

13.Архитектура многопользовательских субд.Централизованная архитектура
Мэйнфрейм:

При подобной архитектуре и СУБД, и сами данные размещаются на центральном мини-компьютере или мэйнфрейме вместе с приложением, принимающим входную информацию с пользовательского терминала и отображающим на нем же данные.
Архитектура файл/сервер
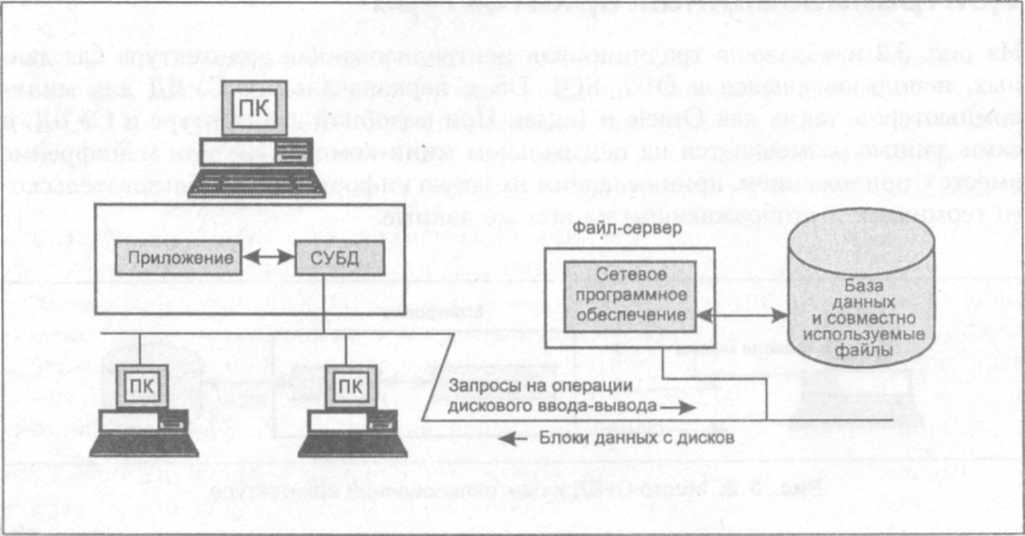 При
такой архитектуре приложение, выполняемое
на ПК, может получить «прозрачный»
доступ к файловому серверу, на котором
хранятся совместно используемые файлы.
При
такой архитектуре приложение, выполняемое
на ПК, может получить «прозрачный»
доступ к файловому серверу, на котором
хранятся совместно используемые файлы.
Когда приложению, работающему на ПК, требуется получить данные из такого файла, сетевое программное обеспечение автоматически считывает требуемый блок данных с сервера.
Достоинства архитектуры - при выполнении обычных запросов эта архитектура обеспечивает высокую производительность, поскольку в распоряжении каждой копии СУБД находятся все ресурсы ПК
Недостатки – сложные запросы требуют последовательного просмотра БД, СУБД постоянно запрашивает новые записи из БД, которая физически расположена на сервере. В результате СУБД запросит и получит по сети все записи. При этом создается слишком большая нагрузка на сеть и уменьшается производительность работы.
Архитектура клиент/сервер

При такой архитектуре ПК объединены в локальную сеть, в которой имеется сервер баз данных, содержащий общие базы данных.
Функции СУБД разделены на две части:
-пользовательские программы, (приложения для формирования интерактивных запросов; генераторы отчетов) выполняются на клиентском компьютере;
-ядро базы данных, которое хранит данные и управляет ими, работает на сервере.
-В этой архитектуре SQL стал стандартным языком, обеспечивающим взаимодействие между пользовательскими программами и ядром базы данных.
-В архитектуре клиент/сервер запрос передается по сети на сервер баз данных в виде SQL-запроса.
-Ядро базы данных на сервере обрабатывает запрос и просматривает базу данных, которая также расположена на сервере.
Трехуровневая архитектура Интернета

Интерфейсом пользователя является Web-браузер, который выполняется на ПК.
Браузер взаимодействует с Web-сервером, уровень которого можно оценить как прикладной.
Если пользователь запрашивает нечто большее, чем просто Web-страницы, Web-сервер переадресует запрос серверу приложений, чья роль заключается в анализе запроса и переадресации его к корпоративной БД.
Корпоративная БД определена как информационный уровень.
В этой архитектуре SQL закрепился как стандартное средство взаимодействия между вторым и третьим уровнями.
14. Необходимость в полноценном использовании информационного потенциала предприятия, то есть накопленных данных, а также практические проблемы, связанные с производительностью OLTP-систем(On-Line Transaction Processing), породили концепцию хранилища данных (data warehouse).
Тесты производительности и отчаянное соперничество между ведущими СУБД переместились в область простых транзакций, таких как добавление новых заказов в базу данных или определение баланса счетов клиента.Рабочая нагрузка OLTP-систем состоит из коротких транзакций, выполняемых с большой частотой, причем время реакции системы должно быть минимальным. В противоположность этому запросы, связанные с принятием решений, могут требовать сканирования огромных таблиц и выполняться минутами или даже часами. Если экономист-аналитик попытается выполнить подобный запрос во время пика деловых транзакций, это может вызвать серьезное снижение производительности всей системы, что для оперативной обработки транзакций просто недопустимо.

Деловые данные извлекаются из OLTP-систем предприятия, форматируются, проверяются и затем помещаются в отдельную базу данных, предназначенную исключительно для делового анализа («хранилище»).
Извлечение и форматирование данных можно выполнять периодически, в пакетном режиме, во время наименьшей загрузки системы.
В идеале из транзакционных баз данных извлекаются только новые и измененные данные, что позволяет сократить общее количество данных, обрабатываемых во время ежемесячной, еженедельной или ежедневной операции обновления хранилища.
Хранилищу и не требуют участия систем оперативной обработки транзакций
Благодаря своей гибкости в обработке запросов реляционные СУБД идеально подходили для организации хранилищ данных.
Разработаны специальные программные средства для извлечения данных из OLTP-систем, их преобразования, загрузки в хранилище и последующего выполнения запросов к хранилищу
Для удовлетворения специфических потребностей приложений, работающих с хранилищами данных и часто называемых приложениями для оперативной аналитической обработки данных (OLAP — Online Analytical Processing), стали появляться специализированные СУБД.
Их производительность оптимизирована для выполнения сложных запросов, связанных только с выборкой данных.
Они поддерживают расширенный набор статистических функций и имеют встроенные средства для других распространенных типов анализа данных, например хронологического.