

2 Методика моделювання потоків даних
Суть моделювання потоків даних при проектуванні складних інформаційно-керуючих систем (ІКС) – це створення так званих діаграм потоків даних. Нижче будемо використовувати загально визнане скорочення DFD, яке походить від англійського терміна Data Flow Diagram. Ці схеми відображають шляхи проходження та перетворення інформації в системі.
DFD є простим, але надійним графічним засобом, який досить легко адаптується до потреб проектувальників та користувачів ІКС. DFD відображає ІКС з точки зору переміщення даних в системі. При цьому є можливість деталізації відображення за рахунок розкриття особливостей системи на декількох рівнях ієрархії. Набір діаграм супроводжується більш детальною інформацією, яка комплектується у вигляді спеціальної документації. Ієрархічний набір діаграм разом з комплектом документів зветься моделлю потоків даних.
Методика моделювання потоків даних, яка викладена далі, забезпечує досить простий спосіб моделювання функціональних ІКС як на стадії обстеження та аналізу вимог до системи, так і на початкових стадіях розробки нових проектних рішень.
В межах сучасних методологій структурного системного аналізу та проектування ІКС методики моделювання потоків даних використовуються для забезпечення взаємопорозуміння з користувачами при ідентифікації вимог до функціонального наповнення ІКС, як інструмент аналізу в межах концепції проектування “зверху - вниз”.
2.1 Головні принципи побудови DFD
Існує чотири базових символи, що показані на рис. 2.1, із застосуванням яких аналітик або проектувальник може побудувати DFD. Це потік даних, їх сховище, зовнішній об’єкт і процес.
Приклад DFD наведений на рис. 2.2. Ця діаграма відображає функціональну структуру підсистеми “Оперативно-диспетчерське керування” на рівні лінійно-виробничої ділянки мережі магістральних газопроводів.
Потоки даних відображають проходження інформації через підсистему від її джерел до користувачів. Кожен такий потік потрібно ідентифікувати, для чого треба сформувати та присвоїти йому унікальне ім’я. На початкових етапах формування DFD допускається використання двонаправлених потоків даних, які пізніше треба перетворити на однонаправлені. Особливості властивостей потоків необхідно реєструвати в словнику даних, який потрібно включити до проектної документації.
а)
сховище данихб)
процесв)
зовнішній об'єкт
Рисунок
2.1 – Базові DFD-символи
(нотація SSADM)

![]()
Сховища даних – це місце стаціонарного утримання спеціальних груп даних, які формуються та обробляються в межах системи. Символ сховища даних можна дублювати в межах однієї DFD. При цьому таке сховище позначається спеціальною позначкою. Використання дубльованих символів дозволяє мінімізувати кількість перехрещень ліній потоків даних на діаграмі.
Зовнішній об’єкт представляє на діаграмі джерела та користувачів даних, які знаходяться за межами системи.
Як і сховища даних, ці символи також можуть дублюватися на діаграмі.
Характеристики сховищ даних та зовнішніх об’єктів також необхідно реєструвати в словнику даних.
Процес представляє трансформацію (модифікацію) потоків даних в межах системи і відображає її функціональні особливості. Це – головний елемент схеми з точки зору її подальшої декомпозиції на різних рівнях ієрархії. Таким чином процес спочатку може бути дуже складним і головна мета розробника схеми розкласти його на елементарні складові частини, використовуючи цю методику моделювання.
Діаграма (DFD) може використовуватися для відображення функціональних особливостей системи на різних рівнях деталізації процесів обробки інформації. Найбільш узагальнене первинне відображення будується у вигляді так званої контекстної діаграми. Ця діаграма містить тільки єдиний процес, ім’я якого є найменуванням системи чи підсистеми, зовнішні потоки даних та зовнішні об’єкти (рис. 2.2).
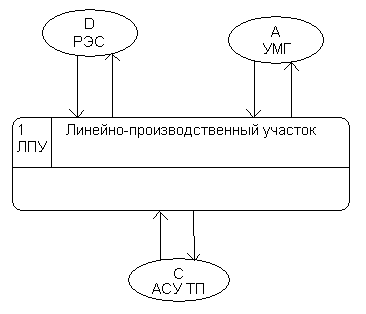
Рисунок 2.2 – Контекстна діаграма
DFD 1-го рівня ієрархії – це деталізоване розкриття контекстної схеми (рис. 2.3). Вона створюється для відображення головних функцій системи та місць зберігання інформації. Межа системи може бути визначена замкненою пунктирною лінією, що відокремлює ту частину системи, яка є суб’єктом аналізу або проектування. Для будь-якої системи може існувати тільки одна конкретна схема та DFD 1-го рівня.
DFD нижчих рівнів ієрархії є результатом декомпозиції процесів вищих рівнів ієрархії. Таким чином, якщо процес 1-го рівня може бути розкладений, то він є причиною побудови DFD 2-го рівня і так далі. Якщо в цьому не виникає особливої потреби, то немає сенсу будувати DFD нижче 3-го рівня ієрархії процесів.
DFD нижче 1-го рівня будуються в розширеному вікні символу батьківського процесу. Ідентифікатори елементів нової DFD наслідують ідентифікатори процесу верхнього рівня і містяться в межах розкритого вікна. За межами вікна знаходяться ті елементи діаграми верхнього рівня, що безпосередньо зв’язані потоками даних з процесом, який декомпозується. Це можна побачити, якщо уважно розглянути приклади на рис. 2.3., 2.4. У межах вікна згідно з домовленостями висловленими відносно базової символіки будується детальна структура функціонального наповнення спрощуваного процесу. При цьому треба враховувати, що ця деталізація потребує спрощення не тільки внутрішніх взаємовідносин між елементами батьківського процесу, але й уточнення деяких властивостей взаємовідносин між цими елементами та елементами діаграми верхнього рівня. Але це питання декомпозиції не тільки процесів, а й зовнішніх об’єктів, сховищ даних та потоків.
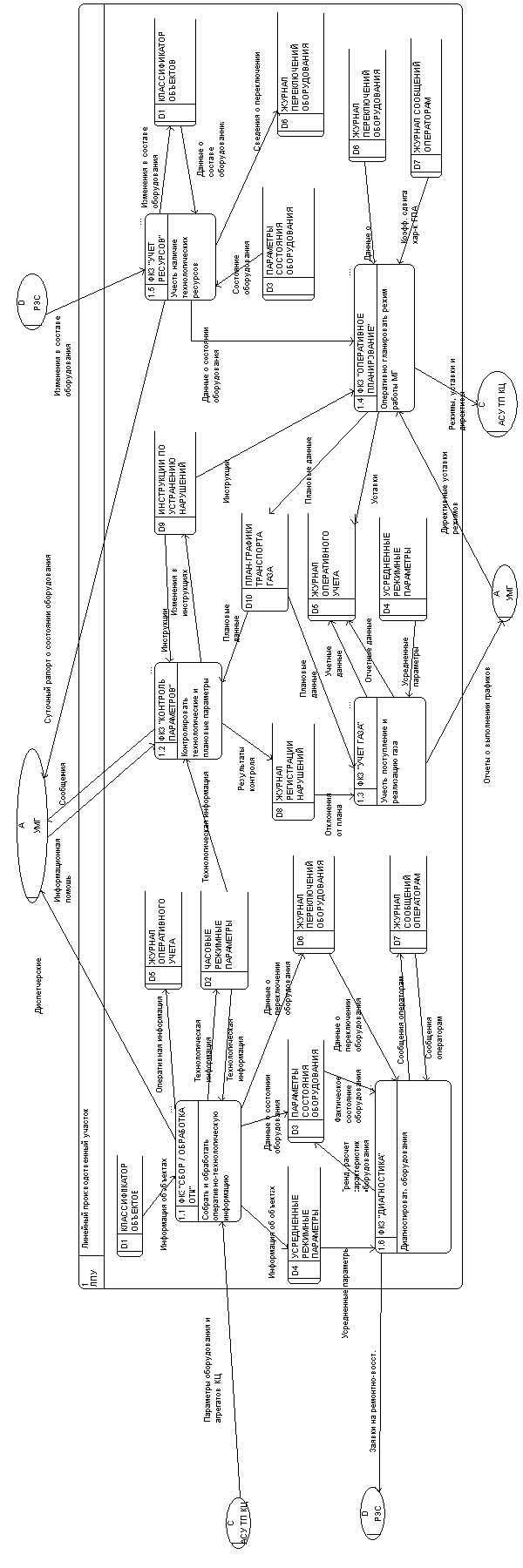


Рисунок 2.4 – DFD 2-го рівня
2.2 Продукти моделювання потоків даних
Результати моделювання потоків даних концентруються в таких продуктах методики:
- ієрархічний комплект діаграм (DFD);
- документи “Опис елементарного процесу”;
- документи “Опис зовнішнього об'єкта”;
- документи “Опис вхід-вихід”.
Це базовий комплект документації відносно моделі потоків даних. Але, якщо розглядати динаміку використання цієї методики в межах процесу проектування системи, то цей комплект може бути доповнений контекстною діаграмою, яка базується при обстеженні системи, і в подальшому може корегуватися, а також документом “Таблиця перехресних посилань Логічне сховище даних / Об’єкт”.
Також є можливість створювати так звані “робочі” документи: “Матриця Процес / Об’єкт”, або “Матриця Логічне / Фізичне сховище даних”. Відносно процедури моделювання потоків даних можна виділити дві головні фази розвитку. По-перше, це побудова моделі, яка описує існуючий етап обробки інформації в системі. По-друге, це перехід на рівні логічних проектних рішень від моделі, що була побудована на першій фазі, до нової моделі, яка фіксує всі рішення, що були прийняті з врахуванням усіх вимог замовника та майбутніх користувачів ІКС.
Таким чином, у глобальному плані методика дає дві базові моделі:
- модель потоків даних існуючої системи (якщо така є у реальному середовищі);
- модель потоків даних системи, що проектується.
Кінцевим продуктом методики є друга з цих моделей, що містить у собі комплект елементарних процесів, на які є специфікації у вигляді “Описів елементарних процесів”, що дає необхідну інформацію для розробки детальних специфікацій на процеси обробки інформації з використанням інструменталь- них засобів конкретних технологій програмування.
2.3 Техніка моделювання
Перед початком розгляду особливостей техніки побудови ієрархічного набору DFD зупинимося на деталізації використання при моделюванні та відображенні на діаграмах основних понять, які були введені в пп. 1.1.
2.3.1 Потоки даних
Базовим у межах даної методики є однонаправлений потік даних, якому бажано (але не обов’язково) присвоїти унікальне ім’я (рис. 2.5, а).
На DFD верхніх рівнів не всі потоки треба показувати у вигляді однонаправлених, тому що тут можуть бути складні (составні) потоки, які дозволяється визначати на всіх діаграмах, окрім діаграм самого нижнього рівня, двонаправленими потоками (рис. 2.5, б).
Для забезпечення можливості відображення найбільш можливих зв’язків за даними між зовнішніми об’єктами, які лежать за межами системи, можна використовувати спеціальний символ зовнішнього потоку даних у вигляді пунктирної лінії (рис. 2.5, в).

Рисунок 2.5 – Типи потоків даних
2.3.2 Сховища даних
Це поняття відображає на діаграмах місця зберігання інформації, яка у межах існуючої системи, або системи, що проектується, є елементом або групою елементів її інформаційного забезпечення. Сховища даних зображуються відкритим з правої сторони вузьким прямокутником (рис. 2.6, а). Ліва сторона цього прямокутника може мати подвоєну лінію для того, щоб позначити за необхідності факт дублювання будь-якого сховища на конкретній DFD (рис. 2.6, б). Зліва у прямокутнику виділяється зона, де розміщується ідентифікатор сховища даних. Справа знаходиться зона імені, яке коротко характеризує сукупність елементів інформаційного забезпечення системи, що зберігаються у даному сховищі. Стосовно ідентифікаторів необхідно відзначити:
- для визначення комп’ютерної форми зберігання даних треба використовувати великі латинські літери “D” або ”C” (від англійських слів “digital” та ”computer”);
- сховища для тимчасового зберігання даних, які зникають після їх обробки, треба позначати літерою “T” (від слова “transient”);
- сховища, які визначають місця зберігання інформації, що представлена у традиційних паперових формах, ідентифікується літерою “M” (від слова “manual”).
Таким чином літерна частина ідентифікаторів сховища даних визначає їх тип. Однак ідентифікатори мають ще й числову частину. Розглянемо особливості формування цієї частини ідентифікаторів.
Для DFD 1-го рівня ця частина має бути у вигляді десяткового цифрового суфіксу, що буде визначати ці сховища, як головні для всієї моделі потоків даних (рис. 2.6, а).
Для діаграм нижчих рівнів цього недостатньо, тому ідентифікатори сховищ нижчих рівнів після літери мають номер процесу, елементом декомпозиції якого є таке сховище, і далі через косу риску ставиться його числовий номер.
Наприклад, декомпозиція процесу в DFD 1-го рівня буде означати, що числова частина ідентифікаторів всіх сховищ даних, які знаходяться на його DFD 2-го рівня, буде починатися з числа “6”, за яким слідуватиме символ “/”, а потім порядковий номер сховища; і так далі для всіх рівнів ієрархії процесів. Це проілюстровано на рис. 2.6, в.
Для відображення результатів декомпозиції сховищ даних із DFD вищих рівнів на діаграмах нижчих рівнів ідентифікатори цих сховищ можуть бути розширені літерним суфіксом. При цьому треба використовувати малі літери латинського алфавіту, які дописуються до основного ідентифікатора. Наприклад, елементи декомпозиції сховища D6 можуть бути ідентифіковані як D6а, D6б, D6с, …, а для D6/3 буде D6/3а, D6/3в (рис. 2.6, г).

Рисунок 2.6 – Типи сховищ даних
2.3.3 Зовнішні об’єкти
Для того, щоб відобразити на діаграмах повторюваність символів зовнішнього об'єкта використовується спеціальна позначка у вигляді лінії, що відокремлює частину площини еліпса, як базового схематичного символу. Кожний зовнішній об’єкт повинен мати свій унікальний ідентифікатор у вигляді малої букви латинського алфавіту. Якщо букв не вистачає (при великій кількості зовнішніх об’єктів) можна використовувати здвоєний ідентифікатор (аа, аб, …).
У випадках, коли треба декомпозувати на нижніх рівнях складний зовнішній об’єкт верхнього рівня, допускається використання числового суфікса, яким заповнюється ідентифікатор основного зовнішнього об'єкта. При цьому можна елементу декомпозиції присвоювати нове унікальне ім’я. Зв’язок між основним зовнішнім об’єктом та елементами декомпозиції реалізується через літеру ідентифікатора першого. Приклади всіх цих випадків наведені на рис. 2.7.

Рисунок 2.7 – Варіанти зображення зовнішніх об'єктів
2.3.4 Процеси
Базові символи та поняття DFD-процесу були наведені раніше на рис. 2.1 та в пп. 1.1, тому нижче будемо розглядати особливості визначення процесів на різних рівнях ієрархії діаграм.
Якщо розглянути базовий символ, то можна побачити, що вся площина прямокутника розділена на три поля. Найменше поле у верхньому лівому куті – поле ідентифікатора, який за правилами є цілим десятковим числом (для DFD 1-го рівня). Для визначення нижчих рівнів послідовно вводяться через крапку такі самі десяткові суфікси. Наприклад, якщо ми маємо процес 6 на 1-му рівні, то для 2-го рівня елементами його декомпозиції (підпроцесами) будуть процеси 6.1, 6.2, …, для 3-го рівня відповідно 6.1.1, 6.1.2, …, 6.2.1, 6.2.2, … .
З правого боку від поля ідентифікатора міститься поле, в якому можна вписувати місцезнаходження процесу, але воно заповнюється лише для DFD, які входять до складу моделі потоків даних існуючої системи. Тут реєструють назву служби, відділу або посадової особи, що виконують процедури, пов’язані з конкретним процесом. Після того, як починається процес перетворення цієї моделі на модель системи, що проектується, всі посилання на місцезнахо- дження процесу треба вилучити. Це робиться для того, щоб процес перетворення моделі виконувався на кожному рівні без обмежень, які виникають із особливостей організаційної структури існуючої системи.
Таким чином в моделі потоків даних для системи, що проектується, це поле має бути чистим.
Третє поле – поле імені процесу. Ім’я процесу має бути коротким і змістовним, та повністю відображати суть тієї частини ділових операцій, на які спрямована мета введення процесу DFD на будь-якому рівні. Крім того ім’я має починатися з дієслова у невизначеній формі.
Якщо процес є процесом найнижчого рівня ієрархії, то позначка про цей факт може бути введена в допоміжне необов’язкове поле індикатора елементарного процесу, яке виділяється в правому куті прямокутника косою рискою із зірочкою “ * ”, або якимось іншим способом. Такі процеси обов’язково мають підтримуватися документами “Опис елементарного процесу” (ОЕП) (додаток Б).
ОЕП містить опис мети процесу, що мусить займати не більш півсторінки форми документа. Крім того ОЕП визначає роль процесу в контексті його зв’язку з іншими процесами, зовнішніми об’єктами, сховищами даних та потоками даних. У випадку, коли ОЕП потребує більш ніж півсторінки тексту, це може бути знаком того, що процес потребує подальшої декомпозиції.
На DFD (особливо нижчих рівнів ієрархії) часто зустрічаються так звані загальні процеси (common-процеси). Це процеси, які реалізують однакові дії з однаковими або різними даними. Форма ОЕП дозволяє виконати одноразове описання такого процесу за рахунок перехресних посилань.
2.3.5 Деякі правила побудови DFD 1-го рівня
Контекстна діаграма є важливим відправним пунктом до початку аналітичних робіт на стадії обстеження системи. Після того, як вона побудована та узгоджена із користувачами (замовниками проекту), вона має бути трансформована в DFD 1-го рівня без втрати інформації про безпосереднє оточення системи, яке вже визначено у вигляді зовнішніх об’єктів та потоків даних, які перетинають межу системи, що аналізується.
Подальші дії будуть сфокусовані аналітиком на процесах обробки інформації більш, ніж на процесах обслуговування запитів на інформацію до системи або від неї. Тому при побудові контекстної діаграми треба сконцентрувати всі зусилля на з`ясуванні діапазону та суті запитів, які несуть в собі потоки даних, що зв’язують зовнішні об’єкти з системою.
Наступна стадія аналізу потребує розкладання єдиного в контекстній діаграмі процесу на не більш як 15 процесів 1-го рівня. На початку ці процеси можуть бути безпосередньо пов’язаними реальними підрозділами існуючої системи або конкретними персоналіями та посадами. Однак не треба думати, що цей розподіл обов’язків є кінцевим результатом. Таким чином, процес створення DFD є ітеративною процедурою пошуку раціонального проектного рішення.
Ця процедура починається з пошуку процесів, які є джерелами та користувачами потоків даних, що пов’язують систему із зовнішніми об’єктами та були введені на контекстній діаграмі. Таким чином, процес дослідження йде від межі системи в середину тому, що далі аналітику треба знайти зв’язок знайдених процесів з іншими процесами та сховищами даних. При цьому всі головні сховища й потоки даних, які були виділені з системного середовища, треба відповідним чином зареєструвати та описати в документації, форми якої наведені у додатку Б.
2.3.6 Деякі правила побудови DFD нижчих рівней
Кожен з процесів 1-го рівня ієрархії у більшості випадків потребує декомпозиції на 2-му рівні. Там де це необхідно, вони можуть бути декомпозо- вані далі на 3-му рівні DFD. Ця процедура може бути описана як послідовність дій проектувальника.
Будь-який процес 1-го рівня тут розглядався як система зі своїми законами та правилами функціонування, до складу якої входить деяка кількість елементів. Таким чином, межа символу цього процесу стає межею для DFD 2-го рівня. За цією межею лишаються об’єкти DFD 1-го рівня, що безпосередньо зв’язані потоками даних з процесом, який декомпозується. В середині поля вікна, яке є розширеним символом процесу, що декомпозується, проектуваль- ник розкриває його зміст, використовуючи введену раніше символіку та правила використання ідентифікаторів елементів діаграм. При введенні імен для процесів, сховищ даних та потоків треба враховувати той факт, що результат схематизації на нижчих рівнях має бути зрозумілим для майбутніх користувачів ІКС. Таким чином, розробник DFD нижчих рівнів повинен повністю узгодити своє уявлення про конкретний процес із вимогами користувача системи. Для цього розробнику треба, якщо це необхідно, розглянути всі шляхи проходження інформації від виходів процесу, яких вимагає користувач, до входів в процес, які формуються іншими процесами або зовнішніми об’єктами, чи знаходяться у вигляді підготовлених даних у відповідних сховищах.
Після побудови DFD 2-го рівня треба вирішити, чи досягнутий потрібний рівень деталізації процесу. Такий рівень згідно з загальними принципами моделювання потоків даних має бути забезпеченим на DFD 2-го або не нижче 3-го рівня ієрархії.
Деякі розробники закінчують цю процедуру, коли процеси мають один вхідний потік та/або один вихідний потік. Інший варіант – розглядати процедуру як завершену, якщо елементи декомпозиції є нерозподіленими на рівні уявлень користувача системи про її функціонування.
Процеси на DFD найвищого рівня визначаються терміном “елементарні процеси”. Такі процеси обов’язково повинні мати опис у вигляді ОЕП. Після закінчення процедури формування комплекту DFD діаграми необхідно обов’язково переглянути та узгодити з користувачами (представниками замовника проекту) і за необхідності внести в них відповідні поправки.
На рис. 2.4 наведений приклад декомпозиції процесу 4 1-го рівня “Оперативне планування режиму роботи МГ”.
2.3.7 Перевірка правильності DFD
Існує декілька простих запитань, на які необхідно отримати відповіді при виконанні цієї процедури. Це може допомогти при вирішенні проблеми.
1. Чи відповідає побудована модель поглядам користувачів на функціонування системи та чи згодні вони з цією моделлю?
2. Чи всі процеси мають прості та зрозумілі імена, в яких нема словосполучень “робити щось”, “отримати що-небудь” або “процес що”?
3. Чи узгоджені потоки, що входять до процесів або сховищ даних та виходять з них, з цими елементами, їх змістом та іменами?
4. Чи керується процес тільки одним потоком? Якщо він має декілька таких потоків, потрібно розглянути відносно кожного специфічного випадку.
5. Чи створюють процеси дані? Цього не повинно бути. Дані мають приходити від сховищ або зовнішніх об’єктів.
6. Чи багато потоків між будь-якими парами елементів діаграми? Якщо це так, то потрібно більш уважно розглянути цю ділянку діаграми.
7. Чи кожен рівень DFD-ієрархії відповідає вимогам детальності відображення особливостей функціонування системи, що моделюється?
8. Чи всі рівні DFD-ієрархії узгоджені між собою? Це може бути перевірено шляхом порівняння потоків даних перетинаючих межі конкретного DFD з потоками, які входять та виходять з процесу на верхньому рівні. Подібна процедура може бути виконана також для сховищ даних та зовнішніх об’єктів. Виконання цієї процедури потребує значних зусиль, особливо у випадках складних та двонаправлених потоків.
Після закінчення цього розділу необхідно показати загальні правила з’єднання елементів діаграм, які дійсні для DFD усіх рівнів ієрархії. Ці правила проілюстровані у вигляді матриці зв’язків на рис. 2.8.
|
Елемент DFD |
Зовнішній об’єкт |
Процес |
Сховище даних |
|
Зовнішній об’єкт |
Так (зовнішній потік даних) |
Так (потік даних) |
Ні |
|
Процес |
Так (потік даних) |
Так (потік даних) |
Так (потік даних) |
|
Сховище даних |
Ні |
Так (потік даних) |
Ні |
Рисунок 2.8 – Правила з’єднання елементів DFD
2.3.8 Перехід від моделі потоків даних існуючої системи до моделі системи, що проектується
Для цього етапу моделювання системи з використанням методики побудування DFD характерна концентрація зусиль проектувальника на виконанні процедури переходу від фізичного рівня відображення властивостей та характеристик системи до логічного уявлення цих аспектів. Процедура включає серію задач, які потребують ретельного вирішення.
По-перше, раціоналізація сховищ даних. Це виконується шляхом розгляду особливостей логічної моделі даних системи, яка в даному випадку є керівництвом і засобом перевірки розподілу інформаційних об’єктів (суттєвостей) поміж логічними сховищами даних. При цьому мають підтвердитися такі факти:
- кожне таке сховище зберігає в собі один або більше інформаційних об’єктів;
- немає інформаційних об’єктів, які зберігаються більш ніж в одному сховищі даних.
Сховища термінових даних включаються у відповідні потоки даних і таким чином виділяються із DFD. Під час визначення задач цього етапу суттєво можуть допомогти документи “Таблиця перехресних посилань Логічне сховище даних / Об’єкт” і “Таблиця перехресних посилань Логічне / Фізичне сховище даних”.
По-друге, раціоналізуються процеси. Це виконується шляхом перегляду, починаючи з найнижчого рівня, всіх діаграм з метою видалення всіх елементів фізичної реалізації процесів (таких, наприклад, як сортування даних або перерозподіл). Видаляється також дублювання процесів. Треба зауважити, що будь-яке видалення процесів потрібно переглянути на предмет необхідної реєстрації деяких особливостей у вигляді вимог до нової системи. Процеси також можуть бути змінені для того, щоб краще відобразити результати раціоналізації сховищ даних.
Ієрархія DFD заново конструюється від цієї нової бази шляхом групування елементарних процесів. Основа виконання процедури групування по суті є інтуїтивною, але сама процедура має керуватися деякими принципами. Таких принципів усього три:
- сумісне використання даних;
- підтримка подібних вимог користувачів;
- подібні типи обробки даних.
Як домінантний рекомендується використовувати другий з вищеназваних принципів. Це дає групування, які найкраще узгоджуються з тим, що функції ІКС мають максимально відповідати вимогам майбутніх користувачів системи.
По-третє, переглядаються потоки даних на предмет видалення з відповідних описів конкретики фізичної реалізації в існуючому системному середовищі, а також видалення потоків не потрібних для нової системи даних. Перевіряється коректність з’єднань процесів та сховищ даних.
По-четверте, імена та ідентифікатори всіх компонент моделі потоків даних розглядаються з точки зору внесення в них змін відповідних до змін внесених в DFD під час виконання попередніх етапів процедури. Деякі зміни можуть бути обумовлене необхідністю видалення посилань на фізичні особливості системи, інші – необхідністю підкреслення змін відносно існуючої системи. В цілому, необхідно зводити кількість змін до мінімуму.
Після закінчення процедури, що описана вище, необхідно знову переглянути побудовану модель. Вона обов’язково має бути узгоджена з користувача- ми, що можуть направляти процес подальших змін моделі. Процедура перевірки, яка наведена в п.п. 2.3.7, обов’язково виконується після кожної ітерації використання описаної вище процедури. Така комплексна перевірка необхідна для пошуку, обгрунтування та реєстрації всіх відмінностей між існуючою та новою системою.
2.3.9 Зв’язок моделі потоків даних з функціями системи
Головною метою моделювання потоків даних з використанням DFD є підготовка до ідентифікації функцій майбутньої ІКС. У більшості випадків поняття реальної системи значно ширше ніж та частина дій, яка покладається на ІКС. Тому DFD використовуються в основному для того, щоб викристалізувати цю частину з усього різноманіття дій, які реально виконують працівники в повсякденній реальності.
Зв’язок між моделлю та функціями системи головним чином здійснюється через події. Події – це сигнали про зміни в реальному оточенні системи, які абсолютно необхідні, щоб ІКС мала зв’язок з цим оточенням.
Як тільки ІКС приймає подію, функція має зібрати всі процеси обробки інформації й виконати всі необхідні дії для обробки події та видачі користувачам відповідної реакції.
Моделі потоків даних займають важливе місце в ідентифікації подій та функцій, тому що вони відображають потоки даних, які є основним джерелом подій. Існує лише один тип подій, які не переносяться потоками даних. Це системні події або події, що відбуваються згідно з часовою шкалою. Одним із способів ідентифікації таких подій є пошук і розгляд процесів, які не мають вхідних потоків, що несуть в собі будь-які події. Таким чином, шляхом відстеження впливу подій на елементарні процеси можуть бути виявлені всі функції системи.
Існує ще один метод ідентифікації подій, пов’язаний із достатньо трудомістким аналізом впливу подій на інформаційні об’єкти в базі даних. Але цей метод базується на продуктах іншої методики моделювання, що викладені в розділі 3.
Треба зауважити, що процес трансформації моделі потоків даних закінчується лише тоді, коли стає ясно, що модель підтримує обробку і забезпечує реакції системи на всі події згідно з вимогами користувача. Тільки така модель може вважатися моделлю потоків даних системи, що проектується.