

Lectures / 23
.pdfАрхитектура MISD
Команды Поток A
|
Команды |
|
|
Поток B |
Команды |
|
|
Поток C |
Проц. |
|
|
A |
|
|
Входные данные |
Проц. |
Выходные данные |
B |
|
|
|
Проц. |
|
|
C |
|
ÎНет коммерческих реализаций

Архитектура SIMD
Поток команд
Входные
данные поток A
Входные
данные поток B
Входные
данные поток C
Проц. 

A
Проц.
B
Проц.
С
Выходные
данные поток A
Выходные
данные поток B
Выходные
данные поток C
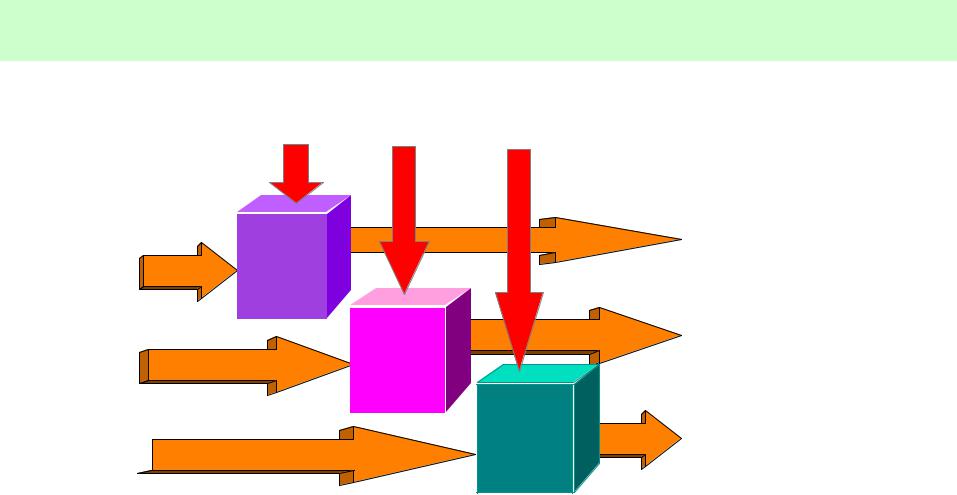
Архитектура MIMD
Входные
данные поток A
Входные
данные поток B
Входные 
данные поток C
Команды |
Команды |
Команды |
поток A |
поток B |
поток C |
Проц. 
A
Проц.
B
Проц.
С
Выходные
данные поток A
Выходные
данные поток B
Выходные
данные поток C
•Общая память (сильно связанные) MIMD
•Распределенная память (слабо связанные) MIMD

Пример SIMD: Векторные компьютеры
•Обрабатывают более одного элемента данных одновременно.
•Пусть A[I]=Z+B[I]× C[I] для I =1... N
•“Обычный” компьютер:
Шаг 1 |
A[1] =Z+B[1] × C[1] |
|
Шаг 2 |
A [2] =Z+B[2] × C[2] |
|
… |
|
|
Шаг N |
A [2] =Z+B[2] × C[2] |
|
• Векторный компьютер с вектором длины L: |
||
Шаг 1 |
A[1..L] |
=Z+B[1..L]× C[1..L] |
Шаг 2 |
A[L+1..2L] |
=Z+B[L+1..2L] × C[L+1..2L] |
Шаг 3 |
A[2L+1..3L] |
=Z+B[2L+1..3L] × C[2L+1..3L] |
…
Шаг M A[(M-1)L..N]=Z+B[(M-1)L..3L] × C[(M-1)..3L]
где M=N/L

SIMD: Компьютеры VLIW и EPIC
VLIW (Very Long Instruction Word)
Вычислительные системы с командными словами сверхбольшой длины
EPIC (Explicitly Parallel Instruction Computing)
Вычисления с явным параллелизмом команд

Формат команды в IA-64 (Itanium)
127  Связка (bundle)
Связка (bundle)  0
0
Команда 2 Команда 1 Команда 0 Шаблон |
||
I2 |
I1 |
I0 |
13 |
6 |
|
7 |
|
7 |
|
|
|
|
|
|
|
7 |
|
|
||||||
|
|
|
|
|
|
|
|
|
|
|
КОП |
Предикат |
|
РОН |
|
РОН |
|
РОН |
|||
|
операнда1 |
операнда2 |
результата |
|||||||
39 |
|
|
Команда |
|
|
|
|
|
|
0 |
|
|
|
|
|
|
|
|
|||
Варианты связки из трех команд:
I0 |
|| I1 |
|| I2 |
|
I0 |
& I1 |
|| I2 |
|
I0 |
|| I1 |
& I2 |
|
I0 |
& I1 |
& I2 |
|
все команды исполняются параллельно сначала I0, затем параллельно I1 и I2 параллельно I0 и I1, после них - I2 команды исполняются в порядке I0, I1, I2
Пример выполнения с предикацией
Оператор if
if (R1 == R2)
R3 = R4 + R5;
else
R6 = R4 - R5;
Код на ассемблере
CMP |
R1,R2 |
BNE |
L1 |
MOV R3,R4 |
|
ADD |
R3,R5 |
JMP |
L2 |
L1: MOV R6,R4 |
|
SUB |
R6,R5 |
L2: |
|
Выполнение с предикацией
CMPEQ |
P2,P1 = R1,R2;; |
<P1> ADD |
R3,R4,R5 |
<P2> SUB |
R6,R4,R5 ;; |
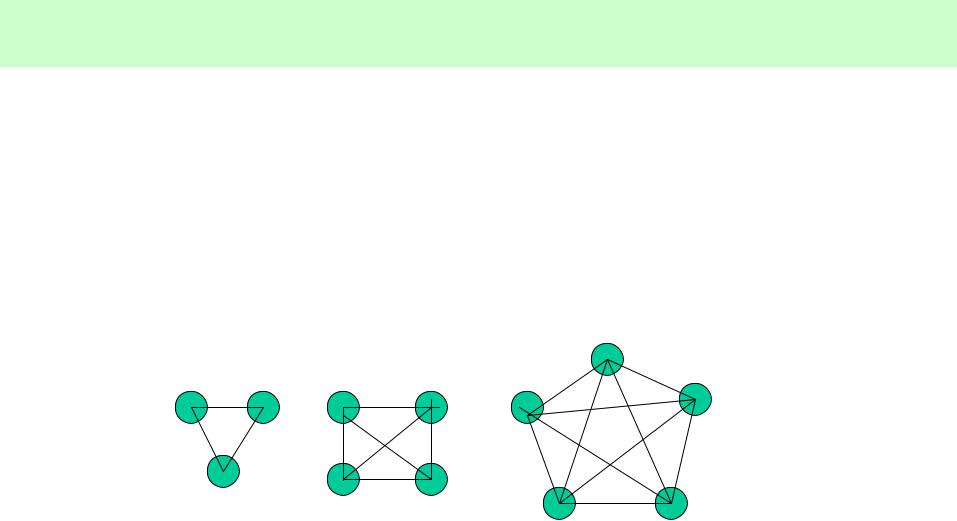
Полный граф
•Каждый узел соединен со всеми узлами
•N x (N-1)/2 соединений

Линейка и кольцо
•Простейшее соединение
•Отсутствует прямая связь между узлами
•Сложная маршрутизация
1 |
2 |
3 |
4 |
5 |
6 |
7 |

Звезда