

Алгоритми синхронізації часу
Якщо одна машина має приймач WWV, то завданням є підтримка синхронізації з нею всіх інших машин. Якщо приймачів WWV немає на жодній з машин, то кожна з них відраховує свій власний час, і нашим завданням буде по можливості синхронізувати їх між собою. Для проведення синхронізації було запропонована багато алгоритмів.
Всі
алгоритми мають одну базову модель
системи. Вважається, що кожна машина
має таймер, що ініціює переривання Нраз у секунду. Коли цей таймер спрацьовує,
оброблювач переривань додає одиницю
до програмних годинників, які зберігають
число тиків (переривань), починаючи з
якого-небудь моменту в минулому, про
яке була попередня домовленість. Будемо
вважати, що можемо викликати значення
цих годинС. Конкретніше, коли час
UTC дорівнюєt, значення годин машинир – Cp(t). В ідеальному світі можемо
вважати, що для всіх рі всіх
 .
Інакше кажучи,
.
Інакше кажучи,
 –точно одиниця.
–точно одиниця.
Реальні таймери не генерують переривання точно Нраз у секунду. Теоретично таймер зН=60повинен генерувати 216 000 тиків у годину. На практиці відносна помилка, припустима в сучасних мікросхемах таймерів, становить порядку 10-5. Це означає, що конкретна машина може видати значення в діапазоні від 215998 до 216002 тиків у годину.
У цих межах таймер може вважатися працездатним. Константа рвизначається виробником і відома за назвою максимальної швидкості дрейфу (maximum drift rate). Відстаючі, правильні й годинники, що поспішають, ілюструє рис. 6.4.
Якщо
два годинника ідуть від UTC у різні сторони
за час 
 після синхронізації, різниця між їхніми
показаннями може бути не більш ніж2р
–
після синхронізації, різниця між їхніми
показаннями може бути не більш ніж2р
–
 .
Якщо розроблювачі операційної системи
хочуть гарантувати, що ніяка пара годин
не зможе розійтися більш ніж на 5,
синхронізація годин повинна вироблятися
не рідше, ніж кожні5/2рс. Різні
алгоритми відрізняються точністю
визначення моменту проведення повторної
синхронізації.
.
Якщо розроблювачі операційної системи
хочуть гарантувати, що ніяка пара годин
не зможе розійтися більш ніж на 5,
синхронізація годин повинна вироблятися
не рідше, ніж кожні5/2рс. Різні
алгоритми відрізняються точністю
визначення моменту проведення повторної
синхронізації.
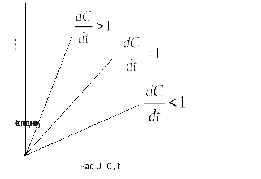
Рис. 6.4 Співвідношення між часом по годинниках і часом UTC
Використання синхронізованих годин
За минулі кілька років стали легкодоступними необхідне обладнання й програмне забезпечення, призначене для синхронізації годин у глобальному масштабі (тобто у всьому Інтернеті). Завдяки цим новим технологіям можна синхронізувати мільйони годинників з точністю до декількох мілісекунд по UTC. Стали з'являтися нові алгоритми, що використовують ці синхронізовані годинники. Один із прикладів стосується того, як домогтися доставки серверу не більше одного повідомлення, навіть у випадку збоїв. Традиційний підхід полягає в тому, що кожному повідомленню приписується унікальний номер повідомлення, а кожен сервер зберігає всі номери повідомлень, які він прийняв, щоб можна було відрізнити нове повідомлення від повторної посилки. Проблема цього алгоритму полягає в тому, що при збої і перезавантаженні сервера він губить цю таблицю номерів повідомлень. Неясно також, скільки часу зберігати ці номери повідомлень.
З використанням часу традиційний алгоритм модифікується в такий спосіб. Отже, кожне повідомлення має ідентифікатор зв'язку (обраний відправником) і мітку часу. Для кожного з'єднання сервер заносить у таблицю останню отриману мітку часу. Якщо яке-небудь вхідне повідомлення має оцінку часу меншу, чим оцінка, збережена в таблиці для цього з'єднання, повідомлення вважається дублікатом і не розглядається.
Щоб можна було видалити стару мітку часу, кожен сервер постійно підтримує глобальну змінну G, обумовлену в такий спосіб:

 ,
,
де
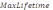
 – максимальний час життя повідомлення,
a
– максимальний час життя повідомлення,
a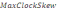
 вказує на те, як далеко від часу UTC можуть
відрізнятися годинники.
вказує на те, як далеко від часу UTC можуть
відрізнятися годинники.
Будь-яка мітка часу старше Gможе бути легко вилучена з таблиці, оскільки всіх повідомлень старшеGуже пройшли. Якщо вхідне повідомлення має невідомий ідентифікатор зв'язку, воно буде прийнято, якщо його мітка часу більш рання, чимG, і відкинуто, якщо вона більш пізня, чимG, оскільки всяке більш пізніше повідомлення – це, безсумнівно, дублікат. У дійсностіG– це сума номерів всіх старих повідомлень.
У випадку збою й наступного перезавантаження сервера він завантажує значення Gз файлу, збереженого на диску, і збільшує його в ході періоду відновлення. Будь-яке вхідне повідомлення з оцінкою часу старшеG– це дублікат. У результаті кожне повідомлення, що могло бути прийняте до збою, тепер відкидається. Деякі нові повідомлення можуть бути відкинуті помилково, але при дотриманні всіх умов алгоритм підтримує семантику «не більше одного повідомлення».