

Лекция 1
Использование масок переменной длины
В предыдущем примере использования масок все подсети имеют одинаковую длину поля номера сети - 18 двоичных разрядов, и, следовательно, для нумерации узлов в каждой из них отводится по 14 разрядов. Все сети являются очень большими и имеют одинаковый размер. Однако более эффективным явиляется разбиение сети на подсети разного размера. Например, большое число узлов, подходящее для пользовательской подсети, является избыточным для подсети, которая связывает два маршрутизатора по схеме «точка-точка». В предыдущем примере для этой вспомогательной сети был использован номер, позволяющий адресовать 214 узлов.
Предлагается свести избыточность к минимуму следующим образом. Половина из имеющихся адресов (215) была отведена для создания сети с адресом 129.44.0.0 и маской 255.255.128.0. Следующая порция адресов, составляющая четверть всего адресного пространства (214), была назначена для сети 129.44.64.0 с маской 255.255.192.0. Далее в пространстве адресов был «вырезан» небольшой фрагмент для создания сети, предназначенной для связывания внутреннего маршрутизатора М2 с внешним маршрутизатором Ml.
В IP-адресе такой вырожденной сети для поля номера узла как минимум должны быть отведены два двоичных разряда. Из четырех возможных комбинаций номеров узлов: 00, 01, 10 и 11 два номера имеют специальное назначение и не могут быть присвоены узлам, но оставшиеся два 10 и 01 позволяет адресовать порты маршрутизаторов. В нашем примере сеть выбрана на 8 узлов. Поле номера узла имеет 3 двоичных разряда, маска имеет вид 255.255.255.248, а номер сети равен 129.44.128.0. Если эта сеть является локальной, то на ней могут быть расположены еще четыре узла помимо двух портов маршуртизаторов.

Замечание. Глобальным связям между маршрутизаторами типа «точка-точка» не обязательно давать IP-адреса. Однако так делается для того, чтобы скрыть внутреннюю структуру сети и обращаться к ней по одному адресу входного порта маршрутизатора, в данном примере по адресу 129.44.128.1.
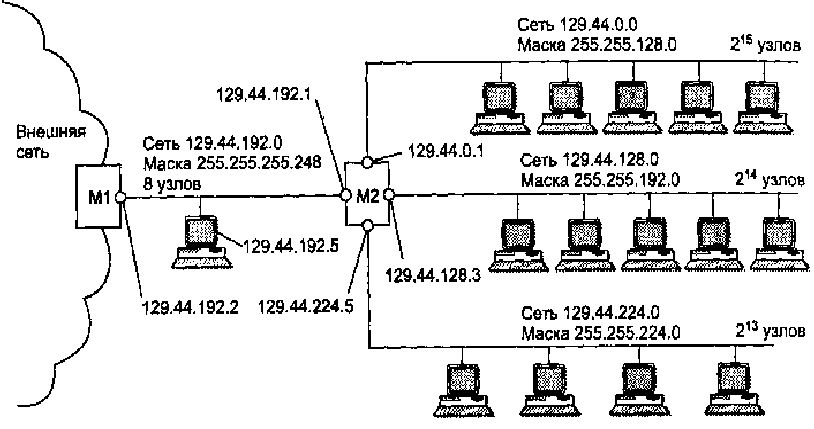
Таблица маршрутизации М2 содержит записи о четырех непосредственно подключенных сетях и запись о маршрутизаторе по умолчанию. Процедура поиска маршрута при использовании масок переменной длины ничем не отличается от подобной процедуры, описанной ранее для масок одинаковой длины.
Таблица маршрутизации М2
|
Номер сети |
Маска |
Адрес следующего маршрутизатора |
Адрес порта |
Расстояние |
|
129.44.0.0 |
255.255.128.0 |
129.44.0.1 |
129.44.0.1 |
Подключена |
|
129.44.128.0 |
255.255.192.0 |
129.44.128.3 |
129.44.128.3 |
Подключена |
|
129.44.192.0 |
255.255.255.248 |
129.44.192.1 |
129.44.192.1 |
Подключена |
|
129.44.224.0 |
255.255.224.0 |
129.44.224.5 |
129.44.224.5 |
Подключена |
|
0.0.0.0 |
0.0.0.0 |
129.44.192.2 |
129.44.192.1 |
|
Таблица маршрутизации М1
|
Номер сети |
Маска |
Адрес следующего маршрутизатора |
Адрес порта |
Расстояние |
|
… |
… |
… |
… |
… |
|
129.44.0.0 129.44.192.0 … |
255.255.0.0 255.255.255.248 … |
129.44.192.1 129.44.192.2 … |
129.44.192.2 129.44.192.2 … |
2 Подключена … |
Рассмотрим пример. Пусть пакет, поступивший из внешней сети на маршрутизатор Ml, имеет адрес назначения 129.44.192.5. Ниже приведен фрагмент таблицы маршрутизации маршрутизатора Ml. Первая из приведенных двух записей говорит о том, что все пакеты, адреса которых начинаются на 129.44, должны быть переданы на маршрутизатор М2. Эта запись выполняет агрегирование адресов всех подсетей, созданных на базе одной сети 129.44.0.0. Вторая строка говорит о том, что среди всех возможных подсетей сети 129.44.0.0 есть одна, 129.44.192.0, для которой пакеты можно направлять непосредственно, а не через маршрутизатор М2.
Если следовать стандартному алгоритму поиска маршрута по таблице, то сначала на адрес назначения 129.44.192.5 накладывается маска из первой строки 255.255.0.0 и получается результат 129.44.0.0, который совпадает с номером сети в этой строке. Но и при наложении на адрес 129.44.192.5 маски из второй строки 255.255.255.248 полученный результат 129.44.192.0 также совпадает с номером сети во второй строке. В таких случаях должно быть применено следующее правило: «Если адрес принадлежит нескольким подсетям в базе данных маршрутов, то продвигающий пакет маршрутизатор использует наиболее специфический маршрут, то есть выбирается адрес подсети, дающий большее совпадение разрядов».
В данном примере будет выбран второй маршрут, то есть пакет будет передан в непосредственно подключенную сеть, а не пойдет кружным путем через маршрутизатор М2. Механизм выбора самого специфического маршрута является обобщением понятия «маршрут по умолчанию». Поскольку в традиционной записи для маршрута по умолчанию 0.0.0.0 маска 0.0.0.0 имеет нулевую длину, то этот маршрут считается самым неспецифическим и используется только при отсутствии совпадений со всеми остальными записями из таблицы маршрутизации.
Замечание. В IP-пакетах при использовании механизма масок по-прежнему передается только IP-адрес назначения, а маска сети назначения не передается. Поэтому из IP-адреса пришедшего пакета невозможно выяснить, какая часть адреса относится к номеру сети, а какая – к номеру узла. Если маски во всех подсетях имеют один размер, то это не создает проблем. Если же для образования подсетей применяют маски переменной длины, то маршрутизатор должен каким-то образом узнавать, каким адресам сетей какие маски соответствуют. Для этого используются протоколы маршрутизации, переносящие между маршрутизаторами не только служебную информацию об адресах сетей, но и о масках, соответствующих этим номерам. К таким протоколам относятся протоколы RIPv2 и OSPF. Протокол RIPv1 маски не распространяет и для использования масок переменной длины не подходит.
Методы локальной пользовательской маршрутизации Алгоритм Дейкстры
Эти методы обеспечивают оптимальный маршрут прохождения пакета между отдельной парой абонентов. Введем обозначения: D(v) – суммарная стоимость минимального пути от источника (узел с номером 1) до получателя (узел с номером v), l(i,j) – стоимость канала от узла i до узла j. Определена только для смежных узлов. Для несмежных равна . Это подход является алгоритмом Дейкстры для сетевой маршрутизации.
Шаг0. Строится множество N, содержащее номер одного узла (первого). Строится таблица: строки таблицы – итерации, столбцы – номер операции, множество N, номера узлов (начиная со второго). В строке для нулевой итерации, в столбце для узла v фиксируется значение D1(v) = l(1,v). Нижний индекс показывает номер узла, через который достигается текущее оптимальное значение. Строиться корень дерева с узлом 1.
Шаг
k
(k
= 1,2,3,…). В
текущей строке выбираем узел v
такой, что он не из множества N,
но является смежным с каким-либо из
узлов множества N
и такой, что значение Dp(v)
минимально. Узел v
включается во множество N.
В дереве добавляется узел с номером v
в качестве потомка узла с номером p.
Далее формируется новая строка таблицы,
делается пересчет. Для всех узлов wN
проверяем, изменилось ли стоимость
маршрута по следующему правилу:
 ,
w*
– любое,
,
w*
– любое,
![]() ,
если было оставлено старое значение,
,
если было оставлено старое значение,![]() иначе.
иначе.
Алгоритм заканчивает работу, исчерпав все множество вершин.
Пример:
|
|
Nитер |
N |
2 |
3 |
4 |
5 |
6 |
|
0 |
1 |
21 |
51 |
11 |
1 |
1 | |
|
1 |
1, 4 |
21 |
44 |
11 |
24 |
45 | |
|
2 |
1, 4, 2 |
21 |
35 |
11 |
24 |
45 | |
|
3 |
1, 4, 2, 5 |
21 |
35 |
11 |
24 |
45 | |
|
4 |
1, 4, 2, 5, 3 |
21 |
35 |
11 |
24 |
45 | |
|
5 |
1, 4, 2, 5, 3, 6 |
|
|
|
|
|

|
Получатель |
Смежный |
|
2 |
2 |
|
3 |
4 |
|
4 |
4 |
|
5 |
4 |
|
6 |
4 |
|
|
Получено решение (маршрутная таблица) для узла с номером 1. Эта таблица расчитывается для каждого узла отдельно. Алгоритм может быть реализован самостоятельно каждым узлом. Недостатком является необходимость информации о стоимости всех каналов сети. |

Применение процессов для обеспечения параллельной работы сервера

/* Создаем ведущий сокет, привязываем его к общепринятому порту и переводим в пассивный режим */
signal(SIGCHLD,reaper);
while(1) {
ssock = accept(msock,(struct sockaddr *)&fsin,&len);
if(ssock <0){ /* Сообщение об ошибке */ }
switch(fork()) {
case(0):
close(msock);
/* Обработка поступившго запроса ведомым процессом */
close(ssock);
exit(0);
default:
close(ssock);
/* Ведущий процесс */
break;
case -1:
/* Сообщение об ошибке */
}
}
void reaper(int sig)
{
int status;
while(wait3(&status,WNOHANG,(struct rusage *)0)>= 0);
}
Ведущий процесс сервера начинает свое выполнение в главной процедуре. При каждом проходе по циклу ведущий сервер вызывает функцию accept для перехода в состояние ожидания запроса на установление соединения от клиента. После получения запроса создается сокет для новооединения и вызов функции accept возвращает дескриптор этого сокета. Далее ведущий процесс вызывает функцию fork, чтобы разделиться на два процесса. Затем он закрывает сокет, который был создан для обслуживания нового соединения, и продолжает выполнение бесконечного цикла.
Замечание: первоначальный, и новые процессы имеют доступ к открытым сокетам после вызова функции fork() и они оба должны закрыть эти сокеты, после чего система освобождает связанный с ним ресуры.
Завершившийся процесс остается в виде так наваемого процесса-зомби до тех пор, пока родительским процессом не будет выполней системный вызов wait3. Для полного завершения дочернего процесса (т.е. уничтожения процесса-зомби) необходимо пехватывается сигнал завершения дочернего процесса. Операционной системе дается указание, что для ведущего процесса сервера при получении каждого сигнала о завершении работы дочернего процесса (сигнал SIGCHLD) должна быть выполнена функция reaper, в виде следующего вызова: signal(SIGCHLD, reaper);
Функция reaper вызывает системную функцию wait3, которая остается заблокированной до тех пор, пока не произойдет завершение работы одного или нескольких дочерних процессов. Эта функция возвращает значение структуры status, которую можно проанализировать для получения дополнительной информации о завершившемся процессе. Поскольку данная программа вызывает функцию wait3 при получении сигнала SIGCHLD, вызов этой функции всегда происходит только после завершения работы дочернего процесса. Для предотвращения возникновения в сервере тупиковой ситуации в случае ошибочного вызова в программе используется параметр WNOHANG, который указывает, что функция wait3 не должна блокироваться в ожидании завершения какого-либо процесса.
Лекция 2
Применение потоков для обеспечения параллельной работы сервера
Поток выполнения представляет собой один из принципов организации отдельных вычислений, а один процесс может содержать от одного и более потоков. Новый поток может быть создан в любое время путем вызова функции pthread_create. Операционная система ограничивает максимально допустимое количество параллельных потоков, также как и максимальное количество параллельных процессов. Все потоки процесса разделяют единый набор глобальных переменных и единый набор дескрипторов файлов.
Многопотоковые процессы обладают двумя основными преимуществами по сравнению с однопотоковыми процессами: более высокая эффективность и разделяемая память. Повышение эффективности связано с уменьшением издержек на переключение контекста. Переключением контекста – это действия, выполняемые операционной системой при передаче ресурсов процессора от одного потока выполнения к другому. При переключении с одного потока на другой операционная система должна сохранить в памяти состояние предыдущего потока (например, значения регистров) и восстановить состояние следующего потока. Потоки в одном и том же процессе разделяют значительную часть информации о состоянии процесса, поэтому операционной системе приходится выполнять меньший объем работы по сохранению и восстановлению состояния. Вследствие этого переключение с одного потока на другой в одном и том же процессе происходит быстрее по сравнению с переключением между двумя потоками в разных процессах.
Второе преимущество потоков (разделяемая память), является более важным, чем повышение эффективности. Потоки упрощают разработку параллельных серверов, в которых все копии сервера должны взаимодействовать друг с другом или обращаться к разделяемым элементам данных. В частности, поскольку ведомые потоки в сервере совместно используют глобальную память.
Одним из недостатков потоков является то, что они имеют общее состояние процесса, поэтому действия, выполненные одним потоком, могут повлиять на другие потоки в том же процессе. Например, если два потока попытаются одновременно обратиться к одной и той же переменной, они могут помешать друг другу. API-интерфейс потоков предоставляет функции, которые могут использоваться потоками для координации работы.
Замечание: Многие библиотечные функции, возвращающие указатели на статические элементы данных, не являются безопасными с точки зрения потоков. Например, если два потока вызовут функцию gethostbyname одновременно, то оба могут обратиться к одной и той же области памяти, что вызовет конфликт. Поэтому если несколько потоков вызывают определенную библиотечную функцию, они должны координировать свою работу для обеспечения того, чтобы в любое время ее вызов выполнял только один поток.
Еще один недостаток связан с отсутствием надежности. Если одна из параллельно работающих копий однопотокового сервера вызовет серьезную ошибку (например, в ней будет выполнена ссылка на недопустимую область памяти), то операционная система завершит только тот процесс, который вызвал ошибку. С другой стороны, если серьезная ошибка будет вызвана одним из потоков многопотокового сервера, то операционная система завершит весь процесс (т.е. все потоки этого процесса).
Для завершения работы потока могут использоваться два способа: возврат из процедуры, с которой началось выполнение потока, либо вызов функция pthread_exit.
Координация и синхронизация работы потоков
В системе Linux предусмотрено три механизма синхронизации: мьютексы, семафоры и условные переменные.
1) В потоках мьютексы используются для обеспечения взаимно исключающего доступа к разделяемому элементу данных. Мьютекс инициализируется динамически путем вызова функции pthread_mutex_init. Селдует предусматривать применение отдельного мьютекса для каждого элемента данных, который должен быть защищен. Перед использованием элемента данных поток вызывает функцию pthread_mutex_lock и функцию pthread_mutex_unlock по окончании его использования. Эти два вызова позволяют одновременно обращаться к элементу данных только одному потоку. Первый поток, вызвавший функцию pthread_mutex_lock с конкретным мьютексом, продолжает свою работу без задержки. Однако система блокирует каждый следующий поток, вызывающий функцию pthread_mutex_lock с тем же мьютексом. Когда вызывается функция pthread_mutex_unlock операционная система разблокирует один из ожидающих освобождения этого мьютекса потоков.
2) Семафор представляет собой механизм синхронизации, обобщающий мьютекс и применяемый в том случае, если доступно N копий ресурса. Семафор инициализируется динамически. Для инициализации семафора применяется функция sem_init; в одном из ее параметров должен быть указан начальный счетчик N. Сразу после инициализации семафора поток вызывает функцию sem_wait до начала использования одной копии ресурса, а возвращая копию для использования другими потоками, вызывает функцию sem_post. Функция sem_wait может быть беспрепятственно вызвана потоками, число которых составляет N; после ее вызова каждый из них продолжает свое выполнение. Однако если к семафору попытаются обратиться дополнительные потоки, они будут заблокированы и будут заблокированными до тех пор, пока один из выполняющихся потоков не вызовет функцию sem_post.
3) Условные переменные требуются только в ситуации, при которой одновременно выполняются следующие два условия: ряд потоков использует мьютекс для получения взаимно исключающего доступа к некоторому ресурсу и сразу после приобретения ресурса поток должен перейти к ожиданию возникновения определенного события.
Без применения условных переменных в программах, которые сталкиваются описанной выше ситуацией, приходится использовать своего рода активное задание, в котором поток повторно приобретает мьютекс, проверяет условие, а затем освобождает мьютекс. Перед блокировкой на условной временной поток приобретает мьютекс. При вызове потоком функции pthread_cond_wait для перехода в состояние ожидания изменения условной переменной в потоке должна быть указана и условная переменная, изменения которой он ожидает, и захваченный им мьютекс. Операционная система освобождает мьютекс, захваченный потоком, и одновременно с этим блокирует поток в ожидании изменения условной переменной.
После выполнения функции pthread_cond_wait поток блокируется на указаной условной переменной до тех пор, пока какой-то другой поток не передаст сигнал об изменении этой переменной. Для передачи сигнала об изменении условной переменной могут применяться два способа; различие между ними определяется тем, что многочисленные ожидающие потоки могут обрабатываться по разному. Функция pthread_cond_signal позволяет продолжить работу только одному потоку, даже если сигнала об изменении состояния переменной ожидают несколько потоков, а функция pthread_cond_broadcast позволяет продолжить работу всем потокам, заблокированным на этой переменной. Разрешая одному потоку продолжить работу, операционная система одновременно разблокирует этот поток и позволяет ему снова приобрести мьютекс, которым он обладал, прежде чем заблокироваться на условной переменной, об изменении состояния которой получен сигнал. Ожидание изменения условной переменной равносильно отказу на время от мьютекса, а затем автоматическому повторному приобретению этого мьютекса после поступления сигнала об изменении условной переменной. В результате блокировка потока на условной переменной не исключает для других потоков возможности пройти через критический участок, поскольку мьютекс могут приобрести и другие потоки.
Пример сервера, реализованного с применением потоков
struct {
pthread_mutex_t st_mutex;
/* Разделяемая переменная */
} GLOBAL;
int main() {
pthread_t th;
pthread_attr_t ta;
/* Создаем ведущий сокет, привязываем его к общепринятому порту и переводим в пассивный режим */
pthread_attr_init(&ta);
pthread_attr_setdetachstate(&ta, PTHREAD_CREATE_DETACHED);
pthread_mutex_init(&GLOBAL.st_mutex,0);
while (1) {
ssock = accept(msock, (struct sockaddr *)&fsin, &len);
if (ssock <0) {/* ошибка */}
if (pthread_create(&th, &ta, (void * (*)(void *))handler, (void *)ssock) <0) {/* ошибка */}
}
int handler(int ssock)
{
pthread_mutex_lock(&GLOBAL.st_mutex);
/* выполнение операций с разделяемыми переменными */
pthread_mutex_unlock(&GLOBAL.st mutex);
return 0;
}
Проблема тупиковых ситуаций в работе сервера
Рассмотрим последовательный сервер с установлением логического соединения. Предположим, что клиентское приложение выполняет недопустимые действия. В простейшем случае предположим, что приложение формирует соединение с сервером, но не присылает никаких запросов. Сервер принимает запрос на установление соединения и вызывает функцию recv или read для получения ожидаемого запроса. Серверная программа заблокируется в этом системном вызове, ожидая запроса, который никогда не поступит.
Тупиковая ситуация в сервере может возникнуть, если клиенты действуют неправильно, не считывая отправленные сервером ответы. Например, предположим, что клиент установил соединение с сервером, передал ему ряд запросов, но не прочитал ни одного ответа. Сервер принял один за другим запросы, сформировал ответы и отправил их клиенту. Применяемое на сервере программное обеспечение протокола TCP выполнило передачу нескольких первых байтов через соединение с клиентом. В этот момент вступает в действие механизм управления потоком данных TCP. После заполнения буфера приема данных клиента протокол TCP прекращает передачу данных. Серверная прикладная программа продолжает формировать ответы. Локальный выходной буфер TCP, применяемый программным обеспечением этого протокола для хранения исходящих данных соединения, заполняется, а сервер блокируется.
Тупиковая ситуация возникает в связи с тем, что при отсутствии возможности выполнения ОС системного вызова вызывающая программа блокируется. В частности, при вызове функции send или write вызывающая программа блокируется, если программное обеспечение TCP не имеет свободного локального буферного пространства для размещения передаваемых данных, а при вызове функции recv или read вызывающая программа блокируется до тех пор, пока программное обеспечение TCP не получит данные. В параллельных серверах блокируется только один ведомый поток, связанный с конкретным клиентом, если этот клиент окажется не в состоянии отправлять запросы или читать ответы. Однако в реализациях, основанных на использовании одного потока выполнения, блокируется весь сервер. После возникновения блокировки сервер теряет способность поддерживать остальные соединения. Это означает, что любой сервер, в котором используется только один поток, может оказаться в тупиковой ситуации.
Лекция 3
Однопотоковые параллельные серверы
В приложениях клиент/сервер, характеризующихся тем, что затраты на опечение ввода/вывода превышают затраты на подготовку ответа на запрос, в сервере может использоваться асинхронный ввод/вывод для организации псевдопараллельной работы клиентов. Необходимо предусмотреть, чтобы единственный поток выполнения в сервере
держал открытыми соединения с несколькими клиентами и обеспечивал обслуживание сервером того соединения, через которое в определенный момент поступают данные. Сам факт поступления данных используется для активизации обработки данных сервером.
Допустим, что один поток сервера обслуживает соединения TCP одновременно с несколькими клиентами. Поток блокируется, ожидая поступления данных. Сразу после поступления данных через любое соединение поток активизируется, обрабатывает запрос и передает ответ. Затем он снова блокируется, ожидая поступления данных из другого соединения. При условии, что процессор работает достаточно быстро для того, чтобы выдержать нагрузку, возложенную на сервер, однопотоковая версия сможет обслуживать соединения с таким же успехом, как и версия с несколькими потоками. Однопотоковая реализация не требует переключения между контекстами потоков или процессов, поэтому она может дан выдержать более высокую нагрузку по сравнению с реализацией, в которой используются несколько потоков или процессов.
В основе разработки программы однопотокового, параллельного сервера лежит использование асинхронного ввода/вывода, организованного с помощь системного вызова select. Сервер создает сокет для каждого соединения, которое он должен поддерживать, а затем вызывает функцию select, которая ожидает поступления данных через каждое из них. Функция select может ожидать поступления запросов на выполнение операций ввода/вывода через все возможные сокеты, в том числе и одновременно ожидать поступления новых запросов на установление соединения.

Один единственный поток остается привязанным к общепринятому порту, через который он должен принимать запросы на установление соединения Каждый из ведомых сокетов в наборе соответствует соединению, для которого ведомый поток должен обрабатывать запросы. Сервер передает набор дескрипторов сокетов функции select в качестве параметра и ожидает активизации любого из них. После возврата управления функция select передает в вызывающий oпeратор битовую маску, которая указывает, какой из дескрипторов в наборе готов к работе. В сервере для принятия решения о том, с каким из дескрипторов нужно продолжить работу, используется порядок их активизации.
Для определения того, какие операции (ведущего или ведомого потока) должны быть выполнены для данного дескриптора, в однопотоковом сервере используется сам дескриптор. Если к работе готов дескриптор, соответствующий ведущему сокету, сервер выполняет для него такие же операции, какие выполнил бы ведущий поток: он вызывает функцию accept с этим сокетом для получения нового соединения. Если же к работе готов дескриптор, соответствующий ведомому сокету, сервер выполняет операцию ведомого потока: вызывает функцию read для получения запроса, а затем отвечает на этот запрос.
Пример однопотокового сервера
int msock; /* Ведущий сокет сервера */
fd_set rfds; /* Набор дескрипторов, готовых к чтению */
fd_set afds; /* Набор активных дескрипторов */
int fd, nfds, ssock;
/* инициализация пассивного сокета msock*/
nfds = getdtablesize();
FD_ZERO(&afds);
FD_SET(msock, &afds);
while (1) {
memcpy(&rfds, &afds, sizeof(rfds));
if (select(nfds, &rfds, (fd_set *)0, (fd_set *)0, (struct timeval *)0) <0) { /* ошибка */}
if (FD_ISSET(msock, &rfds)) {
alen = sizeof(fsin);
ssock = accept(msock, (struct sockaddr *)&fsin, &alen); if (ssock <0) {/* ошибка */}
FD_SET(ssock, &afds);
}
for (fd=0; fd<nfds; fd++)
if (fd != msock && FD_ISSET(fd, &rfds))
if (handler(fd) == 0) { /* число полученных байт */
close(fd);
FD_CLR(fd, &afds);
}
}
Выполнение потока этого сервера, как и выполнение ведущего потока сервера в параллельной реализации, начинается с открытия пассивного сокета в общепринятый порт. Используется системная функция getdtablesize для определения максимального числа дескрипторов, а затем применяются макрокоманды FD_ZERO и FD_SET для создания битового вектора, соответствующего дескрипторам сокетов, которые должны контролироваться функцией select. Затем сервер входит в бесконечный цикл, в котором он вызывает функцию select для ожидания готовности к работе одного или нескольких дескрипторов. Если готов дескриптор ведущего сокета, сервер вызывает функцию accept для получения нового соединения. Он добавляет дескриптор нового соединения к управляемому им набору и снова переходит в состояние ожидания активизации следующих дескрипторов. Если же готов дескриптор ведомого сокета, сервер вызывает процедуру handler для обработки клиентского запроса. Если один из дескрипторов ведомого сокета сообщает о получении признака конца файла (число полученных байт равно 0), сервер закрывает дескриптор и использует макрокоманду FD_CLR для удаления его из набора дескрипторов, используемых функцией select.
ции inetd.
Мультипротокольный сервер
Недостаток использования отдельных серверов для каждого протокола связан с неэффективным использованием ресурсов. Масштабы этой проблемы становятся очевидными, если учесть, что стандартах TCP/IP определены десятки служб.
Мультипротокольный сервер состоит из одного потока выполнения, в котором используется асинхронный ввод/вывод для обслуживания соединений по протоколу UDP или TCP. В этом сервере первоначально открываются два сокета; в одном применяется транспортный протокол UDP, а в другом – TCP. Затем в сервере используются средства асинхронного ввода/вывода для по
лучения информации о готовности к работе одного из сокетов. Если готов к работе сокет TCP, это означает, что от одного из клиентов поступил запрос на установление соединения TCP. Сервер вызывает функцию accept для получения нового соединения, а затем обменивается данными с клиентом через это соединение. Если же готов сокет UDP, это означает, что один из клиентов передал запрос в форме дейтаграммы UDP. В сервере для чтения запроса и регистрации адреса оконечной точки отправителя используется функция recvfrom. После формирования ответа сервер отправляет этому клиенту ответ с помощью функции sendto.
Для приема запросов, поступающих по нескольким транспортным протоколам, применяется один поток выполнения, в котором может быть в любое время открыто не более трех сокетов: один для запросов UDP, другой – для запросов на установление соединения TCP, и еще один (временный) сокет – для обслуживания отдельного соединения TCP.

Пример мультипротокольного сервера
int tsock; /* Ведущий сокет TCP */
int usock; /* Сокет UDP */
int ssock; /* Ведомый сокет TCP */
fd set rfds; /* Дескрипторы, готовые к чтению */
/* инициализация сокетов tsock и usock */
nfds = MAX(tsock, usock) +1; /* Длина битовой маски для набора дескрипторов */
FD_ZERO(&rfds);
while (1) {
FD_SET(tsock, &rfds); FD_SET(usock, &rfds);
if (select(nfds, &rfds, (fd_set *)0, (fd_set *)0, (struct timeval *)0) <0) {/* ошибка */}
if (FD_ISSET(tsock, &rfds)) {
len=sizeof(fsin);
ssock = accept(tsock, (struct sockaddr *)&fsin,&len); if(ssock <0){/* ошибка */}
handler(buf);
if(send(ssock,buf, sizeof(buf))<0) {/* ошибка */}
close(ssock);
}
if (FD_ISSET(usock, &rfds)) {
len = sizeof(fsin);
if (recvfrom(usock, buf, sizeof(buf), 0, (struct sockaddr *)&fsin, &len) <0) {/*ошибка*/}
handler(buf);
if(sendto(usock, buf, strlen(buf), 0, (struct sockaddr *)&fsin, sizeof(fsin))<0)
{/*ошибка*/}
}
}
После создания ведущих сокетов сервер выполняет подготовку к использованию ФУНКЦИИ select для перехода в состояние ожидания готовности одного или обоих из этих сокетов к вводу/выводу. Переменной nfds присваивается значение индекса битовой маски дескриптора старшего из этих двух сокетов, и битовая маска очищается, после чего сервер входит в бесконечный цикл. При каждом проходе по циклу используется макрокоманда FD_SET для построения битовой маски с битами, установленными для дескрипторов, соответствующих двум ведущим сокетам. Затем вызывается функция select для перехода в состояние ожидания активизации ввода через любой из них. Возврат управления из функции select свидетельствует о том, что готов один или оба ведущих сокета. В сервере для проверки сокета TCP, а затем сокета UDP используется макрокоманда FD_ISSET. Сервер должен проверить оба сокета, поскольку дейтаграмма UDP может поступить одновременно с запросом на установление соединения TCP, и в этом случае должны быть готовы оба сокета.
Если готов сокет TCP, это означает, что какой-то клиент инициализировал запрос на установление соединения. Сервер вызывает функцию accept для установления соединения. Эта функция возвращает дескриптор нового, временного сокета, применяемого только для обмена данными через это новое соединение. Сервер вызывает процедуру handler для формирования ответа и передает ответ через новое соединение, а затем закрывает его.
Если готов сокет UDP, это означает, что какой-то клиент прислал дейтаграмму. Сервер вызывает функцию recvfrom для чтения входящей дейтаграммы и регистрации адреса оконечной точки клиента. В нем также используется процедура handler для формирования ответа затем вызывается функция sendto для передачи его клиенту.
Замечание1: Сервер, рассматриваемый в приведенном примере, иллюстрирует важный принцип. Существует единственная разделяемая процедура (handler), которая отвечает на запросы к данной сетевой службе, и она используется независимо от того, по какому протоколу (TCP или UDP) получены эти запросы. В данном примере разделяемый код занимает несколько строк, однако в большинстве применяемых на практике серверов код, необходимый для формирования ответа, может занимать сотни или тысячи строк. Размещение всего разделяемого кода в одном месте позволяет упростить сопровождение и обеспечить идентичность службы, предоставляемой по обоим транспортным протоколам.
Замечание2: Как и в однопротокольном сервере, в рассматриваемом примере с мультипротокольным сервером используется последовательный метод обработки запросов. Последовательная реализация может оказаться неприемлемой для создания служб, которые требуют большего объема вычислений при обработке каждого запроса. В подобных случаях мультипротокольный проект может быть расширен в целях обеспечения параллельной обработки запросов. В простейшем случае мультипротокольный сервер может создавать новый поток или процесс для одновременного обслуживания каждого из соединений TCP, в то время как обработка запросов UDP будет осуществляться последовательно. Мультипротокольный сервер может быть также расширен путем применения реализации, описанной в предыдущем пункте. Такая реализация предусматривает псевдопараллельную обработку запросов, поступающих через несколько соединений TCP или через сокет UDP.