

Моделирование бизнес-процессов / Моделирование бизнес-процессов / ERwin_Insider_2
.pdfThe fleeting thought that the stored procedure editor can just be the method editor as well is just that, fleeting. Methods can be written in any language including Java, C, and PL/SQL etc.
A new folder tab would have to be created to allow for the building of methods either within ERwin or to attach to code residing somewhere else.
Fig. 5
In upcoming version 4.0, one could create a very pseudo-operation area by using the new drawing objects feature. You would create the operations area box under the entity, fill in the text and then "group" the drawing object with the entity. The group feature will be similar to the group feature in Power Point, which allows the user to take various drawing objects and group them together as one object. Of course, there would be no functionality behind the drawing object. Very crude, but one would get the visual effect.
From the modeling standpoint making provisions for most of the new data types is straightforward. They just have to be added to the pallet of data types available. On the back end Erwin would have to generate whatever DLL is required to forward engineer.
Pointers, including REFs and OIDs could simply be additions to the data type list. Obviously behind the scenes, as with all the object extensions, Erwin would have to generate the appropriate DDL.
Representing collections (a.k.a. arrays & nested tables) is a little trickier. Collections exist, (in IDEF1X terms ) as tables embedded into another table in a one to many, non-identifying relationship. The embedded table is obviously, on the "many" side of the relationship.
The concept of grouping attributes should not be totally foreign to the IDEF1X practitioner. Although I was not able to locate any thing about group attributes in FIPS 184, Thomas Bruce6, defines the group attribute as a "collection of other attributes called constituents"7, and introduces ways to represent them. 8
In fact arrays and nested tables, could simply be visually represented by one data type called array and one data type called nested table. When choosing the data type named array or nested table, the attribute editor could then bring up a collection sub-window which would ask the user to enter the attributes for that data
6Federal Information Processing Standards Publication 184, 1993 December 21. FIPS 184 is the Federal standards document which defines
IDEF1X.
7pps. 102, 119, 135 Designing Quality Databases with IDEF1X Information Models by Thomas Bruce 1992 Dorset House ISBN 0- 932633-18-8
8ibid 136-138
© 2000 Computer Associates International, Inc. (CA). All trademarks, trade names, service marks, and logos |
21 |
referenced herein belong to their respective companies. |
|

type. The collections, attributes with data type, description etc. could remain behind the scenes on the sub window with only the data type indicating that there is something behind the scenes that may have to be looked at. This solution would keep the diagram simple, but really does not visually give the whole picture.
Arrays vs Nested Tables
"Nested tables are unlimited in size and can be sparse; therefore, elements within the nested table can be deleted using the DELETE procedure. Variable-size arrays have a maximum size and maintain their order
and subscript when stored in the database...Variable -size arrays are suited for batch operations in which the application processes the data in batch array style." (Oracle 8i Web Design, Oracle Press/Osborn/Mcgraw Hill, 2000)
"Objects within a VARRAY are stored directly with the master record, achieving optimal performance. Objects within nested tables are actually stored independent of the master table and therefore require an index for optimal retrieval." (Oracle 8 Design Using UML Object Modeling, Oracle Press/Osborn/Mcgraw Hill, 1999)
Further discussion is beyond the scope of this article.
In a vain somewhat similar to Bruce's ideas, one could suggest that nested tables and arrays should be represented by entity/table style boxes with a dotted border. Arrays names would be prefixed by "A_" and nested tables would be prefixed by "N_". These representations would be similar to the way views are
depicted (dashed |
lines and prefixed by "V_".) |
|
The relationship |
line indicating to which table the |
|
collection belongs |
should not be a standard IDEF1x |
|
relationship |
symbol. Hence the introduction of |
|
a new symbol such |
as the solid line (indicating |
|
dependency) with a |
circle (indicating that this is a |
|
different type of |
relationship.) |
|
|
|
|
Figure 6 - Collection
© 2000 Computer Associates International, Inc. (CA). All trademarks, trade names, service marks, and logos |
22 |
referenced herein belong to their respective companies. |
|

Figure 7 - Collapsed Collection
This solution would be acceptable if an array or nested table were only used once in a model. If the address array was used multiple times in a database the diagram could become cluttered and busy. An alternative solution would introduce expandable column grouping. The array or nested table would then appear in its collapsed form as any other column and data type. Adjacent to the collapsed column would be an indicator, like an explorer style +, aâ, or a a, indicating that this column is a nested table which can be expanded. Switching on the expand option would result in full display of the embedded table.
Figure 8 - Expanded Collection
© 2000 Computer Associates International, Inc. (CA). All trademarks, trade names, service marks, and logos |
23 |
referenced herein belong to their respective companies. |
|

The domain dictionary editor could be used as a very effective and efficient tool for frequently used groups of attributes/columns required for collections. The dictionary editor could be enhanced to allow groupings to be created with a designator e.g. check box or radio button under the general or DBMS folder tab allowing the modeler to designate a grouping as one which would become an embedded table when copied into a table.
Figure 9 Domain Dictionary Editor
Fig 10. Collapsed Collection
© 2000 Computer Associates International, Inc. (CA). All trademarks, trade names, service marks, and logos |
24 |
referenced herein belong to their respective companies. |
|

Fig. 11 Expanded Collection
The addition of a collection editor may be appropriate. Whatever the case, Erwin will have to be prepared
Fig. 12 Collection Editor
to create collections in some fashion.
© 2000 Computer Associates International, Inc. (CA). All trademarks, trade names, service marks, and logos |
25 |
referenced herein belong to their respective companies. |
|

Object types, also known as abstract data types can be created by users to suit their needs. Zip codes with their zip code plus four, or phone numbers with country code, area code, local exchange, and extension number are just two examples of where this could be helpful. These could be handled in a fashion similar to
Fig. 13 Collapsed Abstract Data Type
collections. The figures below show how abstract data types could be displayed.
Fig. 14 Expanded Abstract Data Type
The kind of editing we currently find in Erwin's domain editor, specifically, the ability to create levels may have to be brought over to the attribute editor.
© 2000 Computer Associates International, Inc. (CA). All trademarks, trade names, service marks, and logos |
26 |
referenced herein belong to their respective companies. |
|

Representation of these data types in the model could be somewhat similar to the way collections are represented Figures 15 & 16 show examples of how collapsed and expanded abstract data types could be presented.
Fig. 15 Collapsed Abstract Data Type
Figure 16 Expanded Abstract Data Type
© 2000 Computer Associates International, Inc. (CA). All trademarks, trade names, service marks, and logos |
27 |
referenced herein belong to their respective companies. |
|
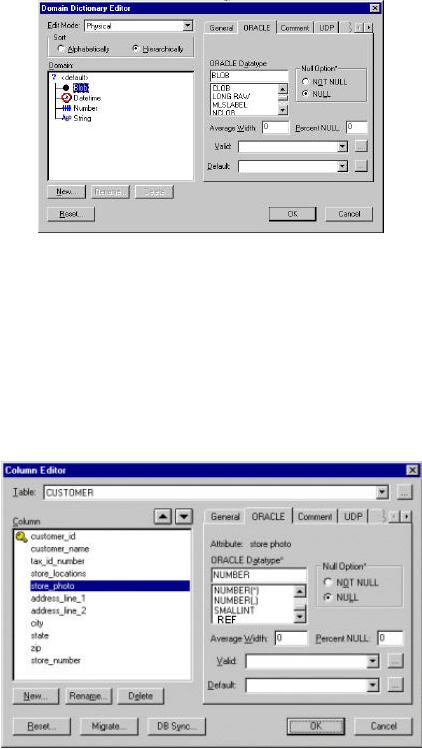
Fig. 17 LOBs
Large object data types (LOB) are nothing new to Erwin. Version 3.5.2 already provides for various LOBs as indicated in fig. 17.
Pointers are a chapter borrowed from IT history. It' s like deja vu all over again and brings back memories of chained files and more recently, network databases.
Currently in Oracles flavor of ORDBMS there are two kinds of pointers. REFs and IODs. REF s are references to columns in another table or even a flat file outside the database. They would be used, for example, when storing a blob of some kind would be better placed in another table space or in a flat file. The REF may point to a seldom-referenced blob or very large multimedia clips may be stored in a table or flat file.
Fig. 18 REF
In purely object database OIDs, or Object Ids are used exclusively in place of keys. These are data base generated numbers, used once, and never again. ORDBMS offer the choice of using a traditional key or an
© 2000 Computer Associates International, Inc. (CA). All trademarks, trade names, service marks, and logos |
28 |
referenced herein belong to their respective companies. |
|

Fig. 19 OID
OID. Here again, there are advantages and disadvantages to both. "..[OIDs}…provide globally unique identifiers that are important for many applications, especially distributed processing and replication. However they an overhead of increased storage requirements and increased loading time."9
There are other database features, not directly related to object relational, which could have an effect on the future release of Erwin. Extensible indexing for example. This feature allows uses to extend a database to use an indexing method not necessarily part of the database tool set. Complex data types may bring on complex indexing methods. The ability to cluster tables is another feature that appears to have been requested by some users. These issues are beyond the scope of this article.
What about beyond 4.5 will IDEF1X and IE take on more "objectivity"? Will Paradigm Plus, CA's UML tool take on "IDEF1X-ity". Will UML and IDEF1X merge into IDEFML or UMDEF1X? Will ERwin become Paraerwin or Erwindigm?
The shift toward OO is for sure. Where that will leave IDEF1X, and other ER notations is not clear at the moment. But on the immediate horizon, these are the major constructs of the object meta-model which have been melded with traditional relational structures to form the object relational paradigm. Whether additional object concepts and constructs invade the object relational paradigm remains to be seen. But for now at least if Erwin is to keep pace with the latest data base technology these issue will have to be addressed in version 4.5. 

9 Getting to Know Oracle 8I (Document #A76962-01), 1999 Oracle Corporation
© 2000 Computer Associates International, Inc. (CA). All trademarks, trade names, service marks, and logos |
29 |
referenced herein belong to their respective companies. |
|

Vendors Be Normal
Ben Ettlinger
Data Administrator
New York Power Authority
President
New York Enterprise Modeling User Group
10In a nutshell, it's frustration. You get the feeling that many software vendors think that all you need is their product and that there is no other software supporting your business. At least that's the impression when you look at the vendor's database structure. Few if any software used to support a company's information technology enterprise infrastructure, stands as a totally independent island. Even those companies that have implemented a massive ERP solution, still have a need to pull out data, whether it be for a data mart, data warehouse, or to supply information to other systems that support their business process. The vendor provided interfaces are sometimes just not enough or not what you need. You want to be able to get into the data structures and see how the data is stored to fully understand the business rules inherent in the database. You may not even want to extract anything. All one may just be interested in is an understanding of the business rules and data requirements inherent to the vendor database in order to match them against a data model of your business. As the Data Administrator of the largest State owned utility in the US, I have often been asked to compare existing business rules and data requirements against those employed by vendor provided solutions. It's just such a comparison that makes it much easier to determining your data superfluity or deficiencies against theirs.
Whether software vendors like it or not, once you've implemented the application at your site, it's a snap to reverse engineer the database. Any data modeling tool worth it's salt can reverse engineer a database of hundreds of tables into an ER diagram within minutes. Using CA-Erwin, I recently reverse engineered a 400 table vendor created Oracle database in less than five minutes.
If vendors can't stop you from looking at their database, and you can create this picture in a flash, why the frustration? Simple. I have yet to come across a vendor solution that has even some semblance of normality. We're not even talking fourth normal form. How about first or second normal form? It looks like many vendors think Codd is a fish or a place in Massachusetts. It is understandable that a physical implementation may require some de-normalization (albeit sparingly), but at least in that de-normalization it should not be difficult to work backwards to visualize the database in its normalcy. However if no level of normalization was employed, understanding the data and associated rules becomes a daunting task.
I have come across databases that are skimpy on implementing a DBMS's relationship constraints. Many of the "relationships" between tables are implied using, pseudo foreign keys. These pseudo foreign keys are created by placing two matching fields with matching content in two or more tables. The connection between the two tables is by virtue of the fact that the data in two columns matches, rather than an actual database relationship construct matching a key and it's foreign key mirror image. The application code is then responsible to make sure both are in sync. This leaves the database integrity wide open to compromise as there is no DBMS check in place should there be a change to one side of the pseudo relationship.
Other vendors rely on database triggers to maintain relationships between tables. This may be a bit sounder in that the database is tasked to maintain integrity. From the analysis standpoint, one problem is that the constraints maintained by the triggers are not explicit when examining the database structure. One has to study the trigger code or documentation (and we know all these things are always well documented <g>) in order to realize that the constraint exists. Why can't it be done the right way with a relationship?
10 This article appeared in the Aug. 4, 2000 edition of the DM Magazine Weekly on-line newsletter.
© 2000 Computer Associates International, Inc. (CA). All trademarks, trade names, service marks, and logos |
30 |
referenced herein belong to their respective companies. |
|