

СПО / Semestr 2 / Lectures 2semestr / Lecture 2_01 / Lecture 2_01
.docЛекция 1
Использование масок переменной длины
В предыдущем примере использования масок все подсети имеют одинаковую длину поля номера сети - 18 двоичных разрядов, и, следовательно, для нумерации узлов в каждой из них отводится по 14 разрядов. Все сети являются очень большими и имеют одинаковый размер. Однако более эффективным явиляется разбиение сети на подсети разного размера. Например, большое число узлов, подходящее для пользовательской подсети, является избыточным для подсети, которая связывает два маршрутизатора по схеме «точка-точка». В предыдущем примере для этой вспомогательной сети был использован номер, позволяющий адресовать 214 узлов.
Предлагается свести избыточность к минимуму следующим образом. Половина из имеющихся адресов (215) была отведена для создания сети с адресом 129.44.0.0 и маской 255.255.128.0. Следующая порция адресов, составляющая четверть всего адресного пространства (214), была назначена для сети 129.44.64.0 с маской 255.255.192.0. Далее в пространстве адресов был «вырезан» небольшой фрагмент для создания сети, предназначенной для связывания внутреннего маршрутизатора М2 с внешним маршрутизатором Ml.
В IP-адресе такой вырожденной сети для поля номера узла как минимум должны быть отведены два двоичных разряда. Из четырех возможных комбинаций номеров узлов: 00, 01, 10 и 11 два номера имеют специальное назначение и не могут быть присвоены узлам, но оставшиеся два 10 и 01 позволяет адресовать порты маршрутизаторов. В нашем примере сеть выбрана на 8 узлов. Поле номера узла имеет 3 двоичных разряда, маска имеет вид 255.255.255.248, а номер сети равен 129.44.128.0. Если эта сеть является локальной, то на ней могут быть расположены еще четыре узла помимо двух портов маршуртизаторов.

Замечание. Глобальным связям между маршрутизаторами типа «точка-точка» не обязательно давать IP-адреса. Однако так делается для того, чтобы скрыть внутреннюю структуру сети и обращаться к ней по одному адресу входного порта маршрутизатора, в данном примере по адресу 129.44.128.1.

Таблица маршрутизации М2 содержит записи о четырех непосредственно подключенных сетях и запись о маршрутизаторе по умолчанию. Процедура поиска маршрута при использовании масок переменной длины ничем не отличается от подобной процедуры, описанной ранее для масок одинаковой длины.
Таблица маршрутизации М2
|
Номер сети |
Маска |
Адрес следующего маршрутизатора |
Адрес порта |
Расстояние |
|
129.44.0.0 |
255.255.128.0 |
129.44.0.1 |
129.44.0.1 |
Подключена |
|
129.44.128.0 |
255.255.192.0 |
129.44.128.3 |
129.44.128.3 |
Подключена |
|
129.44.192.0 |
255.255.255.248 |
129.44.192.1 |
129.44.192.1 |
Подключена |
|
129.44.224.0 |
255.255.224.0 |
129.44.224.5 |
129.44.224.5 |
Подключена |
|
0.0.0.0 |
0.0.0.0 |
129.44.192.2 |
129.44.192.1 |
|
Таблица маршрутизации М1
|
Номер сети |
Маска |
Адрес следующего маршрутизатора |
Адрес порта |
Расстояние |
|
… |
… |
… |
… |
… |
|
129.44.0.0 129.44.192.0 … |
255.255.0.0 255.255.255.248 … |
129.44.192.1 129.44.192.2 … |
129.44.192.2 129.44.192.2 … |
2 Подключена … |
Рассмотрим пример. Пусть пакет, поступивший из внешней сети на маршрутизатор Ml, имеет адрес назначения 129.44.192.5. Ниже приведен фрагмент таблицы маршрутизации маршрутизатора Ml. Первая из приведенных двух записей говорит о том, что все пакеты, адреса которых начинаются на 129.44, должны быть переданы на маршрутизатор М2. Эта запись выполняет агрегирование адресов всех подсетей, созданных на базе одной сети 129.44.0.0. Вторая строка говорит о том, что среди всех возможных подсетей сети 129.44.0.0 есть одна, 129.44.192.0, для которой пакеты можно направлять непосредственно, а не через маршрутизатор М2.
Если следовать стандартному алгоритму поиска маршрута по таблице, то сначала на адрес назначения 129.44.192.5 накладывается маска из первой строки 255.255.0.0 и получается результат 129.44.0.0, который совпадает с номером сети в этой строке. Но и при наложении на адрес 129.44.192.5 маски из второй строки 255.255.255.248 полученный результат 129.44.192.0 также совпадает с номером сети во второй строке. В таких случаях должно быть применено следующее правило: «Если адрес принадлежит нескольким подсетям в базе данных маршрутов, то продвигающий пакет маршрутизатор использует наиболее специфический маршрут, то есть выбирается адрес подсети, дающий большее совпадение разрядов».
В данном примере будет выбран второй маршрут, то есть пакет будет передан в непосредственно подключенную сеть, а не пойдет кружным путем через маршрутизатор М2. Механизм выбора самого специфического маршрута является обобщением понятия «маршрут по умолчанию». Поскольку в традиционной записи для маршрута по умолчанию 0.0.0.0 маска 0.0.0.0 имеет нулевую длину, то этот маршрут считается самым неспецифическим и используется только при отсутствии совпадений со всеми остальными записями из таблицы маршрутизации.
Замечание. В IP-пакетах при использовании механизма масок по-прежнему передается только IP-адрес назначения, а маска сети назначения не передается. Поэтому из IP-адреса пришедшего пакета невозможно выяснить, какая часть адреса относится к номеру сети, а какая – к номеру узла. Если маски во всех подсетях имеют один размер, то это не создает проблем. Если же для образования подсетей применяют маски переменной длины, то маршрутизатор должен каким-то образом узнавать, каким адресам сетей какие маски соответствуют. Для этого используются протоколы маршрутизации, переносящие между маршрутизаторами не только служебную информацию об адресах сетей, но и о масках, соответствующих этим номерам. К таким протоколам относятся протоколы RIPv2 и OSPF. Протокол RIPv1 маски не распространяет и для использования масок переменной длины не подходит.
Методы локальной пользовательской маршрутизации
Алгоритм Дейкстры
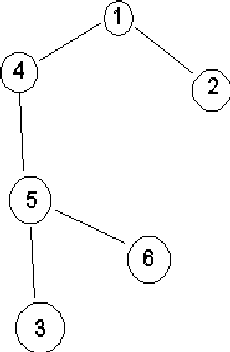
Эти методы обеспечивают оптимальный маршрут прохождения пакета между отдельной парой абонентов. Введем обозначения: D(v) – суммарная стоимость минимального пути от источника (узел с номером 1) до получателя (узел с номером v), l(i,j) – стоимость канала от узла i до узла j. Определена только для смежных узлов. Для несмежных равна . Это подход является алгоритмом Дейкстры для сетевой маршрутизации.
Шаг0. Строится множество N, содержащее номер одного узла (первого). Строится таблица: строки таблицы – итерации, столбцы – номер операции, множество N, номера узлов (начиная со второго). В строке для нулевой итерации, в столбце для узла v фиксируется значение D1(v) = l(1,v). Нижний индекс показывает номер узла, через который достигается текущее оптимальное значение. Строиться корень дерева с узлом 1.
Шаг k (k
= 1,2,3,…). В текущей строке выбираем
узел v такой, что он
не из множества N, но
является смежным с каким-либо из узлов
множества N и такой,
что значение Dp(v)
минимально. Узел v
включается во множество N.
В дереве добавляется узел с номером v
в качестве потомка узла с номером p.
Далее формируется новая строка таблицы,
делается пересчет. Для всех узлов wN
проверяем, изменилось ли стоимость
маршрута по следующему правилу:
 ,
w* – любое,
,
w* – любое,
![]() ,
если было оставлено старое значение,
,
если было оставлено старое значение,
![]() иначе.
иначе.
Алгоритм заканчивает работу, исчерпав все множество вершин.
Пример:
|
|
Nитер |
N |
2 |
3 |
4 |
5 |
6 |
|
0 |
1 |
21 |
51 |
11 |
1 |
1 |
|
|
1 |
1, 4 |
21 |
44 |
11 |
24 |
45 |
|
|
2 |
1, 4, 2 |
21 |
35 |
11 |
24 |
45 |
|
|
3 |
1, 4, 2, 5 |
21 |
35 |
11 |
24 |
45 |
|
|
4 |
1, 4, 2, 5, 3 |
21 |
35 |
11 |
24 |
45 |
|
|
5 |
1, 4, 2, 5, 3, 6 |
|
|
|
|
|

|
Получатель |
Смежный |
|
2 |
2 |
|
3 |
4 |
|
4 |
4 |
|
5 |
4 |
|
6 |
4 |
|
|
Получено решение (маршрутная таблица) для узла с номером 1. Эта таблица расчитывается для каждого узла отдельно. Алгоритм может быть реализован самостоятельно каждым узлом. Недостатком является необходимость информации о стоимости всех каналов сети. |
Применение процессов для обеспечения параллельной работы сервера

/* Создаем ведущий сокет, привязываем его к общепринятому порту и переводим в пассивный режим */
signal(SIGCHLD,reaper);
while(1) {
ssock = accept(msock,(struct sockaddr *)&fsin,&len);
if(ssock <0){ /* Сообщение об ошибке */ }
switch(fork()) {
case(0):
close(msock);
/* Обработка поступившго запроса ведомым процессом */
close(ssock);
exit(0);
default:
close(ssock);
/* Ведущий процесс */
break;
case -1:
/* Сообщение об ошибке */
}
}
void reaper(int sig)
{
int status;
while(wait3(&status,WNOHANG,(struct rusage *)0)>= 0);
}
Ведущий процесс сервера начинает свое выполнение в главной процедуре. При каждом проходе по циклу ведущий сервер вызывает функцию accept для перехода в состояние ожидания запроса на установление соединения от клиента. После получения запроса создается сокет для новооединения и вызов функции accept возвращает дескриптор этого сокета. Далее ведущий процесс вызывает функцию fork, чтобы разделиться на два процесса. Затем он закрывает сокет, который был создан для обслуживания нового соединения, и продолжает выполнение бесконечного цикла.
Замечание: первоначальный, и новые процессы имеют доступ к открытым сокетам после вызова функции fork() и они оба должны закрыть эти сокеты, после чего система освобождает связанный с ним ресуры.
Завершившийся процесс остается в виде так наваемого процесса-зомби до тех пор, пока родительским процессом не будет выполней системный вызов wait3. Для полного завершения дочернего процесса (т.е. уничтожения процесса-зомби) необходимо пехватывается сигнал завершения дочернего процесса. Операционной системе дается указание, что для ведущего процесса сервера при получении каждого сигнала о завершении работы дочернего процесса (сигнал SIGCHLD) должна быть выполнена функция reaper, в виде следующего вызова: signal(SIGCHLD, reaper);
Функция reaper вызывает системную функцию wait3, которая остается заблокированной до тех пор, пока не произойдет завершение работы одного или нескольких дочерних процессов. Эта функция возвращает значение структуры status, которую можно проанализировать для получения дополнительной информации о завершившемся процессе. Поскольку данная программа вызывает функцию wait3 при получении сигнала SIGCHLD, вызов этой функции всегда происходит только после завершения работы дочернего процесса. Для предотвращения возникновения в сервере тупиковой ситуации в случае ошибочного вызова в программе используется параметр WNOHANG, который указыает, что функция wait3 не должна блокироваться в ожидании завершения какого-либо процесса.