ВС для ГОС (ПИ) / Орлов, Цилькер - Организация ЭВМ (2004)
.pdf186 Глава 4. Организация шин
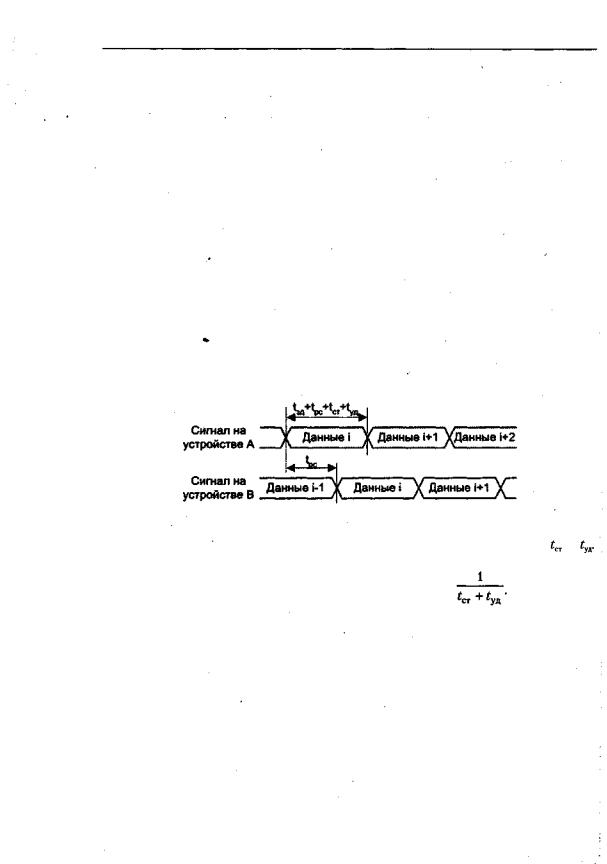
щее устройство выжидает в течение времени перекоса данных, считая от момента выставления на шину данных, так, что когда ведомый видит строб, он уже может считать данные достоверными. У ведомого дополнительно возможен перекос сигналов на внутренних трактах данных. Компенсировать его можно введением принудительной задержки, перед тем как использовать полученный сигнал стробирования. Когда ведомый возвращает данные ведущему, он должен после установки данных на шине, но до отправки сигнала подтверждения выждать время перекоса.
Учет перекоса может быть реализован как в ведущем, так и в ведомом устройстве, либо и там и там, лишь бы была обеспечена необходимая общая задержка. Например, в шине Fastbus, где количество ведущих обычно много меньше числа ведомых, ответственность за учет перекоса сигналов возлагается на ведущих, благодаря чему сокращается число устройств, которые потребуют модификации при изменении свойств шины. В рассматриваемой шине ведомый выставляет подтверждение одновременно с данными, а ведущий перед считыванием данных выжидает в течение времени перекоса. Величина компенсирующей задержки зависит от технологии шины, а также физических свойств и длины ее сигнальных линий. В свою очередь, ведомые должны самостоятельно отвечать за проблемы, связанные с их внутренними перекосами сигналов.
В обоих протоколах необходимо учитывать еще одну проблему — проблему метастабильного состояния. Суть ее поясним на примере микропроцессора, к которому подключена клавиатура. Время от времени микропроцессор считывает информацию из регистра состояния клавиатуры, который должен «решить», была ли нажата клавиша, и в зависимости от этого возвратить единицу или ноль. Проблема возникает, если принятие решения практически совпадает с моментом опроса регистра. Если это происходит несколько раньше, регистр вернет 1, а если чуть позже, то 0, но факт нажатия запоминается в соответствующем триггере регистра состояния и будет зафиксирован при следующем опросе регистра. Сложность заключается в том, что в момент переключения триггера информация на входе должна оставаться неизменной. В спецификации на реальные триггеры указывается интервал вблизи тактового импульса, в течение которого входная информация не должна изменяться. Если данные не синхронизированы с ТИ и поступают от како- го-либо независимого источника, как в примере с клавиатурой, предотвратить изменение входной информации триггера в запрещенном интервале невозможно. При нарушении данного условия триггер способен перейти в метастабильное состояние, то есть на его выходе может на неопределенное время установиться неоднозначный уровень напряжения, который сохранится, пока случайный шум не установит триггер в то или иное стабильное состояние.
Метастабильное состояние триггера опасно неопределенным поведением схем, для которых информация триггера является входной. К сожалению, многие проектировщики игнорируют упомянутую проблему, и это становится причиной случайных ошибок.
Кардинально решить означенную проблему принципиально невозможно, поэтому при проектировании необходимо проявить особую тщательность, чтобы уменьшить вероятность возникновения метастабильного состояния. Одним из методов может быть правильный выбор элементов, поскольку некоторые триггеры срабатывают быстрее, чем иные. Эффективными способами могут являться
Методы повышения эффективности шин 187
использование двухтактных триггеров и/или синхронизация триггеров тактовыми импульсами, что снижает вероятность ошибки до уровня несущественной.
В асинхронных системах имеется иная возможность: специальные схемы для обнаружения метастабильных состояний, где асинхронная система вправе просто выждать, пока состояние не станет стабильным.
Методы повышения эффективности шин
Существует несколько приемов, позволяющих повысить производительность шин. К ним, прежде всего, следует отнести пакетный режим, конвейеризацию и расщепление транзакций.
Пакетный режим пересылки информации
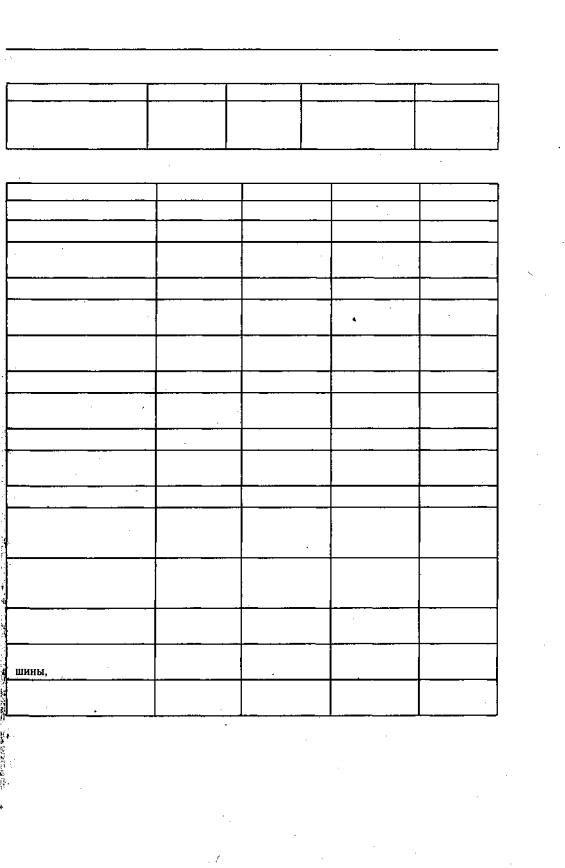
Эффективность как выделенных, так и мультиплексируемых шин может быть улучшена, если они функционируют в блочном или пакетном режиме (burst mode), когда один адресный цикл сопровождается множественными циклами данных (чтения или записи, но не чередующимися). Это означает, что пакет данных передается без указания текущего адреса внутри пакета.
При записи в память последовательные элементы блока данных заносятся в последовательные ячейки. Так как в пакетном режиме передается адрес только первой ячейки, все последующие адреса генерируются уже в самой памяти путем последовательного увеличения начального адреса. Передача на устройства ввода/ вывода или в память наподобие очереди может не сопровождаться изменением начального адреса.
Скорость передачи собственно данных в пакетном режиме увеличивается естественным образом за счет уменьшения числа передаваемых адресов. Внутри пакета очередные данные могут передаваться в каждом такте шины, длина пакета может достигать 1024 байт. Наиболее частый вариант — пакеты, состоящие из четырех байтов. Такие пакеты используются при работе с памятью в 32-разрядных ВМ, где длина ячейки памяти равна одному байту.
Рис. 4.19. Пакетный режим передачи данных
Рисунок 4.19 иллюстрирует концепцию адресации в пакетном режиме при пересылке данных. По шине адреса передается только адрес ячейки i, а в данных для ячеек i + 1, i + 2 и i + 3 указание соответствующих адресов отсутствует.
В асинхронных системах пакетный режим позволяет достичь дополнительного эффекта. Как известно, время пересылки слова включает в себя время прохождения слова от отправителя к приемнику и время, затрачиваемое на процедуру подтверждения. Необходимо также учесть внутренние задержки в ведущем и ведо-

Методы повышения эффективности шин 189
закцию и транзакцию данных. Считывание данных из памяти начинается с адресной транзакции: выставления ведущим на адресную шину адреса ячейки. С приходом адреса память приступает к относительно длительному процессу поиска и извлечения затребованных данных. По завершении чтения память становится ведущим устройством, запрашивает доступ к шине и направляет считанные данные по шине данных. Фактически от момента поступления запроса до момента формирования отклика шина остается незанятой и может быть востребована для выполнения других транзакций. В этом и состоит главная идея протокола расщепления транзакций.
Таким образом, на шине с расщеплением транзакции имеют место поток запросов и поток откликов. Часто в системах с расщеплением транзакций контроллер памяти проектируется так, чтобы обеспечить буферизацию множественных запросов.
Случай, когда затребованные данные возвращаются в той же последовательности, в которой поступали запросы, в сущности, представляет собой рассмотренную выше конвейеризацию. Шина с расщеплением транзакций зачастую может обеспечивать вариант, при котором ответы на запросы поступают в произвольной последовательности (рис. 4.21). Чтобы не спутать, какому из запросов соответствует информация на шине данных, ее необходимо снабдить признаком (тегом).
Рис. 4 . 2 1 . Расщепление транзакций
Хотя протокол с расщеплением транзакций и позволяет более эффективно использовать полосу пропускания шины по сравнению с протоколами, удерживающими шину в течение всей транзакции, он обычно вносит дополнительную задержку из-за необходимости получать два подтверждения — при запросе и при отклике. Кроме того, реализация протокола связана с дополнительными затратами, так как требует, чтобы транзакции были тегированы и отслеживались каждым устройством.
Для любой шины с расщеплением транзакций существует предельное значение числа одновременно обслуживаемых запросов.
Увеличение полосы пропускания шины
Среди приемов, способствующих расширению полосы пропускания шины, основными, пожалуй, можно считать следующие:
•отказ от мультиплексирования шин адреса и данных;
•увеличение ширины шины данных;
•повышение тактовой частоты шины;
•использование блочных транзакций.
Замена мультиплексируемой шины адреса/данных и переход к выделенным шинам адреса и данных делают возможной одновременную пересылку как адреса, так и данных, то есть позволяют реализовать более эффективные варианты тран-

190 Глава 4. Организация шин
закций. Такое решение, однако, является более дорогостоящим из-за необходимости иметь большее число сигнальных линий.
Полоса пропускания шины по своему определению непосредственно зависит от количества параллельно пересылаемой информации — практически прямо пропорциональна ширине шины данных. Несмотря на то что данный способ требует увеличения числа сигнальных линий, многие разработчики ВМ используют в своих машинах достаточно широкие шины данных. Например, в рабочей станции SPARCstation 20 ширина шины составляет 128 бит.
Наращивание тактовой частоты — еще один очевидный способ увеличения полосы пропускания, и проектировщики широко им пользуются.
О том, как на полосу пропускания шины влияют пакетные или блочные транзакции, было сказано выше: Данный способ требует некоторого усложнения аппаратуры, но одновременно позволяет сократить время обслуживания запроса.
Ускорение транзакций
Для сокращения времени транзакций проектировщики обычно прибегают к следующим приемам:
•арбитражу с перекрытием;
•арбитражу с удержанием шины;
•расщеплению транзакций.
Сущность расщепления транзакций была рассмотрена ранее. Кратко поясним остальные два метода.
Арбитраж с перекрытием (overlapped arbitration) заключается в том, что одновременно с выполнением текущей транзакции производится арбитраж следующей транзакции.
При арбитраже с удержанием шины (bus parking) ведущий может удерживать шину и выполнять множество транзакций, пока отсутствуют запросы от других потенциальных ведущих.
В современных шинах обычно сочетаются все вышеперечисленные способы ускорения транзакций.
Повышение эффективности шин с множеством ведущих
Любая система шин характеризуется пределом пропускной способности, зависящим от их ширины, скорости и протокола. Имеются также издержки, такие как арбитраж, если только он не проводится параллельно с выполнением предшествующей транзакции. Даже простой микропроцессор способен практически монополизировать производительность объединительной шины при выборке инструкций и данных, но без блочных пересылок.
При проектировании мультипроцессорных систем целесообразно рассматривать системную шину как коммуникационный тракт между разными процессорами и нескольким контроллерами ввода/вывода и снабдить каждый процессор локальной памятью для команд и большей части данных. Это существенно снижает нагрузку на системную шину. Если процессоры используют шину в первую очередь для ввода/вывода и пересылки сообщений, большая часть трафика может быть


192 Глава 4. Организация шин
При наличии в системе избыточных процессоров и шин возможен перекрестный контроль, причем программное обеспечение может производить изменения в конфигурации системы и предупреждать оператора о необходимости замены определенных блоков. Даже если шина имеет встроенные средства коррекции ошибок, желательно дополнять их некоторым дополнительным уровнем «разумности» для предотвращения такой постепенной деградации системы, компенсировать которую имеющийся механизм коррекции будет уже не в состоянии.
При разработке аппаратуры необходимо обязательно учитывать определенные требования, связанные с обеспечением отказоустойчивости. Так, если обнаружена ошибка, то для ее коррекции должна быть предусмотрена возможность повторной передачи данных. Это предполагает, что оригинальная передача не должна приводить к необратимым побочным эффектам. Например, если операция чтения с периферийного устройства вызывает стирание исходных данных или сбрасывает флаги состояния, успешное повторное чтение становится невозможным. Другой пример: работа с буферной памятью типа FIFO (First In First Out), работающей по принципу «первым прибыл, первым обслужен», где ошибочные данные внутри очереди недоступны и поэтому не могут быть откорректированы.
Чтобы учесть подобные ситуации, при разработке адресуемой памяти необходимо предусмотреть буферы, а очистка ячеек и сброс флагов должны быть не побочными эффектами, а выполняться только явно с помощью определенных команд. Память типа FIFO может быть снабжена адресуемыми буферами, предназначенными для хранения данных вплоть до завершения передачи.
Стандартизация шин
Стандартизация шин позволяет разработчикам различных устройств вычислительных машин работать независимо, а пользователям — самостоятельно сформировать нужную конфигурацию-ВМ. Появление стандартов зависит от разных обстоятельств. Часто стандарты разрабатываются специализированными организациями. Так, общепризнанными авторитетами в области стандартизации являются IEEE (Institute of Electrical and Electronics Engineers) — Институт инженеров по электротехнике и электронике) и ANSI (American National Standards Institute) — Национальный институт стандартизации США. Многие стандарты становятся итогом кооперации усилий производителей оборудования для вычислительных машин. Иногда в силу популярности конкретных машин реализованные в них решения становятся стандартами де-факто, однако успех таких стандартов во многом определяется их принятием и утверждением в IEEE и ANSI.
В табл. 4.2-4.5 приведены основные характеристики некоторых распространенных шин, как стандартных, так и претендующих на роль таковых.
Таблица 4.2. Стандартные системные шины общего применения
Характеристика |
VME |
Futurebus |
Multibus II |
Разработчик |
Motorola, Philips, |
IEEE |
Intel |
|
Mostek |
|
|
Ширина шины |
128 |
96 |
96 |

|
|
|
Стандартизация шин 193 |
Характеристика |
VME |
Futurebus |
Multibus II |
Мультиплексирование |
Нет |
Да |
Да |
адреса/данных |
|
|
|
Ч
I
Разрядность адреса, бит |
16/24/32/64 |
32 |
|
Разрядность данных, бит |
8/16/32/64 |
16/32/64/128 |
32 |
Вид пересылки |
Одиночная или |
Одиночная или |
Одиночная или |
|
групповая |
групповая |
групповая |
Количество ведущих |
Несколько |
Несколько |
Несколько |
Арбитраж |
Централизованный |
Централизованный |
Децентрализо- |
|
|
или децентрализо- |
ванный |
|
|
ванный |
|
Расщепление транзакций |
Нет |
Возможно |
Возможно |
Протокол |
Асинхронный |
Асинхронный |
Синхронный |
Тактовая частота, МГц |
Нет данных |
Нет данных |
10 |
Полоса пропускания при |
25 |
37 |
20 |
одиночной пересылке, |
|
|
|
Мбайт/с |
|
|
|
Полоса пропускания при |
28 |
95 |
40/80 |
групповой пересылке, |
|
|
|
Мбайт/с |
|
|
|
Максимальное количество |
21 |
20 |
21 |
устройств |
|
|
|
Максимальная длина |
0,5 |
0,5 |
0,5 |
шины, м |
|
|
|
Стандарт |
ШЕЕ 1014 |
IEEE 896.1 |
ANSI/IEEE 1296 |
Таблица 4.3. Системные шины высокопроизводительных серверов |
|
||
Характеристика |
Summit |
Challenge |
XDBus |
Разработчик |
HP |
SGI |
Sun |
Мультиплексирование |
Нет данных |
Нет данных |
Да |
адреса/данных |
|
|
|
Разрядность адреса, бит |
48 |
40 |
Нет данных |
Разрядность данных, бит |
128/512 |
256/1024 |
144/512 |
Вид пересылки |
Одиночная или |
Одиночная или |
Одиночная или |
|
групповая |
групповая |
групповая |
Количество ведущих |
Несколько |
Несколько |
Несколько |
Арбитраж |
Централизованный |
Централизованный |
Централизо- |
|
|
|
ванный |
Расщепление транзакций |
Есть |
Есть |
Есть |

194 |
Глава 4. Организация шин |
|
|
|
|
|
Таблица 4.3 (продолжение) |
|
|
|
|
|
|
Характеристика |
Summit |
|
Challenge |
XDBus |
||
Протокол |
Синхронный |
Синхронный |
Синхронный |
|||
Тактовая частота, МГц |
60 |
|
48 |
|
66 |
|
Полоса пропускания при |
60 |
|
48 |
|
66 |
|
одиночной пересылке, |
|
|
|
|
|
|
Мбайт/с |
|
|
|
|
|
|
Полоса пропускания при |
960 |
|
1200 |
1056 |
||
групповой пересылке, |
|
|
|
|
|
|
Мбайт/с |
|
|
|
|
|
|
Максимальная длина |
0,3 |
|
0,3 |
|
0,4 |
|
шины, м |
|
|
|
|
|
|
Стандарт |
Нет |
|
Нет |
Нет |
||
Таблица 4.4. Системные шины персональных вычислительных машин |
|
|||||
Характеристика |
NuBus |
ISA 8/16 |
|
EISA |
FSB Pentium 4 |
|
Разработчик |
Texas |
IBM |
|
AST, Compaq, |
Intel |
|
|
|
Instruments |
|
|
Epson, HP,NEC, |
|
|
|
|
|
|
Olivetti, Tandy, |
|
|
|
|
|
|
Wyse, Zenith |
|
Ширина шины |
96 |
62/98 |
|
98/100 |
Нет данных |
|
Мультиплексирование |
Да |
Нет |
|
Нет |
Нет |
|
Разрядность адреса, |
32 |
20/24 |
|
24/32 |
36 |
|
бит |
|
|
|
|
|
|
Разрядность данных, |
32 |
8/16 |
|
16/32 |
64/128 |
|
бит |
|
|
|
|
|
|
Вид пересылки |
Одиночная |
Одиночная |
Одиночная или |
Одиночная |
||
|
|
или груп- |
или груп- |
|
групповая |
или груп- |
|
|
повая |
повая |
|
|
повая |
Арбитраж |
ЦентрализоНет данных |
Централизованный Нет данных |
||||
|
|
ванный |
|
|
|
|
Расщепление |
Нет |
Нет данных |
Возможно |
Да |
||
транзакций |
|
|
|
|
|
|
Количество ведущих |
Несколько |
Один |
|
Один |
Нет данных |
|
|
|
(ограни- |
|
|
|
|
|
чено) |
|
|
|
|
|
Протокол |
Синхронный Синхронный Синхронный |
Синхронный; |
||||
Тактовая частота, МГц |
10 |
4,77/8,33 |
|
8,33 |
400(баз.100): |
|
|
|
|
|
|
|
533(баз.133); |
|
|
|
|
|
|
800(ожида- |
|
|
|
|
|
|
ется) |