Раздел 1. Формальные грамматики
Лекция 2.
Тема лекции. Способы определения языковых процессоров. Формальные грамматики. Классификация грамматик.
Язык, порождаемый грамматикой. Левосторонний и правосторонний выводы. Дерево вывода.
-
Формальные грамматики.
В предыдущем разделе был определен язык, как множество строк, содержащих символы некоторого алфавита. Для практического использования такого языка кроме символов алфавита необходимо знать синтаксис и семантику языка. Под синтаксисом понимают синтаксические определения, которые точно устанавливают какие строки имеют смысл в данном языке. Эти определения дают правила построения допустимых в языке конструкций слов, групп слов и предложений, образуемых из символов алфавита. Под семантикой языка понимают правила интерпретации синтаксических определений, задающие смысл допустимым конструкциям языка. Для описания синтаксиса языков программирования используются формулы Бэкуса - Наура и синтаксические диаграммы. Универсальным способом описания являются формальные грамматики. Грамматика представляет собой математическую систему, порождающую язык. Строки языка строятся способом, точно определенным правилами грамматики.
Формальная
грамматика
![]() - это четверка
- это четверка
![]()
где
![]() - конечное множество нетерминальных
символов (нетерминалов);
- конечное множество нетерминальных
символов (нетерминалов);
![]() - конечное, не пересекающееся с
- конечное, не пересекающееся с
![]() ,
множество терминальных
символов (терминалов),
,
множество терминальных
символов (терминалов),
![]() ;
;
![]() - конечное множество правил-продукций
вида
- конечное множество правил-продукций
вида
![]() ,
где
,
где
![]() - строка левой части продукции
- строка левой части продукции
![]() ,
,
![]() - строка правой части продукции
- строка правой части продукции
![]() ,
другими словами
,
другими словами
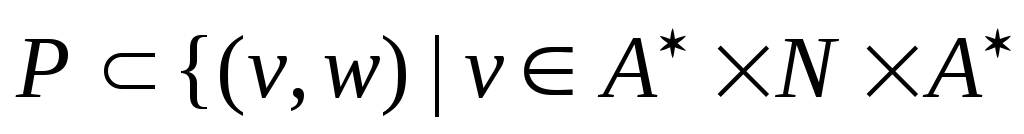 ,
,![]() ,
где
,
где
![]() ;
;
![]() - начальный символ грамматики
- начальный символ грамматики
![]() .
Символ
.
Символ
![]() в продукции
в продукции
![]() означает возможность замены строки
означает возможность замены строки
![]() на строку
на строку
![]() .
В качестве примера рассмотрим следующую
грамматику
.
В качестве примера рассмотрим следующую
грамматику
![]() ,
где множество
,
где множество
![]() содержит следующие продукции
содержит следующие продукции
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
Для сокращения
записи множества продукций сгруппируем
продукции, имеющие совпадающие левые
части. Правые части этих продукций будем
записывать в одну строку, разделяя их
символом "|". При такой форме записи
множество продукций грамматики
![]() будет выглядеть следующим образом
будет выглядеть следующим образом
![]()
![]()
Грамматика
рекурсивным образом определяет
порождаемый язык, который содержит
множество выводимых из начального
символа строк. Определим формально
выводимую строку для грамматики
![]() .
Строка
.
Строка
![]() называется выводимой
строкой
грамматики
называется выводимой
строкой
грамматики
![]() ,
если
,
если
![]() продукция из множества
продукция из множества
![]() и
и
![]() строка терминальных и нетерминальных
символов длиной 1
[2]. Выводимая строка получается путем
замены строки
строка терминальных и нетерминальных
символов длиной 1
[2]. Выводимая строка получается путем
замены строки
![]() на строку
на строку
![]() в строке
в строке
![]() .
Такое преобразование строки записывают
в виде
.
Такое преобразование строки записывают
в виде
![]()
![]()
![]()
Преобразование
![]() можно рассматривать как отношение на
множестве
можно рассматривать как отношение на
множестве
![]() [1,4]. Это отношение является рефлексивным,
так как допустима замена строки
[1,4]. Это отношение является рефлексивным,
так как допустима замена строки
![]() на самое себя. Однако оно определено не
для всех элементов
на самое себя. Однако оно определено не
для всех элементов
![]() , нетранзитивно
и несимметрично.
, нетранзитивно
и несимметрично.
Отношение
![]() на множестве
на множестве
![]() задается как
задается как
![]() ,
если существует последовательность
,
если существует последовательность
![]() для
для
![]() и
и
![]() .
В этом случае говорят, что строка
.
В этом случае говорят, что строка
![]() выводится из строки
выводится из строки
![]() за один более шагов. Отношение
за один более шагов. Отношение
![]() рефлексивно
и транзитивно, но несимметрично. Если
строка
рефлексивно
и транзитивно, но несимметрично. Если
строка
![]() является выводимой из начального символа
строкой (
является выводимой из начального символа
строкой (![]() ),
то ее называют сентенциальной
формой. Не
содержащая нетерминальных символов
сентенциальная форма называется
предложением
(или сентенцией).
Множество всех предложений грамматики
),
то ее называют сентенциальной
формой. Не
содержащая нетерминальных символов
сентенциальная форма называется
предложением
(или сентенцией).
Множество всех предложений грамматики
![]() называют языком, порождаемым этой
грамматикой и обозначают
называют языком, порождаемым этой
грамматикой и обозначают
![]() .
Таким образом
.
Таким образом
![]()
Может так случиться,
что две грамматики
![]() и
и
![]() порождают один и тот же язык
порождают один и тот же язык
![]() .
О таких грамматиках говорят, что они
эквивалентны.
В дальнейшем в тех примерах, где ясно о
какой грамматике идет речь , в обозначениях
вида
.
О таких грамматиках говорят, что они
эквивалентны.
В дальнейшем в тех примерах, где ясно о
какой грамматике идет речь , в обозначениях
вида
![]() и
и
![]() символ грамматики
символ грамматики
![]() будем опускать.
будем опускать.
Рассмотрим примеры
предложений нескольких языков. Для
приведенной выше грамматики
![]() в язык включены следующие предложения,
представляющие собой восьмеричные
числа.
в язык включены следующие предложения,
представляющие собой восьмеричные
числа.
2 вывод ![]()
23 вывод ![]() (правило
(правило
![]() )
)
![]() (правило
(правило
![]() )
)
![]() (правило
(правило
![]() )
)
![]() (правило
(правило
![]() )
)
637 вывод ![]()
В предложенной
грамматике левые части всех продукций
содержали только по одному символу. В
следующей грамматике
![]() продукции в левой части содержат строки,
состоящие более чем из одного символа.
продукции в левой части содержат строки,
состоящие более чем из одного символа.
![]()
![]()
![]()
В грамматике
![]() из начального символа можно вывести
строку вида
из начального символа можно вывести
строку вида
![]() .
Например, строку
.
Например, строку
![]()
![]() (правило
(правило
![]() )
)
![]() (правило
(правило
![]() )
)
![]() (правило
(правило
![]() )
)
![]() (правило
(правило
![]() )
)
![]() (правило
(правило
![]() )
)
![]() (правило
(правило
![]() )
)
2.2. Классификация грамматик.
По виду порождающих
правил, а точнее строк
![]() и
и
![]() в правой и левой частях продукций
в правой и левой частях продукций
![]() множества
множества
![]() грамматики
грамматики
![]() последняя может относиться к одному из
четырех типов грамматик.
последняя может относиться к одному из
четырех типов грамматик.
Грамматика
![]() называется :
называется :
-
праволинейной или автоматной (тип 3), если
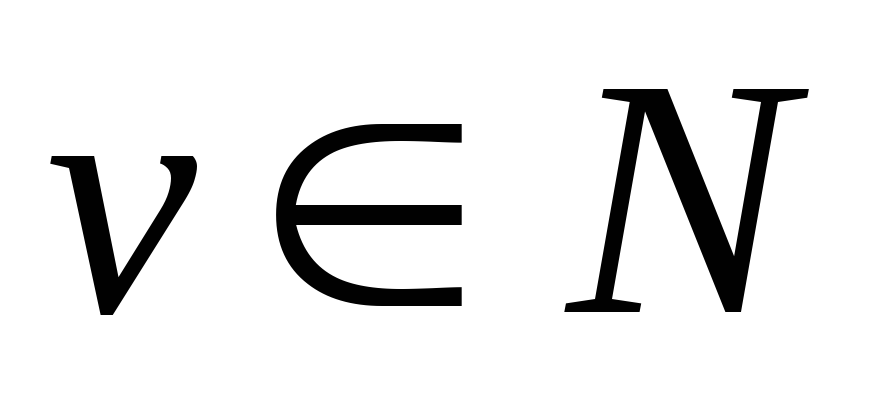 ,
,
 или
или
 ,
т.е. каждое правило из множества продукций
,
т.е. каждое правило из множества продукций
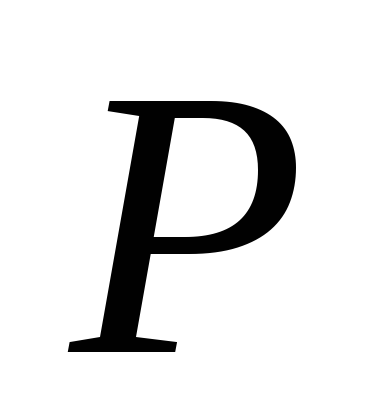 имеют вид
имеют вид
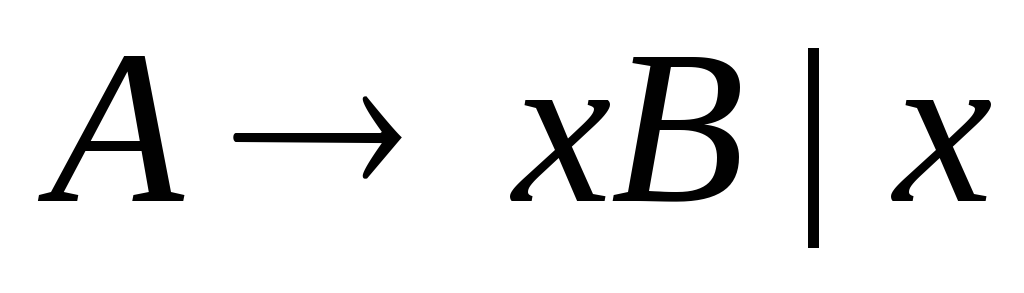 ,
где
,
где
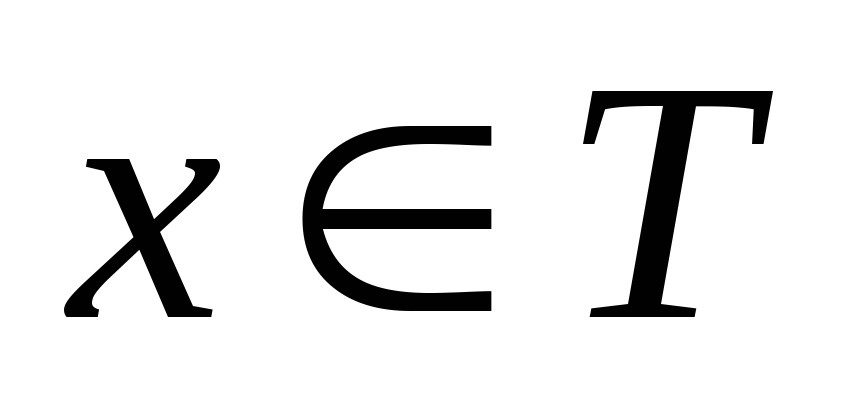 и
и
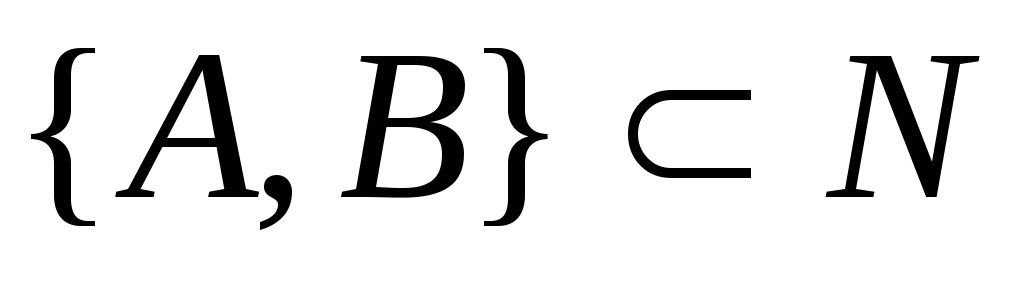
-
контекстно-свободной (тип 2), если
 ,
,
 ;
; -
контекстно-зависимой неукорачивающей (тип 1), если
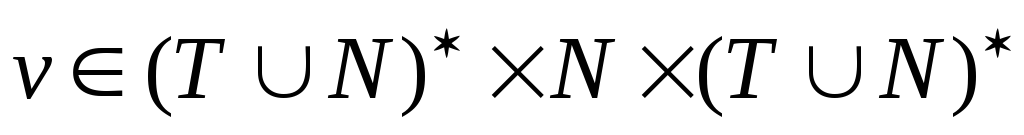 ,
,
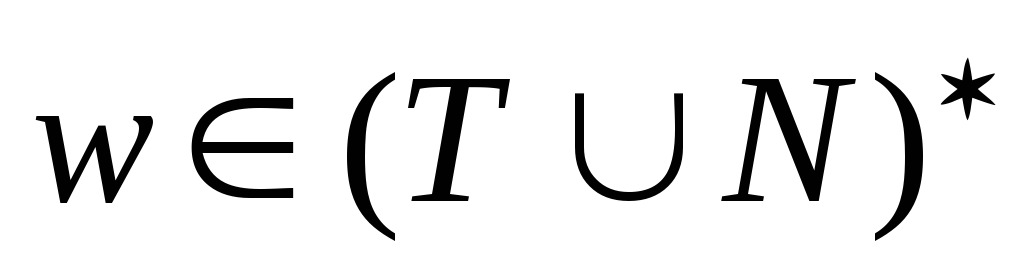 и длина строки
и длина строки
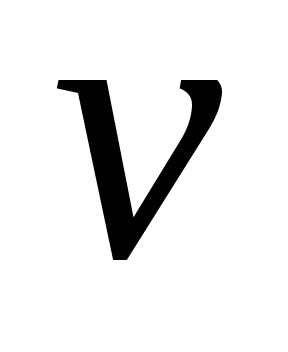 не превышает длину строки
не превышает длину строки

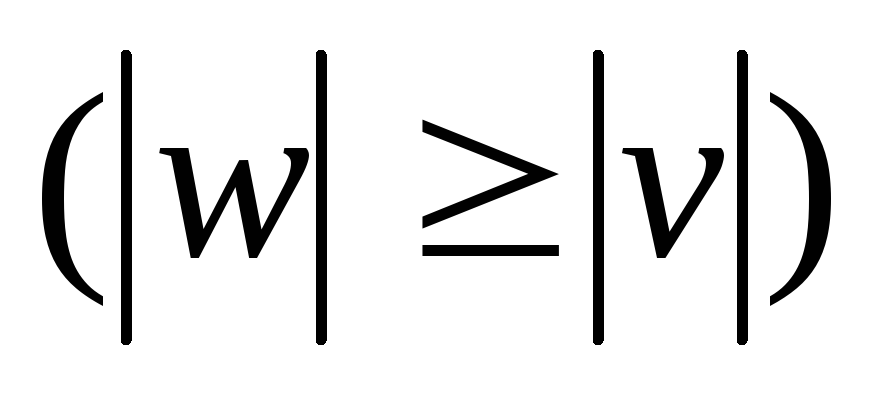 ;
; -
контекстно-зависимой без ограничений (тип 0), если
 ,
,
 .
.
Язык, порождаемый
грамматикой типа
![]() ,
называется языком типа
,
называется языком типа
![]() .
Таким образом язык
.
Таким образом язык
![]() ,
порождаемый приведенной выше грамматикой
,
порождаемый приведенной выше грамматикой
![]() ,
является контекстно-свободным, а язык
,
является контекстно-свободным, а язык
![]() -
контекстно-зависимым языком типа 1.
Рассмотрим в качестве примера еще две
грамматики, порождающие идентификаторы
языка программирования, состоящие из
первой буквы, за которой следует целое
число. Грамматика
-
контекстно-зависимым языком типа 1.
Рассмотрим в качестве примера еще две
грамматики, порождающие идентификаторы
языка программирования, состоящие из
первой буквы, за которой следует целое
число. Грамматика
![]() является
праволинейной и содержит следующие
продукции:
является
праволинейной и содержит следующие
продукции:
![]()
![]()
![]()
Следующая грамматика определяет то же самое множество идентификаторов, но представляет собой контекстно-свободную грамматику с множеством продукций:
![]()
![]()
![]()
В эту грамматику
дополнительно включен нетерминальный
символ
![]() для обозначения цифр. Язык, порождаемый
обоими грамматиками представляет собой
множество предложений
для обозначения цифр. Язык, порождаемый
обоими грамматиками представляет собой
множество предложений
![]() ,
где
,
где
![]() .
.
Определенные выше
четыре типа языков и грамматик называют
иерархией Хомского. В приведенном
определении контекстно-свободной
грамматики недопустимыми являются так
называемые
![]() -
продукции, продукции вида
-
продукции, продукции вида
![]() .
Однако многие авторы включают такие
продукции в число допустимых продукций
контекстно-свободных грамматик, а
контекстно-свободные грамматики без
.
Однако многие авторы включают такие
продукции в число допустимых продукций
контекстно-свободных грамматик, а
контекстно-свободные грамматики без
![]() -
продукций называют
-
продукций называют
![]() -свободными
грамматиками[2]. Конечно при разработке
трансляторов более удобно использовать
именно такие грамматики без
-свободными
грамматиками[2]. Конечно при разработке
трансляторов более удобно использовать
именно такие грамматики без
![]() -
продукций. Но и при наличии в грамматике
-
продукций. Но и при наличии в грамматике
![]() -
продукции ситуация не является
безнадежной, поскольку доказано, что
для любого контекстно-свободного языка
-
продукции ситуация не является
безнадежной, поскольку доказано, что
для любого контекстно-свободного языка
![]() существует
существует
![]() -
свободная контекстно-свободная грамматика
-
свободная контекстно-свободная грамматика
![]() ,
такая, что
,
такая, что
![]() .
Построение такой грамматики несложно
[2].
.
Построение такой грамматики несложно
[2].
С точки зрения приложений к языкам программирования наиболее подходящими являются контекстно-свободные грамматики. Это связано с тем, что с помощью этих грамматик удается достаточно полно описать синтаксис существующих языков программирования. С точки зрения трансляции наиболее важным вопросом, на который необходимо иметь ответ, является вопрос о наличии нескольких выводов из начального символа одного и того же предложения языка.
Для представления
вывода
![]() ,
где
,
где
![]() обычно используется дерево вывода.
Вершины дерева помечены символами из
множества
обычно используется дерево вывода.
Вершины дерева помечены символами из
множества
![]() .
Корнем дерева является вершина, помеченная
начальным символом
.
Корнем дерева является вершина, помеченная
начальным символом
![]() ,
а листьями вершины с терминальными
символами. Все промежуточные вершины
дерева помечены нетерминалами множества
,
а листьями вершины с терминальными
символами. Все промежуточные вершины
дерева помечены нетерминалами множества
![]() .
.
Рассмотрим
грамматику
![]() ,
которая описывает множество арифметических
выражений над переменными
,
которая описывает множество арифметических
выражений над переменными
![]() и
и
![]() .
Множество правил P включает в себя
следующие продукции:
.
Множество правил P включает в себя
следующие продукции:
![]()
![]()
![]()
Поскольку одна и
та же строка может получена в результате
нескольких выводов, их подразделяют на
два типа левосторонние и правосторонние.
Схема вывода предложения
![]() называется левосторонней (правосторонней),
если подстановка очередного правила
осуществляется всегда на место самой
левой (правой) сентенциальной формы.
Два вывода строки
называется левосторонней (правосторонней),
если подстановка очередного правила
осуществляется всегда на место самой
левой (правой) сентенциальной формы.
Два вывода строки
![]() выглядят следующим образом
выглядят следующим образом
левосторонний
![]()
![]()
![]()
![]()
правосторонний
![]()
![]()
![]()
![]()

Построим дерево
для левостороннего вывода строки (рис.
1.5). Легко убедиться, что дерево для
правостороннего вывода будет точно
таким же. Контекстно-свободную грамматику,
в которой все возможные схемы выводов
строки
![]() соответствуют одному и тому же дереву
вывода будем называть однозначной.
Примером неоднозначной грамматики
может служить грамматика
соответствуют одному и тому же дереву
вывода будем называть однозначной.
Примером неоднозначной грамматики
может служить грамматика
![]() с продукциями
с продукциями
![]()
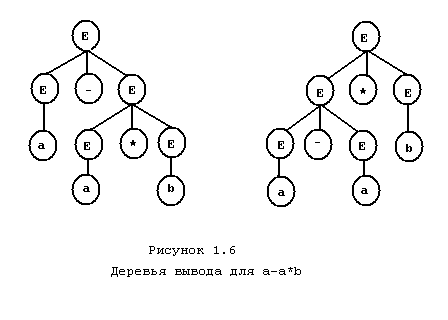
Для выражения
![]() можно построить два разных дерева вывода
(рис. 1.6). В дальнейшем нас будут интересовать
в основном однозначные грамматики.
можно построить два разных дерева вывода
(рис. 1.6). В дальнейшем нас будут интересовать
в основном однозначные грамматики.