

Лекция 14. Представление структур данных в памяти ЭВМ.
План лекции
Cпособы адресации элементов структуры.
Линейный список.
Последовательное распределение памяти.
Отображение двоичн дерево в памяти ЭВМ
Метод левосписковых структур.
Связанное распределение памяти.
Примеры связанных списков.
Инвертированный список.
Индексирование файла по однму или нескольким полям. Преимущества и недостатки индексирования.
Вычисление адреса по значениям ключей. Хеширование.
Мы познакомились с несколькими разновидностями модели данных (реляционными, иерархическими и сетевыми). Необходимо знать способы отображения этих структур в памяти ЭВМ.
Основное различие форм представления данных в памяти ЭВМ определяется способом адресации элементов структуры – по местуили посодержимому.
В первом случае указываются адреса данных, определяющие место расположения данных в памяти машины.
Во втором случае размещение данных и их выборка осуществляются по известному значению ключа, т.е. определяются содержимым самих данных.
Наиболее постой формой хранения данных является одномерный линейный список.
Линейный список – это множество объектов (узлов), которые можно представить в виде последовательности объектов (узлов):
Х[1], Х[2], … ,Х[n].
Х[i-1] – предшествует узлу Х[i]
Х[i+1] – следует за Х[i],
структурные свойства котороой связаны с линейным (одномерным) относительным расположением узлов.
Компоненты этой последовательности идентифицируются порядковым номером индекса i, 1 <i<n.
Одномерный линейный список иногда называется вектором данных.
Отображение моделей данных
Проблема отображения моделей данных, т.е. некоторых логических структур в памяти ЭВМ связана с понятием адресной функции.
При реализации адресной функции, используется два основных способа:
Последовательное распределение памяти;
Связанное распределение памяти.
Последовательноераспределение памяти, т. е. в виде линейного списка.
Пример. Необходимо отобразить двоичное дерево в памяти ЭВМ с помощью линейного списка (рис.1).

Рис.1. Иерархическая модель
Содержимое линейного списка:
У1 У2 У3 У4… У15.
Определение адреса (адресной функции):
α(1)=β;
α(2)=β+m;
α(3)=β+2m;
α(i)=β+(i-1)m;
α(15)=β+14m;
β– базовый адрес;
m– длина записи (фиксированная длина).
Перемещение от родителя к потомку и обратно:
От узла с номером Kможно перейти к его потомкам. Для этого надо удвоитьKи прибавить единицу.
От узла Kможно перейти к его родителю. Для этого необходимо разделитьKна 2 и отбросить дробную часть.
Аналогичным способом можно проектировать структуру троичного регулярного дерева.
Пример троичного регулярного дерева (рис.2).
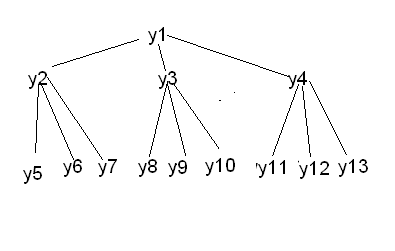
Рис.2. Троичноерегулярное дерево
От узла Kможно перейти к родителям, разделив индекс на 3 и округлить результат до ближайшего целого числа.
Метод левосписковых структур
Необходимо отобразить иерархическкую структуру (не обязательно регулярную) в памяти ЭВМ с помощью линейного списка(рис.3).

Рис.3. Левосписковая структура
Линейный список:
|
а |
б1 |
в1 |
г1 |
г2 |
г3 |
в2 |
г4 |
б2 |
в3 |
г5 |
г6 |
в4 |
г7 |
б3 |
в5 |
г8 |
Метод размещает последовательность узлов в списке, при обходе исходной древовидной структуры сверху-вниз и слева-направо:
идем от корневого узла вниз, до конца левой ветви,
т. е. до г1;
поднимаемся вверх на один шаг, и опускаемся вниз, отмечаем г2;
поднимаемся вверх на один шаг, и, снова, опускаемся вниз, отмечаем г3;
поднимаемся на два шага до б1 и, вновь, опускаемся вниз, отмечаем в2, г4 и т. д.
Этот метод применим для любой древовидной структуры. При размещении древовидной последовательности в памяти, можно использовать специальный разделитель в виде скобок:
а(б1(в1(г1 г2 г3)в2(г4))б2(в3(г5 г6)в4(г7))б3(в5(г8)))
Открывающая скобка – движение вниз по модели, закрывающая – вверх.
Скобка – переход с уровня на уровень.
Связанное распределение памяти (связанный список)
Отношения следования и предшествования элементов задаются с помощью указателей.Значение адресной функции можно получить только после просмотра указателей. Это удобно, так как список легко модифицируется. Для хранения указателей требуется дополнительная память. Элементы списка необязательно хранятся в последних ячейках памяти.
Различают однонаправленные и двунаправленные связанные списки.
Однонаправленный список- каждый узел содержит адрес следующего узла.

Рис.4. Пример однонаправленного связанногосписка
Двунаправленный связанный список- каждый узел содержит адреса следующего и предыдущего узлов.

Рис.5. Пример двунаправленного связанного списка

Рис.6. Пример линейного списка с пропусками
Для упрощения доступа к узлам применяется линейный список с пропусками, в котором в начале осуществляется доступ по обратным указателям к группе, в которой находится требуемый элемент. А затем по прямым указателям перебираются узлы группы, пока не будет найден требуемый узел.

Циклический список с указателями на голову списка
Голова списка

Рис.7. Пример циклического списка
Голова
списка хранится в специальной ячейке
памяти по адресу
![]() .
В этой ячейке можно хранить служебную
информацию, содержащую идентификатор
списка, количество узлов в списке и т.п.
.
В этой ячейке можно хранить служебную
информацию, содержащую идентификатор
списка, количество узлов в списке и т.п.
В голове списка содержится указатель на первый узел списка . Наличие циклов, т.е. обратных связей позволяет получить доступ к любому узлу отправляясь от любого заданного узла.