

1_Медицинские ИПС.Базы дан
.pdf11
Набор объектов
Группа всех подобных объектов образует набор объектов. Так, наборами объектов могут быть :
1.Все студенты медицинского университета
2.Все фармпрепараты, которые применяются на Украине
3.Все заболевания изучаемые на мед.факультете
4.Все эмоции
Примеры 1 и 2 показывают, что термин "подобные объекты не является точно определенным, и можно установить бесконечное число различных свойств, которые будут определять набор объектов.
Первый ключевым моментов в проектировании модели реального мира, имеющий отношение к конкретной базе данных является выбор наборов объектов.
Атрибуты и ключи
Объекты обладают свойствами, называемыми атрибутами, которые ассоциируют некоторое значение из домена значений данного атрибута с каждым объектом в наборе объектов. Обычно домен атрибута является множеством целых чисел, действительных чисел или строк литер, но мы не исключаем и другие типы значений.
Элемент данных или атрибут - характеристика объекта, которая определяется именем и совокупностью некоторых значений (величин). Атрибутами могут быть, например, НОМЕР_ЗАЧЕТКИ, ДАТА_РОЖДЕНИЯ, ЦЕНА, БАНКОВСКИЙ_БАЛАНС и т.д. Каждый атрибут может иметь значения различного типа: числовые, логические, символьные, в виде записи и т.д. Его наименование должно быть уникальным для конкретного типа объекта, но может быть одинаковым для различных типов объектов.
По своему назначению атрибуты делятся на идентифицирующие (или ключевые) и описательные.
Каждый экземпляр идентифицирующего атрибута ИО или (иден-
тификатора) соотносится не более чем с одним экземпляром этой ИО, т.е. между идентифицирующим атрибутом и любым другим существует однозначная ассоциация по типу идентифицирующего атрибута, что дает возможность использовать идентифицирующий атрибут для доступа к другим атрибутам и однозначно задавать экземпляры объекта. Атрибут или множество атрибутов, значение которых уникально идентифицируют каждый объект в наборе объектов, называется ключевым атрибутом или первичным ключом. Выбирать ключевые атрибуты следует осо-
12
бенно тщательно, поскольку правильный выбор способствует созданию достоверной концептуальной модели данных.
При разработке базы данных студентов университета в качестве ключевого атрибута можем выбрать <Фамилию, Имя, Отчество> студента. Однако после анализа мы видим, что иногда ФИО может совпадать. Более эффективным первичным ключом является <Номер Зачетной Книжки>, который не повторяется и является уникальным идентификатором данного информационного объекта. При формировании БД лекарственных препаратов, в качестве ключевого атрибута удобно использовать номенклатурный номер лек.препарата.
В принципе, каждый набор объектов имеет ключ, поскольку мы приняли гипотезу о том, что каждый объект отличим от остальных. Но если для набора объектов мы выбрали совокупность атрибутов, не содержащую ключа, то отличить один объект от другого окажется невозможным. Если сложно выделить идентифицирующий атрибут, то им может стать порядковый номер ИО, который присваивается при занесении его в БД.
Например, каждый пациент в поликлинике имеет свой регистрационный номер, который соответствует порядковому номеру присеваемом при первой регистрации.
Выбор подходящих атрибутов для набора объектов является вторым ключевым моментом в проектировании модели реального мира.
Возможны случаи, когда объекты в наборе различаются не по атрибутам, а по их связи с объектами другого типа. Наиболее важным видом "встроенных связей является связь есть. Мы говорим А есть В и записываем "А есть В", если набор объектов В является обобщением набора объектов А, или, что равносильно, А есть специальный вид В.
Значение данных представляет действительные данные, содержащиеся в каждом элементе данных. В зависимости от того, как элементы данных описывают объект, их значения могут быть количественными, качественными или описательными. Принимаемые элементами данных значения называются данными. Единичный набор принимаемых элементами данных значений называется экземпляром объекта.
Объекты связываются между собой с помощью отношений. Соответствующая модель объектов с составляющими их элементами данных и их взаимосвязями называется концептуальной моделью. Концептуальная модель дает общее представление о потоке данных в предметной области.
13
Логическое проектирование
На этапе концептуального проектирования данные рассматриваются без учета специфики используемой СУБД., а особенности физического хранения БД в памяти ЭВМ включаются в описание ее структуры на этапе физического проектирования. Этап между концептуальным и физическим проектированием, в результате которого получается СУБДориентированная схема БД, называется логическим проектированием. Преобразования структуры БД на этом этапе определяются стремлением удовлетворить требованиям конкретной СУБД и общим ограничениям, специфицированным в требованиях пользователей.
Логическое проектирование заключатся в структурировании концептуального описания ПО средствами одной из известных моделей данных с привязкой к ограничениям конкретных СУБД, используемых для поддержания баз данных, а также в проектировании функциональных спецификаций программных модулей.
Основной задачей логического проектирования является разра-
ботка СУБД - ориентированной схемы, которая удовлетворяет всему диапазону требований целостности и непротиворечивости проектируемой БД и кончая показателями эффективности функционирования при ее модификациях.
Логическое проектирование практически состоит в тщательном документировании в виде схемы всей имеющейся в распоряжении разработчика номенклатуры данных, требований и ограничений. Для того, чтобы сформулировать СУБД - ориентированную схему БД, изоморфную относительно концептуальной схемы, необходимы характеристики моделей данных, поддерживаемых конкретной СУБД.
На первом шаге логического проектирования на основе анализа содержания каждого требования обработки данных выделяются локальные информационные структуры, удовлетворяющие всем требованиям каждого соответствующего приложения.
Второй шаг логического проектирования состоит в формулировании СУБД - ориентированной логической схемы БД.
На третьем шаге проводится количественная оценка СУБД - ориентированной схемы БД по объему обработки.
Четвертый шаг по усовершенствованию схемы с целью повышения ее эффективности не затрагивает содержания данных, так как основная задача этого шага адаптировать схему к различным способам представления данных.
Типы баз данных
При разработке логической модели БД прежде всего необходимо решить какая модель данных наиболее подходит для отображения кон-
14
кретной концептуальной модели предметной области. Известны три наиболее распространенные модели данных : реляционная, иерархическая и сетевая.
Реляционная модель
Реляционная модель БД, введенная Коддом, основывается на математической теории отношений, в основе которой лежит понятие отношения между элементами множества. Набор отношений между данными, которые преобразуются и изменяются во времени, представляют собой реляционную модель данных. Основным преимуществом реляционного подхода является независимость обращения к данным от способа их структурной организации.
Отношения задаются в виде таблицы. Столбцы таблицы называются простыми доменами или просто доменам. Каждый домен должен иметь свое имя. Преобразование отношений основано на операциях над доменами: некоторые из них могут исключаться, добавляться, меняться их расположение в отношении и т.д. Важно, чтобы строки в отношении были разные. Если в результате операции над отношениями появляются одинаковые строки, то в результирующем отношении оставляется любая из одинаковых строк.
В общем случае 2n-арное отношение обладает следующими свойствами:
каждая строка представляет собой n-ку или кортеж из отношения;
все строки различны;
порядок строк не играет роли;
домены могут быть пронумерованы, т.е. отношение упорядочено по доменам.
Пример.
Рассмотрим отношение степени 3, названное ОБУЧАТЬ:
ОБУЧАТЬ (СТУДЕНТ, ПРЕДМЕТ, ЛЕКТОР)
СТУДЕНТ |
ПРЕДМЕТ |
ЛЕКТОР |
Викторов |
ХИМИЯ |
доц.Краснов |
В.Н. |
|
П.С. |
Шипова М.В. |
ФИЗИКА |
доц.Ушаков |
|
|
И.П. |
15
Железнов |
ФИЗИКА |
проф.Сушков |
В.В. |
|
В.П |
На практике в процессе преобразования доменов удобнее идентифицировать домены по именам. Так, в указанном примере отношение обучать может быть записано в виде ОБУЧАТЬ (С,П,Л), где С - имя СТУДЕНТ, П - имя ПРЕДМЕТ, Л - имя ЛЕКТОР.
Удобнее для пользователя применять для доменов уникальные имена, что позволяет манипулировать ими без использования позиции, в которой находится домен. В случае двух или более ключей один из них выбирается произвольно в качестве основного ключа отношения. Таким ключом в отношении ОБУЧАТЬ является домен СТУДЕНТ, он же и основной ключ. Смысл выделения основных ключей заключается в том, чтобы обеспечить возможность ссылок на n-ки того же самого или другого отношения.
Реляционная модель данных является концепцией, которая легка для понимания и имеет много возможных приложений. Реляционная база данных состоит из набора "плоских файлов", или таблиц называемых отношениями, которые в свою очередь включают кортежи (экземпляры записей) и атрибуты (элементарные типы), значения которого выбираются из простого домена. Связи между отношениями неявно определены на перекрывающихся доменах. Используя общую информацию, например такую, как уникальный ключ исходной записи для поиска ее порожденных записей, можно проектировать преобразования между основными моделями данных. В реляционных базах данных связь типа "исходный порожденный" реализуется путем определения домена в порожденной записи, содержащей ключевой элементарный тип исходной записи. Однако реляционная модель предоставляет гораздо большие возможности по сравнению с простым преобразованием данных.
Иерархическая модель
Иерархические БД хранят данные в виде записей, сгруппированных в наборы, отображающие древовидную структуру информации. Такая структура БД отображает тот факт, что данные об управляемом или исследуемом объекте упорядочены по подчиненности, т.е. в их структуре отображена семантика отношений с точностью до некоторых уровней.
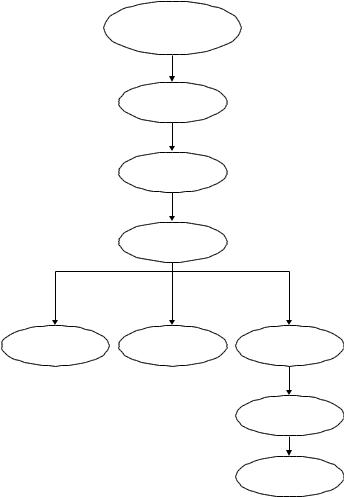
16
Иерархическая модель - является графом древовидной структуры, где вершины могут представлять наборы объектов, а сыновья ассоциируются с атрибутами ИО. Однако упорядочение в иерархию возможно только по одному признаку. Иначе говоря, в любой реальной системе принцип иерархичности реализуется только по наиболее существенному отношению подчиненности, а при рассмотрении всевозможных взаимосвязей у каждого подчиненного элемента, как правило, более одного связанного с ним исходного элемента. Рассмотрение структуры объекта с более полным набором взаимосвязей приводит к сетевой модели объекта и соответственно к БД с сетевой структурой
Фармацевтический
факультет
КУРС
ГРУППА
№ зачетной книжки
Паспорные ФИО Успеваемость
данные
Учебная
дисциплина
Оценки
Рис. Пример иерархической организации базы данных
Описание графа древовидной структуры
Дерево представляет собой иерархию элементов, называемых узлами. На самом верхнем уровне иерархии имеется только один узел - корень. Каждый узел, кроме корня, связан с одним узлом на более высоком уровне, называется исходным узлом для данного узла. Ни один элемент не имеет более одного исходного. Каждый элемент может быть
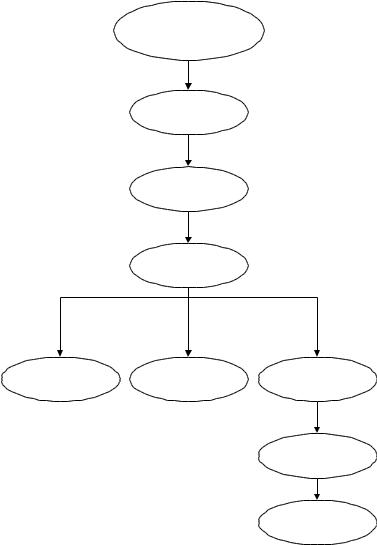
17
связан с одним или несколькими элементами на более низком уровне. Они называются порожденными. Элементы, расположенные в конце ветви, т.е. не имеющие порожденных, называются листьями. Дерево обычно изображается в перевернутом виде - с корнем вверху и листьями внизу. Деревья применяются как для логического, так и для физического описания данных. В логическом описании данных они используются для определения связей между типами сегментов или типами записей, а при определении физической организации данных - для описания набора указателей и связей между элементами в индексах.
Фармацевтический
факультет
КУРС
ГРУППА
№ зачетной книжки
Паспорные ФИО Успеваемость
данные
Учебная
дисциплина
Оценки
18
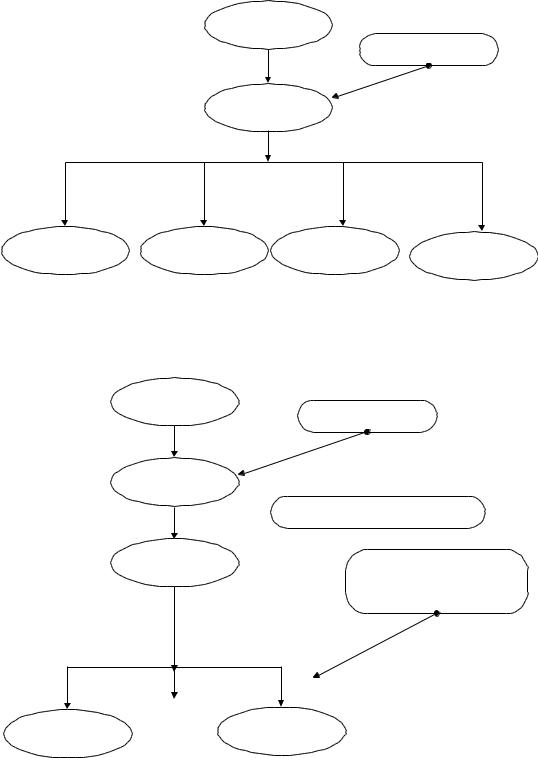
Организация быстрого доступа к объектам БД повторичномуключу
Схема формирования индексных массивов
^Библ
Первичный ключ
Порядковый
№
Автор |
Название |
Издание |
Ключевые |
|
книги |
||||
|
|
слова |
||
|
|
|
Основной массив базы данных по литературе
^Index
Вторичный ключ
Название
Атрибута
Значение вторичного ключа
Значение Атрибута Ссылки на объекты БД
имеющие значение втричного ключа
Значение |
. . . |
Значение |
1-го ключа 1 |
1-го ключа N |
Индексный массив базы данных по литературе
]
19
Объектно-ориентированные базы данных (ООБД) по сравнению с традиционными (например, реляционными) БД обеспечивают следующие преимущества: во-первых, в таких БД хранятся не только данные, но и методы их обработки, инкапсулированные в одном объекте; во-вторых, ООБД позволяют обрабатывать мультимедийные данные; в-третьих, ООБД допускают работу на высоком уровне абстракции; в-четвертых, ООБД позволяют пользователям создавать структуры данных любой сложности.
Отличительной особенностью СУБД Cachй является независимость хранения данных от способа их представления, что реализуется с помощью, так называемой, единой архитектуры данных Cachй. В рамках данной архитектуры существует единое описание объектов и таблиц, отображаемых непосредственно в многомерные структуры ядра базы данных, ориентированных на обработку транзакций [1]. Как только определяется класс объектов, Cachй автоматически генерирует реляционное описание данных этого класса в формате SQL. Подобным же образом, как только в Словарь данных поступает DDL-описание в формате реляционной базы данных, Cachй автоматически генерирует реляционное и объектное описание данных, устанавливая тем самым доступ в формате объектов. При этом все описания ведутся согласованно, все операции по редактированию проводятся только с одним описанием данных. Это позволяет сократить время разработки, сэкономить вычислительные ресурсы и приложения будут работать значительно быстрее.
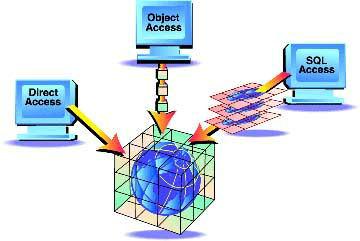
В Cache’ реализована концепция Единой архитектуры данных. К одним и тем же данным, хранящимся под управлением Сервера многомерных данных Cache’ есть три способа доступа: прямой, объектный и реля-
Рисунок 2. Концепция Единой архитектуры данных
Cache’.
ционный:
20
Cache’ Direct Access - прямой доступ к данным, обеспечивает максимальную производительность и полный контроль со стороны программиста. Разработчики приложений получают возможность работать напрямую со структурами хранения. Использование этого типа доступа накладывает определенные требования на квалификацию разработчиков, но понимание структуры хранения данных в Cache’ позволяет оптимизировать хранение данных приложения и создавать сверхбыстрые алгоритмы обработки данных.
Cache’ SQL - реляционный доступ, обеспечивающий максимальную производительность реляционных приложений с использованием встроенного SQL. Cache’ SQL соответствует стандарту SQL 92. Кроме этого, разработчик может использовать разные типы триггеров и хранимых процедур. Все это позволяет Cache’ успешно конкурировать с реляционными СУБД. Даже без использования прямого и объектного доступа приложения на Cache’ работают быстрее за счет высокой производительности Сервера многомерных данных.
Cache’ Objects - объектный доступ, для максимальной продуктивности разработки при использовании Java, Visual C++, VB и других ActiveXсовместимых средств разработки, таких как PowerBuilder и Delphi. В Cache’ реализована объектная модель в соответствии с рекомендациями ODMG (Группа управления объектными базами данных – Object Database Management Group). В Cache’ полностью поддерживаются наследование (в том числе и множественное), инкапсуляция и полиморфизм. При создании информационной системы разработчик получает возможность использовать объектно-ориентированный подход к разработке, моделируя предметную область в виде совокупности классов объектов, в которых хранятся данные (свойства классов) и поведение классов (методы классов). Cache’, поддерживая объектную модель данных, позволяет естественным образом использовать объектно-ориентированный подход как при проектировании (в Rational Rose) предметной области, так и при реализации приложений в ОО-средствах разработки (Java, C++, Delphi, VB). Постреляционная СУБД Cache’ конкурирует с объектными СУБД, значительно превосходя их по таким показателям как надежность, производительность и удобство разработки.
Как уже отмечалось, разработчик имеет три способа доступа к одним и тем же данным. Как только определяется класс объектов, Cache’ автоматически генерирует реляционное описание этих данных так, что к ним можно обращаться, используя SQL. Подобным же образом, при импорте в словарь данных DDL-описания реляционной базы данных, Cache’ автоматически генерирует реляционное и объектное описание данных, открывая тем самым доступ к данным как к объектам. При этом все описания данных ведутся согласованно, все операции по редактированию про-