

Lektsia_05_new_MS_end
.pdfМАТЕМАТИЧЕСКАЯ
СТАТИСТИКА
ЛЕКЦИЯ 12
РАЗДЕЛ 5
ОСНОВЫ КОРРЕЛЯЦИОННОГО АНАЛИЗА
5.01. Исходные понятия
5.02. Анализ парных связей
5.03. Анализ коэффициента корреляции
5.04. Анализ корреляционного отношения
5.05. Анализ множественных связей
1
5.1. Исходные понятия
При решении прикладных задач в различных областях человеческой деятельности, в том числе и в инженерной практике, исследователь нередко сталкивается с необходимостью установления факта существования функциональных или иных зависимостей между переменными величинами, которые могут быть и случайными.
Обычно приходят к одной из следующих ситуаций.
1. Зависимое переменное Y может быть случайной величиной, даже если переменные X1, …, Xp таковыми не являются, так как значение Y оп-
ределяется не только значениями переменных X1, …, Xp , которые исследо-
ватель выделил (по его мнению, они являются определяющими), но и многими другими неучтенными факторами, а также ошибками измерений. Это
означает, что связь между X1, …, Xp и Y является не функциональной, а
стохастической – изменение переменных X1, …, Xp влияет на значения пе-
ременного Y через изменение закона распределения случайной величины
Y .
2.Некоторые переменные могут иметь количественный характер, а некоторые – качественный.
3.Нас может интересовать либо зависимость переменного Y от пере-
менных X1, …, Xp , либо взаимозависимость между несколькими перемен-
ными (не обязательно между всеми).
Перечисленные особенности приводят к различным постановкам задач статистического исследования зависимостей, которые упрощенно можно классифицировать следующим образом:
–задачи корреляционного анализа – задачи исследования наличия взаимосвязей между отдельными группами переменных;
–задачи регрессионного анализа – задачи, связанные с установлением аналитических зависимостей между переменным Y и одним или нескольки-
ми переменными X1, …, Xp , которые носят количественный характер;
– задачи дисперсионного анализа – задачи, в которых переменные
X1, …, Xp имеют качественный характер, а исследуется и устанавливается
2
степень их влияния на переменное Y .
Анализу наличия взаимосвязей между отдельными группами переменных и посвящена эта тема. Задачи регрессионного и дисперсионного анализа будут рассмотрены далее.
Кроме перечисленных типов задач выделяют и многие другие. Так, ковариационный анализ рассматривает одновременно и количественные и ка-
чественные переменные X1, …, Xp , конфлюентный анализ обобщает рег-
рессионный на тот случай, когда переменные X1, …, Xp и Y измеряют с ошибками, факторный анализ служит для выделения из множества исследуемых переменных X1, …, Xp наиболее значимых.
Для удобства дальнейших рассуждений обратимся к так называемой модели “черного ящика” (рис. 5.1) как наиболее общей модели любой ре-
альной системы, ассоциированной с понятием отображения f : X →Y . На
вход “черного ящика” поступает входной сигнал – вектор X , который по-
средством отображения f преобразуется в выходной сигнал – вектор Y .
При этом, в соответствии со сложившийся терминологией, X =(X1, …, Xp ) –
вектор входных переменных, или вектор факторов; Y =(Y1, …,Ym ) – вектор выходных переменных, или вектор откликов; ε =Y − f (X) , ε =(ε1, ..., εm ) – вектор случайных ошибок, т.е. случайных переменных, отражающих влия-
ние на переменные Yi , |
i = 1, m , неучтенных факторов, а также случайных |
||
ошибок измерений анализируемых показателей. |
|||
X1 |
|
|
Y1 |
|
|
||
# |
|
|
# |
X p |
|
|
Ym |
ε1 … εm
Рис. 5.1 – Модель “черного ящика”
При проведении корреляционного анализа исследователь должен
3
уметь:
а) выбрать показатель стохастической связи анализируемых переменных;
б) оценить его значение по имеющимся экспериментальным данным,
т.е. найти его точечную и интервальную оценки;
в) проверить статистическую гипотезу о том, что значение показателя стохастической связи значимо отличается от нуля.
Ниже дано описание методов и моделей, используемых для решения перечисленных задач.
5.2. Анализ парных связей
Выбор показателя связи. Для начала рассмотрим задачу выбора показателя стохастической связи между двумя случайными величинами ξ и
η , реализации которых будем обозначать соответственно через x и y . Пусть случайный вектор (ξ, η) имеет нормальный закон распределения
с математическим ожиданием μ =(μ1, μ2 ) и ковариационной матрицей
|
|
|
|
σ2 |
ρσ σ |
|
|
|
|
|
|
|
1 |
1 2 |
|
, |
|
|
|
Σ = |
|
|
|
2 |
|
|
|
|
|
ρσ σ |
σ |
|
|
||
|
|
|
|
|
|
|||
|
|
|
2 |
|
|
|||
|
|
|
1 2 |
|
|
|||
где σ2 |
и σ2 |
– дисперсии случайных величин |
|
ξ и η соответственно, а ρ – |
||||
1 |
2 |
|
|
|
|
|
|
|
коэффициент корреляции между ξ |
и η . |
|
|
|
|
|||
Вэтом случае условная плотность распределения случайной величины
ηпри условии, что ξ = x ,
|
|
|
|
(y−μ |
)2 |
|
1 |
|
− |
η|x |
|
p(y | x) = |
e |
2ση2|x |
|
||
|
|
||||
|
|
|
|
2πση|x
является плотностью нормального распределения с параметрами μη|x (ус-
ловное математическое ожидание) и ση2|x (условная дисперсия η ) при зна-
чении ξ = x , которые связаны с параметрами исходного двумерного распределения следующим образом:
M(η | ξ = x) = μ |
= μ + ρ |
σ2 |
(x −μ ) , |
(5.1) |
|
||||
η|x |
2 |
σ1 |
1 |
|
|
|
|
|
|
|
|
4 |
D(η | ξ = x) = σ2 |
= σ2 |
(1 −ρ2 ) . |
(5.2) |
η|x |
2 |
|
|
Как видно, в рассматриваемом случае линия регрессии является прямой, а условная дисперсия не зависит от x .
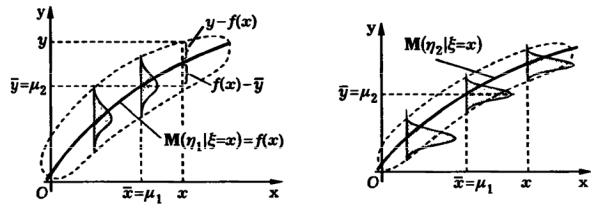
Если закон распределения случайного вектора (ξ, η) не является нормальным, то характер изменения условного математического ожидания M(η | ξ = x) = f (x) может быть и нелинейным, причем, чем меньше условная дисперсия D(η | ξ = x) , тем меньше при различных значениях x рассеяны возможные значения случайной величины η относительно линии регрессии M(η | ξ = x) = f (x) (рис. 5.2). Функцию f (x) = M(η | ξ = x) называют функцией регрессии, или регрессией.
Рис. 5.2
Обозначим Mη = μ, Dη = σ2 . Отклонение y −μ возможных значений η |
|
η |
|
от μ складывается из двух слагаемых (см. рис. 5.2): |
|
y −μ = (f (x) −μ) +(y − f (x)) |
(5.3) |
где f (x) −μ – отклонение функции регрессии f (x) в точке x |
от математиче- |
ского ожидания μ ; y − f (x) – отклонение возможного значения η от значения функции регрессии в точке x .
Покажем, что рассеяние ση2 случайной величины η относительно ее ма-
тематического ожидания есть сумма двух слагаемых, а именно: математического ожидания квадрата отклонения η от ее условного математического
ожидания f (ξ) и математического ожидания квадрата отклонения f (ξ) от μ . Действительно,
M(f (ξ)) = M(M(η | ξ)) = Mη = μ ,

5
Dη = ση2 = M(η −μ)2 = M((η − f (ξ)) +(f (ξ) −μ))2 = = M(η − f (ξ))2 +2M[(η − f (ξ))(f (ξ) −μ)] +M(f (ξ) −μ)2 =
= M(η − f (ξ))2 +M(f (ξ) −μ)2 , так как M[(η − f (ξ))(f (ξ) −μ)] = 0 .
Докажем последнее равенство для непрерывных случайных величин ξ и η , предполагая, что их совместная плотность распределения p(x, y) в 2 не обращается в нуль:
+∞ +∞
M[(η − f (ξ))(f (ξ) −μ)] = ∫ ∫ (y − f (x))(f (x) −μ)p(x, y)dxdy =
−∞ −∞
|
|
+∞ |
|
|
|
|
|
+∞ |
|
|
|
p(x, y) |
|
|
|
|
|
|
||||
|
|
= ∫ (f (x) −μ)pξ(x)dx ∫ (y − f (x)) |
dy = |
|
|
|||||||||||||||||
|
|
|
|
|
|
|||||||||||||||||
|
|
−∞ |
|
|
|
|
|
−∞ |
|
|
|
pξ(x) |
|
|
|
|
|
|||||
|
+∞ |
|
|
|
|
+∞ |
|
p(x, y) |
|
|
|
|
+∞ |
p(x, y) |
|
|
|
|||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
= |
∫ |
|
ξ |
|
|
∫ |
y |
|
|
dy − f (x) |
∫ |
|
|
|
|
|
= 0 |
, |
||||
|
|
|
|
|
|
|
|
|||||||||||||||
|
(f (x) −μ)p |
(x)dx |
|
|
|
|
|
|
|
dy |
||||||||||||
|
|
|
|
|
|
|
|
p |
(x) |
|
|
|
|
|
|
p |
(x) |
|
|
|
||
|
−∞ |
|
|
|
|
−∞ |
|
|
|
|
|
−∞ |
|
|
||||||||
|
|
|
|
|
|
ξ |
|
|
|
|
|
ξ |
|
|
|
|
|
|||||
так как: |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
+∞ |
p(x, y) |
|
|
|
|
+∞ |
p(x, y) |
|
|
|
|
|
|
|
|
|
||||
|
|
∫ y |
dy = f (x) , |
∫ |
dy =1 . |
|
|
|
||||||||||||||
|
|
|
|
|
|
|
||||||||||||||||
|
|
−∞ |
p |
(x) |
|
|
|
−∞ |
p |
(x) |
|
|
|
|
|
|
|
|
||||
|
|
|
ξ |
|
|
|
|
|
ξ |
|
|
|
|
|
|
|
|
|
|
|
||
Таким образом, если воспользоваться обозначениями:
σf2 = Df (ξ) = M(f (ξ) −μ)2 , ση2 = M(η − f (ξ))2 ,
то полученный результат может быть представлен в виде:
ση2 = σf2 +ση2
Из равенства (5.4) следует, что связь между ξ и η
(5.4)
тем теснее, чем
меньше слагаемое ση2 или чем больший вклад в дисперсию ση2 вносит сла-
гаемое σf2 , порожденное функцией регрессии f (x) = M(η | ξ = x) . Тем самым
мы приходим к понятию общей характеристики степени тесноты связи – корреляционному отношению переменного η по переменному ξ :
|
σ2 |
|
|
σ |
2 |
|
|
r = |
f |
= |
1 − |
η |
. |
(5.5) |
|
σ2 |
|
||||||
ηξ |
|
|
σ2 |
|
|||
|
η |
|
|
η |
|
||

|
|
|
6 |
Непосредственно из (5.5) следует, что всегда выполняется неравенство |
|||
|
0 ≤r2 ≤1 , |
|
(5.6) |
|
ηξ |
|
|
причем равенство r2 |
= 0 означает, что с изменением |
ξ |
вариация функции |
ηξ |
|
|
|
регрессии f (x) полностью отсутствует. Другими словами, случайные вели- |
|||
чины ξ и η являются независимыми. В этом случае линия регрессии есть
горизонтальная |
прямая. |
Равенство |
r2 =1 будет иметь |
место, если |
||
|
|
|
|
|
ηξ |
|
σ |
η2 |
= M(η − f (ξ))2 |
= 0 , т.е. |
если η и ξ |
связаны функциональной зависимо- |
|
стью η = f (ξ) . |
|
|
|
|
||
|
|
Аналогично определяется корреляционное отношение rξη |
переменной |
|||
ξ |
по η . |
|
|
|
|
|
Отметим, что между rηξ и rξη нет какой-либо простой зависимости. Воз-
можны ситуации, в которых один из этих показателей принимает нулевое значение, в то время как другой равен единице. Пусть, например, η = ξ2 , а
ξ принимает следующие значения: −1 , 0 , 1 с вероятностями 13 каждое. В
этом случае rηξ =1 , rξη = 0 (в силу симметричности параболы относительно оси значений η и симметричности распределения ξ ).
Итак, решение задачи выбора показателя стохастической связи между двумя случайными величинами ξ и η для самой общей ситуации, когда за-
кон распределения вектора (ξ, η) является произвольным, найдено – таким
показателем являются корреляционные отношения rηξ |
иrξη . |
|||
Выясним, какую роль играет такой показатель связи между случайными |
||||
величинами ξ |
и η как коэффициент корреляции ρ: |
|
||
|
ρ = |
M[(ξ −Mξ)(η −Mη)] |
, |
(5.7) |
|
|
|||
|
|
σ1σ2 |
|
|
где σ1 = Dξ , |
σ2 = Dη , M[(ξ −Mξ)(η −Mη)] – второй смешанный момент |
|||
случайного вектора (ξ, η) . |
|
|||
Напомним, что случайные величины ξ и η называют некоррелирован-

7
ными, если ρ = 0 , и коррелированными при ρ ≠ 0 .
Известно, что из независимости случайных величин ξ и η следует их
некоррелированность, однако обратное утверждение в общем случае неверно.
Если случайный вектор (ξ, η) имеет нормальный закон распределения, то линия регрессии η по ξ (и ξ по η ) является прямой (см. формулу (5.1)), т.е. коэффициент корреляции ρ может служить мерой связи между ξ и η . Для нормального закона распределения на основании (5.2) и (5.5) имеем
rηξ2 = rξη2 = ρ2
Действительно, из (5.2) получаем, что условная дисперсия η не зависит от значений случайной величины ξ , и, следовательно:
ση2(1 −ρ2 ) = D(η | ξ) = M(η −M(η | ξ)2 | ξ)=
= M((η − f (ξ))2|ξ)= M(η − f (ξ))2 = ση2 .
Наконец, учитывая (5.5) и полученный результат, приходим к равенству rηξ2 = ρ2 . Аналогично можно доказать равенство rξη2 = ρ2 . Таким образом,
корреляционные отношения совпадают между собой и с абсолютной величиной коэффициента корреляции ρ . При этом равенство ρ =1 означает линейную функциональную зависимость между ξ и η , а равенство ρ = 0
свидетельствует об их линейной независимости.
Понятно, что рассмотренными свойствами двумерного нормального закона не могут обладать все двумерные законы распределения или хотя бы их большая часть. Поэтому в общем случае не имеет смысла использование коэффициента корреляции ρ как меры взаимосвязи случайных величин ξ и
η .
В общем случае показатели r2 и ρ2 связаны неравенствами: |
|
|
ηξ |
|
|
0 ≤ ρ2 ≤r2 |
≤1 . |
(5.8) |
ηξ |
|
|
При этом возможны следующие варианты: |
|
|
а) ρ2 = 0 , если ξ и η независимы, |
но обратное (в общем случае) не- |
|
верно;

8
б) ρ2 = rηξ2 =1 тогда и только тогда, когда имеется строгая линейная функциональная зависимость η от ξ ;
в) ρ2 ≤rηξ2 =1 тогда и только тогда, когда имеется строгая нелинейная функциональная зависимость η от ξ ;
г) ρ2 = rηξ2 <1 тогда и только тогда, когда регрессия η по ξ строго ли-
нейна, но нет функциональной зависимости;
д) ρ2 <rηξ2 <1 указывает на то, что не существует функциональной зави-
симости, а некоторая нелинейная кривая регрессии “подходит” лучше, чем “наилучшая” прямая линия.
Итак, в качестве показателя стохастической связи между двумя случайными количественными переменными ξ и η следует выбрать корреляцион-
ное отношение rηξ (или rξη ), если закон распределения вектора (ξ, η) вызы-
вает сомнение. Если же можно с большой степенью уверенности считать закон распределения вектора (ξ, η) нормальным, то вместо корреляционного отношения следует использовать коэффициент корреляции ρ.
Оценка показателя связи по выборочным данным. После выбора показателя стохастической связи задача корреляционного анализа, как уже отмечалось в 5.1, состоит в нахождении его оценки (точечной и интервальной), а также в проверке статистической гипотезы о значимом отличии его от нуля на основе экспериментальных данных.
Пусть в результате эксперимента получены n выборочных значений случайного вектора (ξ, η) , которые будем записывать в виде
(xi , yi ) , i = 1, n . |
(5.9) |
При изучении корреляционной зависимости |
двух случайных величин |
(ξ, η) по выборке (xi , yi ) , i = 1, n , общую картину их взаимной изменчивости
можно получить, изобразив на координатной плоскости все точки. Это изо-
бражение называют корреляционным полем.
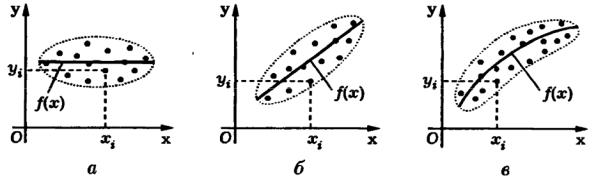
Уже по виду корреляционного поля можно иногда сделать вывод о наличии и характере связи между случайными величинами ξ и η . Так, на
рис. 5.3, а, выборочные точки (xi , yi ) лежат внутри некоторого эллипса (эллипса рассеяния) с осями, параллельными координатным. Следовательно, с
|
|
|
|
|
|
9 |
изменением, |
например, |
ξ величина η |
не будет менять своего условного |
|||
распределения, т.е. |
по-видимому, |
некоррелированы. Напротив, на |
||||
рис. 5.3, б |
видно, |
что |
условное |
математическое |
ожидание |
|
M(η|ξ = x) = f (x) имеет линейный характер изменения, и, значит, следует ожидать, что коэффициент корреляции ρ близок к единице. На рис. 6.3, в
расположение точек (xi , yi ) говорит о наличии нелинейного характера изме-
нения f (x) и, следовательно, коэффициент корреляции может оказаться близким к нулю, а корреляционное отношение rηε – близким к единице.
|
|
|
Рис. 5.3 |
|
|
|
||||||
Следует отметить, что в том случае, когда среди xi |
есть повторяющие- |
|||||||||||
ся с частотой ni |
значения, выборочные значения представляют в виде |
|||||||||||
|
|
|
|
|
|
|
|
|
|
m |
|
|
|
(xi, yij ) , j =1, ni , i = 1, m , |
∑ni = n . |
|
(5.10) |
||||||||
|
|
|
|
|
|
|
|
|
|
i=1 |
|
|
Если выборочные значения сгруппированы по каждой из переменных, |
||||||||||||
т.е. значения xi |
разделены на m групп, а значения yi |
– на l |
групп, то вы- |
|||||||||
борочные значения представляют в виде |
|
|
|
|||||||||
|
|
|
|
|
|
∑nij = n . |
|
|||||
|
(xi , yi , nij ) , i =1, m , j =1, l , |
(5.11) |
||||||||||
|
|
|
|
|
|
|
|
|
|
i, j |
|
|
или в виде корреляционной таблицы, в каждой клетке которой указывают число nij попавших в нее выборочных значений, причем сумма всех этих значений равна n (табл. 5.1).