

Лекция по xml / XML
.doc
XML. Лекция 1
Современный этап развития вычислительной техники характеризуется бурным ростом количества программных продуктов. Довольно часто возникает ситуация, когда результаты работы одного продукта являются входными данными для другого продукта, либо данные, хранимые и обрабатываемые одним продуктом должны быть импортированы в другой продукт. Другими словами, все более актуальной становится задача обмена данными между различными программными системами. Задача осложняется тем, что каждая система хранит данные в своем уникальном формате. Теоретически, для заранее известных форматов всегда можно написать конверторы. Такой подход имеет право на существование, однако далек от совершенства.
Например, если один из конвертируемых форматов претерпевает изменения, это влечет за собой переписывание программы-конвертора у принимающей стороны. Если предположить, что данными обмениваются не две системы, а несколько (например осуществляется обмен данными между информационными системами нескольких организаций), то модификация одного формата повлечет за собой модификацию конверторов у всех систем, получающих данные в модифицируемом формате. Таким образом, ни одна из сторон не сможет безболезненно модифицировать свой формат представления данных, поскольку это приведет к существенным накладным расходам у партнеров.
Решение проблемы заключается в выработке некоторого подхода, который позволил бы абстрагировать формат хранения данных от формата их передачи. Фактически, речь идет о создании промежуточного формата обмена данными, прозрачного для всех участников обмена. Система-источник должна конвертировать данные из своего формата в промежуточный, передавать их системе-приемнику, а та, в свою очередь, конвертировать данные из промежуточного формата в собственное представление. При подобном подходе каждая система должна иметь только один конвертор (преобразователь) данных из собственного формата в универсальный и обратно.
Универсальный формат должен носить описательный характер (содержать метаданные, описывающие структуру передаваемых данных) и иметь возможность описывать данные любой структуры и сложности (быть универсальным).
Попытки создать универсальный формат описания данных предпринимались еще на заре информационных технологий. Одним из первых универсальных способов описания данных стал язык SGML (Standard Generalized Markup Language) – стандартный обобщенный язык разметки. Фактически, этот язык лег в основу всех современных языков разметки, основным принципом которых является «наглядное» представление данных.
SGML разрабатывался в качестве стандартного языка разметки данных произвольного типа и наиболее широкое применение получил в системах документооборота. В виду высокой степени универсальности стандарт SGML получился крайне сложным и громоздким. Для того, чтобы упростить технологию, на базе SGML стали создавать упрощенные языки разметки, применяемые в узкоспециализированных областях. Одним из потомков SGML является язык HTML.
Однако узкоспециализированные языки решали узкий круг задач и не подходили для организации обмена данными между широким спектром информационных систем. Для решения проблемы была разработана технология универсального описания структурированных данных -XML. Аббревиатура XML расшифровывается как Extensible Markup Language – расширяемый язык разметки.
XML является максимально упрощенным вариантом SGML. XML – стандарт (набор правил) для описания языков разметки. Основной задачей XML является облегчение написания программного обеспечения для доступа к данным.
Поскольку XML является стандартом для разметки, XML документы представляют собой обычные текстовые файлы. Документы содержат в себе непосредственно данные и метаданные – разметку, описывающую структуру данных. Метаданные оформляются по определенным правилам в виде тегов.
Ниже приведен пример XML-документа, содержащего данные о пользователях (в данном примере представлена информация только для одного пользователя)
<?xml version="1.0" encoding="windows-1251" standalone="yes"?>
<?xml-stylesheet type='text/xsl' href='ex1.xsl'?>
<users>
<person status="1">
Administrator
<name>Иванов</name>
<age>25</age>
<login>guest</login>
<password/>
</person>
</users>
Теги (метаданные) в документе выделяются символами <> (угловые скобки). Название тега должно начинаться сразу после угловой скобки (пробелы между открывающей угловой скобкой и названием тега недопустимы).
Информация (данные) в документе располагаются между тегами. Теги всегда используются парами – каждому открывающему тегу должен соответствовать закрывающий тег. Закрывающий тег отличается от открывающего наличием слеша / между открывающей скобкой названием тега. Теги не могут перекрывать друг- друга:
запись вида <person><name></person></name> недопустима
В дальнейшем будет использоваться следующая терминология: пара тегов будет называться элементом, данные, расположенные между тегами будут называться значением элемента (в литературе вместо термина значения иногда используется термин DATA или PCDATA):
<name>Иванов</name>
Элемент name имеет значение Иванов.
Внутри элемента могут быть описаны другие элементы со своими значениями. Элемент может содержать пустое значение. В этом случае допускается краткая форма записи тегов:
Запись <password></password> аналогична <password/>
Теги (элементы) могут содержать неограниченное количество атрибутов. Атрибуты
представляют собой пары вида:
название=”значение”
Атрибут обязательно должен иметь значение (пустая строка является допустимым значением). У элемента не может быть более одного атрибута с одним и тем же названием.
и могут быть описаны только внутри открывающего тега:
<person status="1">
Атрибуты могут быть заменены соответствующими элементами и наоборот. Например, приведенная выше строка запись может быть представлена в виде
<person>
<status>1<status>
<person>
Выбор способа описания данных зависит от предпочтений разработчика. Предлагается описывать при помощи атрибутов метаданные, которые могут быть бесполезны для большей части приложений, обрабатывающих данные подобной структуры. Однако данное положение носит рекомендательный характер и его применение не обязательно.
В XML-документе обязательно должен быть корневой элемент (в данном примере корневым является элемент users). Корневой элемент может быть только один. Документ вида
<name>Иванов</name>
<name>Петров</name>
является некорректным. Правильным будет считаться документ:
<names>
<name>Иванов</name>
<name>Петров</name>
</names>
XML позволяет структурировать текст документа при помощи дополнительных символов форматирования (пробел, табуляция). Цепочки пробелов внутри значений элементов не игнорируются в случае, если значение элемента не является пустым.
XML чувствителен к регистру символов.
Помимо описания элементов и их значений, XML документы могут содержать декларации, которые необходимы для анализаторов. Декларации располагаются в начале документа.
<?xml version="1.0" encoding="windows-1251" standalone="yes"?>
Данная декларация сообщает анализатору используемую версию языка, кодировку, а так же то, что документ не связан с другими документами.
<?xml-stylesheet type='text/xsl' href='ex1.xsl'?>
Декларация сообщает анализатору о том, что документ связан с таблицей стилей для трансформации, хранящейся в файле ex1.xsl
Как было сказано выше,XML является набором правил для описания универсального формата передачи данных. Помимо представления данных в универсальном формате, второй по важности является задача трансформации (конвертирования) данных. Существуют разные способы анализа и конвертирования XML документов. Одним из наиболее распространенных способов является использование технологии XSLT – языка преобразований XML документов в любой текстовый формат. Например, довольно часто встречается задача конвертирования данных из XML в HTML и XSLT хорошо подходит для этой цели.
XSLT позволяет описать набор шаблонов для трансформации XML документа и путем применения ряда правил трансформировать исходный документ в формат, заданный шаблонами. Для осуществления трансформаций необходимо:
-
Получить исходный XML-документ
-
В отдельном файле описать шаблоны для трансформации в терминах XSLT
-
Подать XML-документ и файл с XSLT – шаблонами на вход специальной программе – XML анализатору.
-
На выход XML анализатора будет выведен результирующий файл заданного формата
Существуют разные версии XML анализаторов от разных производителей. Анализатор MSXML входит в комплект броузера Internet Explorer версии 5.0 и выше. Данный анализатор позволяет загружать XML документы и связанные с ним XSLT шаблоны, отображая результат работы в окне броузера (очевидно, что такой подход имеет смысл только в том случае, если XML трансформируется в HTML). Такой подход позволяет создавать сайты, состоящие из наборов XML и XSLT документов, при этом интерпретация этих документов будет осуществляться на стороне клиента. Примеры, приведенные ниже иллюстрируют именно такой способ обработки XML.
Прежде, чем перейти к более детальному описанию XSLT, необходимо познакомиться с одним из аспектов анализа XML документов, связанным с адресацией элементов внутри XML документа. Для адресации применяется специализированный язык запросов – XPath.
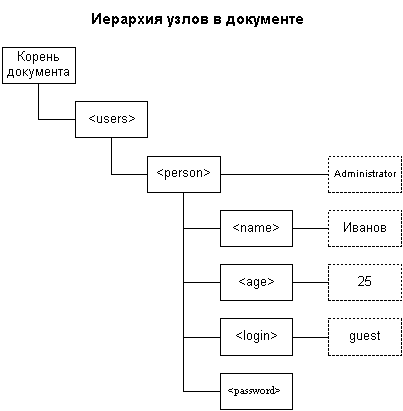
В XPath вводится понятие «узел». Под узлом может подразумеваться элемент либо атрибут. Также существует понятие «множество узлов» - совокупность узлов, сгруппированная по какому-либо признаку.
Выражения XPath используются для обращения к узлам документа посредством задания пути. Пути могут быть абсолютными (вычисляются относительно корня документа) и относительные (вычисляются относительно указанной точки в документе – т.н. контекстного узла).
С точки зрения XPath каждый документ начинается с корня, причем этот корень не является корневым элементом XML-документа. Фактически корень – абстрактная точка отсчета для формирования путей внутри документа. Корень обозначается при помощи слеша /
Корневой узел документа является потомком корня. В приведенном выше примере абсолютный адрес корневого элемента (узла) <users>
/users
Адрес узла <person>, являющегося потомком <users> выглядит следующим образом:
/users/person
Адрес узла <password> определяется как
/users/person/password
Подобным способом можно адресоваться к любому узлу документа.
При относительной адресации путь высчитывается относительно текущего контекстного узла. К самому контекстному узлу можно обратиться при помощи оператора . (точка). Адрес узла <login> относительно узла <users> следующим образом:
person/login
Ниже приведен пример простого XSLT шаблона
|
Пример 1 |
|
ex1.xml |
|
<?xml version="1.0" encoding="windows-1251" standalone="yes"?> <?xml-stylesheet type="text/xsl" href="ex1.xsl"?> <users> <person status="1"> Administrator <name>Иванов</name> <age>25</age> <login>guest</login> <password/> </person> </users> |
|
ex1.xsl |
|
<?xml version="1.0" encoding="windows-1251" standalone="yes"?> <xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform"> <xsl:template match="/"> <html><body> Имя: <b><xsl:value-of select="users/person/name"/></b><br/> Возраст:<i><xsl:value-of select="users/person/age"/></i><br/> Логин:<u><xsl:value-of select="users/person/login"/></u> </body></html> </xsl:template> </xsl:stylesheet> |
|
Результат |
|
Имя: Иванов Возраст:25 Логин:guest |
Шаблон начинается с декларации, аналогичной той, с которой начинается XML-документ.
Элемент <xsl:stylesheet> является контейнером для всех шаблонов. В качестве параметров элемент получает номер версии XSLT и адрес пространства имен (набора правил для формирования корректных документов). Параметр xmlns:xsl является обязательным и его значение должно быть равно http://www.w3.org/1999/XSL/Transform
Элемент <xsl:template> задает шаблон для трансформации. Параметр match задает адрес узла, к которому будет применен шаблон. В приведенном примере шаблон будет применен ко всему документу.
Элемент <xsl:value-of> выбирает из исходного документа значение заданного элемента (узла). Адрес узла задается при помощи параметра select.
Адресация узлов внутри шаблона может быть как относительной (относительно адреса, заданного параметром match при задании шаблона), так и абсолютной (относительно корневого узла).
Внутри шаблона помимо XSLT элементов может располагаться и обычный текст. Текст будет вставляться в формируемый документ без изменений. В приведенном примере в качестве обычного текста используются некоторые HTML теги. Следуед отметить, что анализатор не интерпретирует эти теги, однако следит за тем, чтобы они были корректно оформлены с точки зрения синтаксиса. Поэтому одиночный тег <br> необходимо подставлять в виде <br/>, иначе анализатор выдаст сообщение об ошибке.
Если в адресную строку броузера ввести название файла ex1.xml, результатом работы встроенного XML-анализатора станет HTML-документ, содержащий три строки: имя пользователя жирным шрифтом, возраст курсивным шрифтом и подчеркнутый логин.
XPath позволяет не только описывать местонахождение узлов, но и искать узлы по совпадению значений или выполнению каких-либо условий. Для поиска можно применять так называемые фильтры, описываемые в квадратных скобках []. Например:
/users/person[@status=1]/name
обращение к узлу <name>, являющегося потомком узла <person>, у которого в свою очередь есть параметр статус, имеющий значение 1.
users/person[name='Иванов']
Обращение к узлу <person>, имеющму потомка <name> со значением Иванов.
users/person/name[.='Иванов']
Обращение к узлу <name> со значением Иванов
//name
Обращение к узлу <name> вне зависимости от адреса в иерархии. Двойной слеш // является оператором рекурсивного просмотра.
Ниже приведен пример, иллюстрирующий работу различных запросов XPath
|
Пример2 |
|
ex2.xml |
|
<?xml version="1.0" encoding="windows-1251" standalone="yes"?> <?xml-stylesheet type='text/xsl' href='ex2.xsl'?> <users> <person status="1"> Administrator <name>Иванов</name> <age>25</age> <login>guest</login> <password/> </person> </users> |
|
ex2.xsl |
|
<?xml version="1.0" encoding="windows-1251" standalone="yes"?> <xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform"> <xsl:template match="/"> <html><body> <xsl:value-of select="//name"/><br/> <xsl:value-of select="users/person[name='Иванов']"/><br/> <xsl:value-of select="users"/><br/> <xsl:value-of select="users/person[@status=1]/name"/><br/> </body></html> </xsl:template> </xsl:stylesheet> |
|
Результат |
|
Иванов Administrator Иванов 25 guest Administrator Иванов 25 guest Иванов |
Следует заметить, что в результате выполнения операции
<xsl:value-of select="users/person[name='Иванов']"/>
в качестве результата будет выведена строка
Administrator Иванов 25 guest
Элемент <xsl:value-of> выберет значение не только для узла <person>, но и для всех его потомков. Для того, чтобы выделить из выборки только значение только для узла <person>, необходимо воспользоваться встроенной в XSLT функцией text() . Работа этой функции будет продемонстрирована в приведенных ниже примерах.
В примерах, рассмотренных выше, XML документ содержал данные только об одном пользователе. XSLT шаблон был описан таким образом, что даже если бы в документе содержались данные о нескольких пользователях, при трансформации была бы обработана информация только о первом пользователе. Это связано с тем, что анализатор пытается искать в ХML документе узлы, полностью совпадающие с адресом, указанном в параметре match при описании шаблона. Шаблон (и все элементы-инструкции, входящие в него), будут выполнены столько раз, сколько совпадений со стартовым адресом шаблона найдет анализатор в теле XML документа. Поскольку корень у документа может быть только один, операции, описанные в шаблоне будут применены только один раз (в данном случае к первому найденному множеству узлов <name>, <age>, <login> итд).
Однако такая ситуация не является корректной с точки зрения списка пользователей. Для решения проблемы, предлагается описать отдельный шаблон для обработки узлов типа <person> и вызывать этот шаблон из корневого шаблона. Поскольку узлов типа <person> может быть много, соответствующий шаблон будет применен столько раз, сколько будет найдено узлов.
Теоретически, в данной ситуации можно было бы обойтись и без корневого шаблона. Однако в случае, если бы в примере было описано несколько шаблонов для различных групп узлов, сработал бы только тот шаблон, который ближе всего подходил бы к корневому узлу.
В общем случае, если в одном XSLT файле описано несколько шаблонов, выполнение будет начинаться с шаблона, наиболее близкого к корневому узлу (степень близости анализатор XML определяет самостоятельно). Для того, чтобы активировать остальные шаблоны, они должны вызываться либо из стартового шаблона, либо из шаблона, активированного стартовым (вложенность вызовов шаблонов не ограничена).
Ниже приведен пример работы двух шаблонов из одного файла:
|
Пример 3 |
|
ex3.xml |
|
<?xml version="1.0" encoding="windows-1251" standalone="yes"?> <?xml-stylesheet type='text/xsl' href='ex3.xsl'?> <users> <person status="1"> Administrator <name>Иванов</name> <age>25</age> <login>guest</login> <password/> </person> <person> Manager <name status="2">Петров</name> <age>22</age> <login>petrov</login> <password>123</password> </person> </users> |
|
ex3.xsl |
|
<?xml version="1.0" encoding="windows-1251" standalone="yes"?> <xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform"> <xsl:template match="/"> <html><body> <xsl:apply-templates select="users/person"/><br/> </body></html> </xsl:template> <xsl:template match="person"> <b><xsl:value-of select="text()"/></b><br/> <xsl:value-of select="name"/><br/> <xsl:value-of select="age"/><br/><br/> </xsl:template> </xsl:stylesheet> |
|
Результат |
|
Administrator Иванов 25 Manager Петров 22 |
Вызвать шаблон из другого шаблона позволяет элемент <xsl:apply-templates>
Функция text() отделяет значение контекстного узла (в данном случае <persons>) от значений его потомков.
Существует альтернативный способ просмотра множества узлов из корневого шаблона. Для этих целей применяется элемент <xsl:for-each>, с помощью которого можно организовать цикл для просмотра узлов. Приведенный ниже пример с точки зрения результата аналогичен предыдущему, но вместо дополнительного шаблона для вывода в нем использован элемент <xsl:for-each>.
|
Пример 4 |
|
ex4.xml |
|
<?xml version="1.0" encoding="windows-1251" standalone="yes"?> <?xml-stylesheet type='text/xsl' href='ex4.xsl'?> <users> <person status="1"> Administrator <name>Иванов</name> <age>25</age> <login>guest</login> <password/> </person> <person> Manager <name status="2">Петров</name> <age>22</age> <login>petrov</login> <password>123</password> </person> </users> |
|
ex4.xsl |
|
<?xml version="1.0" encoding="windows-1251" standalone="yes"?> <xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform"> <xsl:template match="/"> <html><body> <xsl:for-each select="users/person"> <b><xsl:value-of select="text()"/></b><br/> <xsl:value-of select="name"/><br/> <xsl:value-of select="age"/><br/><br/> </xsl:for-each> </body></html> </xsl:template> </xsl:stylesheet> |
|
Результат |
|
Administrator Иванов 25 Manager Петров 22 |
Приведенные выше примеры работали на стороне клиента. При попытке загрузить XML-документ броузер выполнял запуск XML-анализатора.
Такой подход является ненадежным, поскольку в поддержка XML реализована только в последних версиях Internet Explorer. Существует возможность трансформации XML документов средствами XSLT на стороне сервера. В PHP реализована поддержка анализатора Sablotron. Приведенный ниже пример иллюстрирует генерирование HTML документа на основе XML-документа средствами PHP.
|
Пример 5 |
|
ex5.xml |
|
<?xml version="1.0" encoding="windows-1251" standalone="yes"?> <users> <person status="1"> Administrator <name>Иванов</name> <age>25</age> <login>guest</login> <password/> </person> </users> |
|
ex5.xsl |
|
<?xml version="1.0" encoding="windows-1251" standalone="yes"?> <xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform"> <xsl:output method="html" indent="yes" encoding="Windows-1251"/> <xsl:template match="/"> <html><body> Имя: <b><xsl:value-of select="users/person/name"/></b><br/> Возраст:<i><xsl:value-of select="users/person/age"/></i><br/> Логин:<u><xsl:value-of select="users/person/login"/></u> </body></html> </xsl:template> </xsl:stylesheet> |
|
transform.php |
|
<?php
//Инициализация парсера $xh = xslt_create();
//Обработка документа $result = xslt_process($xh, "ex5.xml", "ex5.xsl");
//Вывод результата if ($result) echo $result; else echo "Ошибка!";
//Освобождение ресурсов xslt_free($xh); ?> |
|
Результат |
|
Имя: Иванов Возраст:25 Логин:guest |
В отличии от примеров 1-2, из XML документа убирается ссылка на XSLT файл с шаблонами (связь между XML и XSLT осуществляется явным образом при обращении к функции обработки документа).
В файле с XSLT появляется новый элемент <xsl:output>, задающий тип выходного документа. Данный элемент необходим для корректной работы с символами кириллицы анализатора Sablotron.