле необходимо найти такое условие (проверку), которое бы разбивало множество, ассоциированное с этим узлом на подмножества. В качестве такой проверки должен быть выбран один из атрибутов. Общее правило для выбора атрибута можно сформулировать следующим образом: выбранный атрибут должен разбить множество так, чтобы получаемые в итоге подмножества состояли из объектов, принадлежащих к одному классу, или были максимально приближены к этому, т.е. количество объектов из других классов ("примесей") в каждом из этих множеств было как можно меньше.
12

Были разработаны различные критерии, но мы рассмотрим только два из них:
a)Теоретико-информационный критерий. Алгоритм C4.5,
усовершенствованная версия алгоритма ID3 (Iterative Dichotomizer),
использует теоретико-информационный подход. Для выбора наиболее подходящего атрибута, предлагается следующий критерий:
Gain X Info T Infox T (1)
n |
|
T |
|
|
|
|
|||
где, Info T – энтропия множества T, а Infox T |
|
|
|
i |
|
|
Info Ti |
(2) |
|
|
|
||||||||
|
|
|
T |
|
|
|
|||
|
|
|
|
||||||
i 1 |
|
|
|
|
|
|
|
||
Множества T1, T2, ... Tn получены при разбиении исходного множества
T по проверке X. Выбирается атрибут, дающий максимальное значение по критерию (1). В теории информации энтропией называют меру беспорядочности множества – по сути, меру его неоднородности.
b)Статистический критерий. Алгоритм CART (Classification and Regression Tree) использует так называемый индекс (коэффициент)
Джини (в честь итальянского экономиста Corrado Gini), который
оценивает "расстояние" между распределениями классов |
(3). |
Gini C 1 p2j (3)
j
где C – текущий узел, а pj – вероятность класса j в узле C. CART был предложен Л. Брейманом (L.Breiman). Коэффициент Джини определяет вероятность того, что при случайном выборе образца и категории окажется, что образец не принадлежит к указанной категории.
2.Правило остановки. Разбивать дальше узел или отметить его как лист? В
дополнение к основному методу построения деревьев решений были предложены следующие правила:
13

a)Использование статистических методов для оценки целесообразности дальнейшего разбиения, так называемая "ранняя остановка". В конечном счете "ранняя остановка" процесса построения привлекательна в плане экономии времени обучения, но здесь уместно сделать одно важное предостережение: этот подход строит менее точные классификационные модели и поэтому ранняя остановка крайне нежелательна.
b)Ограничить глубину дерева. Остановить дальнейшее построение, если разбиение ведет к дереву с глубиной превышающей заданное значение.
c)Разбиение должно быть нетривиальным, т.е. получившиеся в результате узлы должны содержать не менее заданного количества примеров. Этот список эвристических правил можно продолжить, но на сегодняшний день не существует такого, которое бы имело большую практическую ценность.
3.Правило отсечения. Каким образом ветви дерева должны отсекаться? Очень часто алгоритмы построения деревьев решений дают сложные деревья,
которые "переполнены данными", имеют много узлов и ветвей. Такие
"ветвистые" деревья очень трудно понять. К тому же ветвистое дерево,
имеющее много узлов, разбивает обучающее множество на все большее количество подмножеств, состоящих из всѐ меньшего количества объектов.
Ценность правила, справедливого скажем для 2-3 объектов, крайне низка, и
в целях анализа данных такое правило практически непригодно. Гораздо предпочтительнее иметь дерево, состоящее из малого количества узлов,
которым бы соответствовало большое количество объектов из обучающей выборки. Для решения вышеописанной проблемы часто применяется так называемое отсечение ветвей (pruning). Пусть под точностью
(распознавания) дерева решений понимается отношение правильно классифицированных объектов при обучении к общему количеству объектов из обучающего множества, а под ошибкой – количество неправильно классифицированных. Предположим, что нам известен способ
14

оценки ошибки дерева, ветвей и листьев. Тогда, возможно использовать следующее простое правило: построить дерево; отсечь или заменить поддеревом те ветви, которые не приведут к возрастанию ошибки. В
отличие от процесса построения, отсечение ветвей происходит снизу вверх,
двигаясь с листьев дерева, отмечая узлы как листья, либо заменяя их поддеревом. Хотя отсечение не является панацеей, но в большинстве практических задач дает хорошие результаты, что позволяет говорить о правомерности использования подобной методики.
Ни один алгоритм построения дерева нельзя априори считать наилучшим или совершенным, подтверждение целесообразности использования конкретного алгоритма должно быть проверено и подтверждено экспериментом. Благодаря простоте интерпретации деревья решений являются одним из самых широко используемых методов добычи данных в анализе бизнеса, принятии решений в медицине и в выработке стратегии. Часто дерево решений создается автоматически, эксперт на его основе выделяет ключевые факторы, а затем уточняет дерево. Эта процедура позволяет эксперту воспользоваться помощью машины, а возможность наблюдать за процессом рассуждений помогает оценить качество прогноза. Деревья решений применяются в таких приложениях, как профилирование клиентов, анализ финансовых рисков, помощь в диагностике и транспортное прогнозирование.
Ход работы
1.Рассмотрим практическую задачу прогнозирования с помощью деревьев решений. Многие онлайновые сайты, в том числе аптеки, медицинские и фармацевтические порталы, взимающие плату за услуги или за каждое использование, предлагают пользователям сначала немного поработать с веб-приложением, а только потом производить оплату. Если речь идет об услугах, то сайт обычно предлагает бесплатную пробную версию с ограниченным временем или же с урезанными возможностями. Сайты,
15

взимающие плату за каждое использование, могут предложить один бесплатный сеанс или еще что-то в этом роде. Когда сайт с большим числом посетителей развертывает новое приложение, предлагая бесплатный доступ и подписку, оно может привлечь тысячи новых пользователей. Многие из них просто движимы любопытством и на самом деле в этом приложении не заинтересованы, поэтому вероятность того, что они станут платными клиентами, крайне мала. Из-за этого трудно выделить потенциальных клиентов, на которых стоит акцентировать маркетинговые усилия,
поэтому многие сайты прибегают к массовой рассылке писем всем открывшим учетную запись, вместо того чтобы действовать более целенаправленно. Для решения этой проблемы было бы полезно уметь прогнозировать вероятность того, что некий пользователь станет платным клиентом. Однако в данном случае очень важна четкость – если вы знаете,
какие факторы указывают на то, что пользователь может стать клиентом, то можете использовать эту информацию при выработке рекламной стратегии,
для того чтобы сделать некоторые разделы сайты более легкодоступными или для придумывания других способов увеличения количества платных клиентов. Мы будем рассматривать гипотетическое онлайновое приложение,
которое предлагается бесплатно на пробный период. Пользователь регистрируется для пробной работы, на какое-то число дней получает доступ к сайту, а потом должен решить, хочет ли он перейти на базовое или премиальное обслуживание. После того как пользователь зарегистрировался,
о нем собирается информация, а в конце пробного периода владельцы сайта узнают, какие пользователи решили стать платными клиентами. Чтобы не раздражать пользователей и завершить регистрацию как можно скорее,
сайт не просит заполнять длинную анкету. Он собирает информацию из протоколов сервера, например: с какого сайта пользователь попал сюда, его географическое положение, сколько страниц он просмотрел, прежде чем зарегистрировался, и т. д. Если собрать все эти данные и свести их в таблицу, то получится что-то похожее на табл. 1.
16

Табл. 1. Поведение пользователя на сайте и окончательное решение об
оплате.
Откуда |
|
Читал ли |
Сколько |
Выбранное |
|
Местонахождение |
страниц |
||||
пришёл |
FAQ |
обслуживание |
|||
|
посмотрел? |
||||
|
|
|
|
||
Pharmshop |
Киев |
Да |
18 |
Нет |
|
|
|
|
|
|
|
Днепропетровск |
Да |
23 |
Премиальное |
||
|
|
|
|
|
|
Pharmamedia |
Киев |
Да |
24 |
Базовое |
|
|
|
|
|
|
|
Medlinks |
Днепропетровск |
Да |
23 |
Базовое |
|
|
|
|
|
|
|
Запорожье |
Нет |
21 |
Премиальное |
||
|
|
|
|
|
|
напрямую |
Одесса |
Нет |
12 |
Нет |
|
|
|
|
|
|
|
напрямую |
Запорожье |
Нет |
21 |
Базовое |
|
|
|
|
|
|
|
Киев |
Нет |
24 |
Премиальное |
||
|
|
|
|
|
|
Pharmshop |
Днепропетровск |
Да |
19 |
Нет |
|
|
|
|
|
|
|
Pharmamedia |
Киев |
Нет |
18 |
Нет |
|
|
|
|
|
|
|
Запорожье |
Нет |
18 |
Нет |
||
|
|
|
|
|
|
Medlinks |
Запорожье |
Нет |
19 |
Нет |
|
|
|
|
|
|
|
Pharmamedia |
Одесса |
Да |
12 |
Базовое |
|
|
|
|
|
|
|
Запорожье |
Да |
18 |
Базовое |
||
|
|
|
|
|
|
Medlinks |
Днепропетровск |
Да |
19 |
Базовое |
|
|
|
|
|
|
2.Далее на основании данных таблицы нужно построить дерево решений,
аналогичное тому, которое изображено на рис. 2. Для этого можно использовать один из описанных выше алгоритмов.
3.Имея дерево решений, нетрудно понять, как оно принимает решения.
Достаточно проследовать вниз по дереву, правильно отвечая на вопросы, –
и в конечном итоге вы доберетесь до ответа. Обратная трассировка от узла,
в котором вы остановились, до корня дает обоснование выработанной классификации. Рис. 6. Это визуальное представление процедуры,
выполняемой деревом решений при попытке классифицировать новый образец. В корневом узле проверяется условие «Пришѐл с Google?». Если это условие выполнено, то мы идем по ветви и обнаруживаем, что каждый пользователь, пришедший с Google, становится платным пользователем,
если просмотрел 21 страницу или более. Если условие не выполнено, мы
17
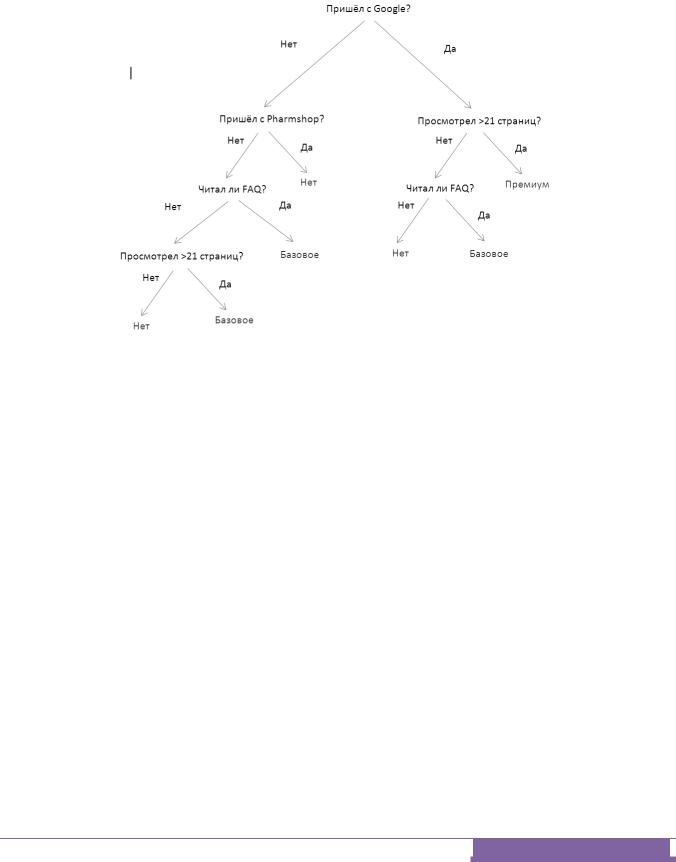
идем по противоположной ветви и проверяем условие «Пришѐл с
Pharmshop?». Так продолжается до тех пор, пока мы не достигнем узла с результатами. Как уже упоминалось выше, возможность увидеть логику рассуждений – одно из существенных достоинств деревьев решений.
Рис. 6. Дерево решений, полученное в результате работы алгоритма.
4.Рассмотрим вопрос хранения дерева решений в базе данных. Создайте класс
TreeNode, в котором будем хранить информацию об узлах дерева. При этом всѐ дерево будет представлено совокупностью его узлов, как узлов проверок, так и листовых узлов. На рисунке 6 показано так называемое
двоичное дерево — древовидная структура данных, в которой каждый узел имеет не более двух потомков (детей). В созданном классе добавьте свойства: Quest – будем хранить вопросы узлов проверки или пустое значение для листовых узлов; Result – будем хранить значения листовых узлов, для узлов проверки храним пустое значение; LeftFalse – будем хранить объектную ссылку на потомок узла по ветке «Нет»; RightTrue –
будем хранить объектную ссылку на потомок узла по ветке «Да». Листинг
1.
18

Лист. 1. Описание класса TreeNode.
Class User.TreeNode Extends %Persistent
{
//Вопрос (только для нелистовых узлов) Property Quest As %String(MAXLEN = 200); //Результат (только для листовых узлов)
Property Result As %String(MAXLEN = 200);
//Объектная ссылка на левый узел - в случае отрицательного ответа на вопрос //Только для нелистовых узлов
Property LeftFalse As User.TreeNode;
//Объектная ссылка на правый узел (в случае положительного ответа на вопрос) //Только для нелистовых узлов
Property RightTrue As User.TreeNode;
}
5.Рассмотрим процедуру логического вывода на созданной структуре.
Концептуальное описание алгоритма выглядит следующим образом.
a)Открываем очередной узел по его ID, начиная с корневого узла,
проверяем, является ли он листовым? Если да, то показываем его значение и завершаем процедуру логического вывода. В противном случае показываем вопрос и ожидаем ввод ответов («Да» или «Нет»).
b)Анализируем ответ пользователя, если это положительный ответ «Да», то повторяем пункт а) для правого узла. Если это отрицательный ответ
«Нет», то повторяем пункт а) для левого узла.
Создадим метод класса Classify(), выполняющий данную процедуру на языке программирования Cache. Листинг 2.
Лист. 2. Описание рекурсивного метода Classify().
ClassMethod Classify(Node As User.TreeNode)
{
//Открываем очередной узел.
s NextNode=##class(User.TreeNode).%OpenId(Node)
//Если этот узел является листовым, то выводим результат. if NextNode.Result'="" { w NextNode.Result q }
//Иначе выводим на экран вопрос и два варианта ответа ("Да" и "Нет") else {
w NextNode.Quest,!, r Answer,!
if Answer="Да" { d ..Classify(NextNode.RightTrue.%Id()) } elseif Answer="Нет" { d ..Classify(NextNode.LeftFalse.%Id()) }
19

else { w "Ошибка!" q }
}
q
}
6. Чтобы проверить работоспособность метода выполните в Терминале
d ##class(User.TreeNode).Classify(1)
Рис. 7. Пример работы с приложением.
7.Самостоятельно разработайте дерево решений, используя свои профессиональные знания, и внесите его в базу знаний.
Вопросы для самоподготовки
1.Что такое СППР? Для чего они нужны? В каких областях применяются?
2.Что такое «хранилища данных»? Как они применяются в СППР?
3.Раскройте суть многомерного представления данных с помощью OLAP системы.
4.Из каких трѐх стадий состоит процесс интеллектуального анализа данных?
5.Как деревья решений могут быть использованы в СППР?
6.Опишите рекурсивный алгоритм построения дерева решений.
7.Теоретико-информационный критерий выбора атрибута при разбиении узла. Что такое энтропия с точки зрения теории информации?
20