

Лекции по информатике / Раздел08(Базы данных)
.pdfБАЗЫ ДАННЫХ
Слайд 1 Слайд 2
8.1 Общее понятие о базах данных. Основные понятия систем управления базами данных и банками знаний.
Слайд 3
Основные понятия БД
Современные информационные системы характеризуются программными объемами,
необходимостью |
удовлетворять |
разнообразные |
требования |
многочисленных |
пользователей. |
|
|
|
|
Цель любой информационной системы обработка данных об объектах реального |
||||
мира. В широком смысле слова БД |
это совокупность сведений о конкретных объектах |
|||
реального мира в какой либо предметной области.
Предметная область 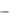 это часть реального мира, подлежащего изучению для организации управления и в конечном счете автоматизации, например, предприятие, вуз и т.д.
это часть реального мира, подлежащего изучению для организации управления и в конечном счете автоматизации, например, предприятие, вуз и т.д.
Всовременной технологии БД предполагается, что создание БД, ее поддержка
иобеспечение доступа пользователей к ней осуществляется централизованно с
помощью специального программного инструментария |
СУБД. |
|
БД |
поименная совокупность структурированных |
данных, относящихся к |
определенной предметной области. |
|
|
СУБД |
комплекс программных и языковых средств, необходимых для создания баз |
|
данных, поддержания их в актуальном состоянии и организации поиска в них необходимой информации.
Слайд 4
Создавая БД, пользователь стремится упорядочить информацию по различным признакам и быстро извлекать выборку с произвольным сочетанием признаков. Сделать это можно, только если данные структурированы.
Структурирование это введение соглашений о способах представления данных. Неструктурированные данные.
Личное дело № 16943, Сергеев Петр Михайлович, дата рождения 1 января 1976г.; Личное дело №16593 Петрова Анна Владимировна, дата рождения 15.03.75 Личное дело №16693 Анохин Андрей Борисович, дата рождения 14.04.76
Структурированные данные.
№ личного дела |
Фамилия |
Имя |
Отчество |
Дата рождения |
|
|
|
|
|
16493 |
Сергеев |
Петр |
Михайлович |
01.01.76 |
|
|
|
|
|
16593 |
Петрова |
Анна |
Владимировна |
15.03.75 |
|
|
|
|
|
16693 |
Анохин |
Андрей |
Борисович |
14.04.76 |
|
|
|
|
|
1
Слайд 5
Классификация баз данных.
По технологии обработки данных БД подразделяются на централизованные и распределенные.
Централизованная БД хранится в памяти одной вычислительной системы. Если эта вычислительная система является компонентом сети ЭВМ, возможен распределенный доступ к такой базе. Такой способ использования БД часто применяют в локальных сетях ПК.
Распределенная БД состоит из нескольких, возможно пересекающихся или даже дублирующих друг друга частей, хранимых в различных ЭВМ вычислительной сети. Работа с такой базой осуществляется с помощью системы управления распределенной базы данных (СУРБД).
По способу доступа к данным БД разделяются на БД с локальным или с удаленным (сетевым) доступом.
Системы централизованных БД с сетевым доступом предполагают различные архитектуры подобных систем:
файл сервер; клиент сервер.
Файл сервер. Архитектура систем БД с сетевым доступом предполагает выделение одной из машин сети в качестве центральной (сервер файлов). На такой машине хранится совместно используемая централизованная БД. Все другие машины сети выполняют функции рабочих станций, с помощью которых осуществляется доступ пользователей системы к централизованной БД. Файлы БД в соответствии с пользовательскими запросами передаются на рабочие станции, где производится обработка. При большой интенсивности доступа к одним и тем же данным производительность информационной системы падает. Пользователи могут создавать так же на рабочих станциях локальные БД, которые используются ими монопольно.
Файл сервер |
Хранение |
Передача файлов БД для обработки
Обработка
Рабочие станции
Схема обработки информации в БД по принципу файл сервер
Клиент  сервер. В этой концепции подразумевается, что помимо хранения централизованной БД центральная машина (сервер БД) должна обеспечивать выполнение основного объема обработки данных. Запрос на данные, выдаваемый клиентом (рабочей станцией), порождает поиск и извлечение данных на сервере. Извлеченные данные (но не файлы) транспортируются по сети от сервера к клиенту. Спецификой архитектуры клиент
сервер. В этой концепции подразумевается, что помимо хранения централизованной БД центральная машина (сервер БД) должна обеспечивать выполнение основного объема обработки данных. Запрос на данные, выдаваемый клиентом (рабочей станцией), порождает поиск и извлечение данных на сервере. Извлеченные данные (но не файлы) транспортируются по сети от сервера к клиенту. Спецификой архитектуры клиент
сервер является использование языка запросов SQL.
2

Слайд 6
Структурные элементы БД .
Понятие базы данных тесно связано с такими понятиями структурных элементов, как поле, запись, файл (таблица) (рис.1).
Поле – элементарная единица логической организации данных, которая соответствует неделимой единице информации – реквизиту. Для описания поля используются следующие характеристики:
Имя, например, фамилия, имя, отчество, дата рождения; Тип, например, символьный, числовой, календарный;
Длина, например, 15 байт, причем будет определяться максимально возможным числом символов;
Точность для числовых данных, например два десятичных знака для отображения дробной части числа.
Имя поля 1 |
Имя поля 2 |
Имя поля 3 |
Имя поля 4 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
ПОЛЕ |
ЗАПИСЬ |
Рис. 1. Основные структурные элементы БД.
Запись- совокупность логически связанных полей. Экземпляр записи – отдельная реализация записи, содержащая конкретные значения ее полей.
Файл(таблица) – совокупность экземпляров записей одной структуры.
Описание логической структуры записи файла содержит последовательность расположения полей записи и их основные характеристики, как это показано на рис.2.
Имя файла
Поле |
Призна |
|
Формат поля |
|
||
|
|
|
|
|
|
|
Имя |
Полное |
к ключа |
Тип |
Длина |
|
Точность |
(обозначение) |
наименование |
|
|
|||
|
|
|
|
|
||
Имя 1 |
|
|
|
|
|
|
|
|
|
|
|
|
|
… |
|
|
|
|
|
|
|
|
|
|
|
|
|
Имя n |
|
|
|
|
|
|
|
|
|
|
|
|
|
Рис.2. описание логической структуры записи файла.
В структуре записи файла указываются поля, значение которых являются ключами:
3

первичными (ПК), которые идентифицируют экземпляр записи, и вторичными (ВК),
которые выполняют роль поисковых или группировочных признаков (по значению
вторичного ключа можно найти несколько записей).
Пример 1.
На рис.3. приведен пример описания логической структуры записи файла(таблицы) СТУДЕНТ, содержимое которого приводится в вопросе №1. Структура записи файла СТУДЕНТ линейная, она содержит записи фиксированной длины. Повторяющиеся группы значения полей в записи отсутствуют. Обращение к значению поля производится по его номеру.
Имя файла : СТУДЕНТ
|
Поле |
Признак |
|
Формат поля |
|
|
Обозначение |
|
Наименование |
ключа |
Тип |
Длина |
Точность |
Номер |
|
№ личного дела |
* |
Число |
5 |
|
Фамилия |
|
Фамилия |
|
Симв |
15 |
|
|
студента |
|
|
|||
|
|
|
|
|
|
|
Имя |
|
Имя студента |
|
Симв |
10 |
|
Отчество |
|
Отчество |
|
Симв |
15 |
|
|
студента |
|
|
|||
|
|
|
|
|
|
|
Дата |
|
Дата рождения |
|
Дата |
8 |
|
Рис.3. описание логической структуры записи файла СТУДЕНТ
4

Слайд 7
Основные функции СУБД. Типовая организация СУБД
1. Непосредственное управление данными во внешней памяти.
Эта функция включает обеспечение необходимых структур внешней памяти как для хранения данных, непосредственно входящих в БД, так и для служебных целей.
Например: для устранения доступа к данным (используются индексы). 2. Управление буферами оперативной памяти.
СУБД обычно работают с БД значительного размера. Этот размер обычно существенно больше доступного объема оперативной памяти. Если при обращении к любому элементу данных будет производиться обмен с внешней памятью, то вся система будет работать со скоростью устройства внешней памяти. Единственным способом реального увеличения скорости является буферизация данных внешней памяти.
3. Управление транзакциями.
Транзакция  это последовательность операций над БД, рассматриваемых системой как единое целое. Либо транзакция успешно выполняется и СУБД фиксирует изменения в БД, произведенные этой транзакцией во внешней памяти, либо ни одно из этих изменений никак не отражается на БД.
это последовательность операций над БД, рассматриваемых системой как единое целое. Либо транзакция успешно выполняется и СУБД фиксирует изменения в БД, произведенные этой транзакцией во внешней памяти, либо ни одно из этих изменений никак не отражается на БД.
Понятие транзакции необходимо для поддержки логической целостности БД. Каждая транзакция начинается при целостном состоянии БД и оставляет это состояние целостным после своего завершения, и считается единицей активности пользователя по отношению к БД. С управлением транзакциями в многопользовательской СУБД связано важное понятие (сериализации транзакции и сериального плана выполнения смеси транзакций).
Под сериализацией понимается такой порядок транзакции, при котором суммарный эффект смеси транзакций эквивалентен эффекту их последовательного выполнения.
Сериальный план выполнения смеси транзакции это такой план, который приводит к сериализации транзакции.
Существует несколько базовых алгоритмов сериализации транзакций. В случае конфликта между транзакциями происходит так называемый откат, то есть отменяются все изменения, производимые в БД.
4. Журнализация.
Журнал  это особая часть БД, недоступная пользователям СУБД и поддерживаемая с особой тщательностью. Это недоступная часть СУБД, в которую поступают записи обо всех изменениях в БД.
это особая часть БД, недоступная пользователям СУБД и поддерживаемая с особой тщательностью. Это недоступная часть СУБД, в которую поступают записи обо всех изменениях в БД.
5. Поддержка языков БД.
Для работы с БД используются специальные языки, в целом называемые языками баз данных. В ранних СУБД поддерживалось несколько специализированных по своим функциям языков: SQL (для определения логической структуры БД, т.е. той структуры, которой она представляется пользователю); DML набор операторов манипулирования данными, то есть операторов, позволяющих заносить данные в БД (изменить существующие данные).
5

В современных СУБД обычно поддерживается единый интергированный язык, содержащий все необходимые средства для работы с БД.
Стандартным языком является SQL.
Слайд 8
Типовая организация современных СУБД.
1)Ядро СУБД;
2)Компилятор языка БД;
3) |
Набор утилитов |
служебных программ. |
|
1) |
Ядро содержит |
менеджеры данных: менеджер |
буфер оперативной памяти; |
|
менеджер транзакций и менеджер журнализации. |
|
|
2)Преобразует язык из записи пользователя во внутренний язык компьютера.
3)Загрузка, выгрузка БД, проверка авторизации и т.д.
6
8.2 Модели данных в информационных системах
Слайд 1 Слайд 2 Слайд 3
Прежде, чем перейти к детальному и последовательному изучению реляционных систем БД, остановимся коротко на ранних (дореляционных) СУБД. В этом есть смысл по трем причинам: во-первых, эти системы исторически предшествовали реляционным, и для правильного понимания причин повсеместного перехода к реляционным системам нужно знать хотя бы что-нибудь про их предшественников; во-вторых, внутренняя организация реляционных систем во многом основана на использовании методов ранних систем; в- третьих, некоторое знание в области ранних систем будет полезно для понимания путей развития постреляционных СУБД.
Заметим, что в этой лекции мы ограничиваемся рассмотрением только общих подходов к организации трех типов ранних систем, а именно, систем, основанных на инвертированных списках, иерархических и сетевых систем управления базами данных. Мы не будем касаться особенностей каких-либо конкретных систем; это привело бы к изложению многих технических деталей, которые, хотя и интересны, находятся несколько в стороне от основной цели нашего курса. Детали можно найти в рекомендованной литературе.
Начнем с некоторых наиболее общих характеристик ранних систем:
a.Эти системы активно использовались в течение многих лет, дольше, чем используется какая-либо из реляционных СУБД. На самом деле некоторые из ранних систем используются даже в наше время, накоплены громадные базы данных, и одной из актуальных проблем информационных систем является использование этих систем совместно с современными системами.
b.Все ранние системы не основывались на каких-либо абстрактных моделях. Как мы упоминали, понятие модели данных фактически вошло в обиход специалистов в области БД только вместе с реляционным подходом. Абстрактные представления ранних систем появились позже на основе анализа и выявления общих признаков у различных конкретных систем.
c.В ранних системах доступ к БД производился на уровне записей. Пользователи этих систем осуществляли явную навигацию в БД, используя языки программирования, расширенные функциями СУБД. Интерактивный доступ к БД поддерживался только путем создания соответствующих прикладных программ с собственным интерфейсом.
d.Навигационная природа ранних систем и доступ к данным на уровне записей заставляли пользователя самого производить всю оптимизацию доступа к БД, без какойлибо поддержки системы.
e.После появления реляционных систем большинство ранних систем было оснащено "реляционными" интерфейсами. Однако в большинстве случаев это не сделало их понастоящему реляционными системами, поскольку оставалась возможность манипулировать данными в естественном для них режиме.
Ядром любой базы данных является модель данных. Модель представляет собой множество структур данных, ограничений целостности и операций манипулирования
7

данными. С помощью модели данных могут быть представлены объекты предметной области и взаимосвязи между ними.
Модель данных – совокупность структур данных и операций их обработки.
СУБД основывается на использовании иерархической, сетевой или реляционной
модели, на комбинации этих моделей или на некотором их подмножестве.
Рассмотрим три основных типа моделей данных: на инвертированных списках, иерархическую и сетевую.
Слайд 4
Основные особенности систем, основанных на инвертированных списках
К числу наиболее известных и типичных представителей таких систем относятся
Datacom/DB компании Applied Data Research, Inc. (ADR), ориентированная на использование на машинах основного класса фирмы IBM, и Adabas компании Software
AG.
Организация доступа к данным на основе инвертированных списков используется практически во всех современных реляционных СУБД, но в этих системах пользователи не имеют непосредственного доступа к инвертированным спискам (индексам).
Структуры данных
БД представляет собой совокупность таблиц с данными и индексный файл 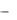 инвертированные списки. База данных, организованная с помощью инвертированных списков, похожа на реляционную БД, но с тем отличием, что хранимые таблицы и пути доступа к ним видны пользователям. При этом:
инвертированные списки. База данных, организованная с помощью инвертированных списков, похожа на реляционную БД, но с тем отличием, что хранимые таблицы и пути доступа к ним видны пользователям. При этом:
a.Строки таблиц упорядочены системой в некоторой физической последовательности.
b.Физическая упорядоченность строк всех таблиц может определяться и для всей БД (так делается, например, в Datacom/DB).
c.Для каждой таблицы можно определить произвольное число ключей поиска, для которых строятся индексы. Эти индексы автоматически поддерживаются системой, но явно видны пользователям.
Слайд 5
Манипулирование данными
Поддерживаются два класса операторов:
 Операторы, устанавливающие адрес записи, среди которых:
Операторы, устанавливающие адрес записи, среди которых:
прямые поисковые операторы (например, найти первую запись таблицы по некоторому пути доступа)
операторы, находящие запись в терминах относительной позиции от предыдущей записи по некоторому пути доступа.
8

 Операторы над адресуемыми записями
Операторы над адресуемыми записями
Слайд 6
Типичный набор операторов:
LOCATE FIRST - найти первую запись таблицы T в физическом порядке; возвращает адрес записи;
LOCATE FIRST WITH SEARCH KEY EQUAL - найти первую запись таблицы T с
заданным значением ключа поиска K; возвращает адрес записи;
LOCATE NEXT - найти первую запись, следующую за записью с заданным адресом в заданном пути доступа; возвращает адрес записи;
LOCATE NEXT WITH SEARCH KEY EQUAL - найти cледующую запись таблицы
T в порядке пути поиска с заданным значением K; должно быть соответствие между используемым способом сканирования и ключом K; возвращает адрес записи;
LOCATE FIRST WITH SEARCH KEY GREATER - найти первую запись таблицы T
в порядке ключа поиска K cо значением ключевого поля, большим заданного значения K; возвращает адрес записи;
RETRIVE - выбрать запись с указанным адресом;
UPDATE - обновить запись с указанным адресом;
DELETE - удалить запись с указанным адресом;
STORE - включить запись в указанную таблицу; операция генерирует адрес записи.
Ограничения целостности
Общие правила определения целостности БД отсутствуют. В некоторых системах поддерживаются ограничения уникальности значений некоторых полей, но в основном все возлагается на прикладную программу.
Слайд 7
Иерархическая модель данных
Типичным представителем (наиболее известным и распространенным) является
Information Management System (IMS) фирмы IBM. Первая версия появилась в 1968 г. До сих пор поддерживается много баз данных, что создает существенные проблемы с переходом, как на новую технологию БД, так и на новую технику.
Структура данных
Иерархическая БД состоит из упорядоченного набора деревьев; более точно, из упорядоченного набора нескольких экземпляров одного типа дерева.
Тип дерева состоит из одного "корневого" типа записи и упорядоченного набора из нуля или более типов поддеревьев (каждое из которых является некоторым типом дерева). Тип дерева в целом представляет собой иерархически организованный набор типов записи.
Пример типа дерева (схемы иерархической БД):
9
Здесь Отдел является предком для Начальник и Сотрудники, а Начальник и Сотрудники - потомки Отдел. Между типами записи поддерживаются связи.
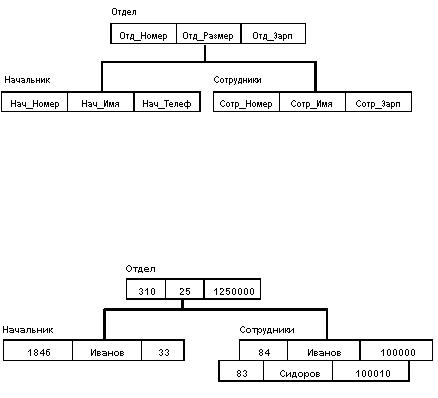
База данных с такой схемой могла бы выглядеть следующим образом (мы показываем один экземпляр дерева):
Все экземпляры данного типа потомка с общим экземпляром типа предка называются близнецами. Для БД определен полный порядок обхода - сверху-вниз, слева-направо.
Слайд 8
Манипулирование данными
Примерами типичных операторов манипулирования иерархически организованными данными могут быть следующие:
 Найти указанное дерево БД (например, отдел 310);
Найти указанное дерево БД (например, отдел 310);
 Перейти от одного дерева к другому;
Перейти от одного дерева к другому;
 Перейти от одной записи к другой внутри дерева (например, от отдела - к первому сотруднику);
Перейти от одной записи к другой внутри дерева (например, от отдела - к первому сотруднику);
 Перейти от одной записи к другой в порядке обхода иерархии;
Перейти от одной записи к другой в порядке обхода иерархии;
 Вставить новую запись в указанную позицию;
Вставить новую запись в указанную позицию;  Удалить текущую запись.
Удалить текущую запись.
Ограничения целостности
Автоматически поддерживается целостность ссылок между предками и потомками.
Основное правило: никакой потомок не может существовать без своего родителя.
Поддержание целостности по ссылкам между записями, не входящими в одну иерархию не поддерживается.
Слайд 9
Сетевые системы
Типичным представителем является Integrated Database Management System (IDMS) компании Cullinet Software, Inc., предназначенная для использования на машинах основного класса фирмы IBM под управлением большинства операционных систем. Архитектура системы основана на предложениях Data Base Task Group (DBTG) Комитета
10