

1.3.2. Десезонализация данных при расчете тренда
Ш
В
данном примере использованы следующие
функции: I. 1. В
колонке «Десезонализированный объём
продаж, тыс. шт. A-S=T+E» -
функция=Xi/Yi,
гдеXi-
адрес ячейки, содержащей соответствующее
значение в колонке «Объём продаж, тыс.
шт.», аYi- адрес ячейки, содержащей соответствующее
значение в колонке «Сезонная компонента». II. 2. Остальные
данные копируются из таблиц, приведённых
в предыдущих файлах.
аг 2 состоит в
десезонализации исходных данных. Она
заключается в вычитании соответствующих
значений сезонной компоненты из
фактических значений данных за каждый
квартал, т.е. A
– S
= T
+ E,
что показано ниже (файл Пример
1.4.xls).
Новые оценки значений тренда, которые еще содержат ошибку, можно использовать для построения модели основного тренда. Если нанести эти значения на исходную диаграмму, можно сделать вывод о существовании явного линейного тренда.
Уравнение линии тренда имеет вид:
T = a + b х – номер квартала,
где a и b характеризуют точку пересечения с осью ординат и наклон линии тренда. Для определения параметров прямой, наилучшим образом аппроксимирующей тренд, можно использовать метод наименьших квадратов. Таким образом, как мы знаем из предыдущей главы о линейной регрессии, уравнения для расчета параметров a и b будут иметь вид:
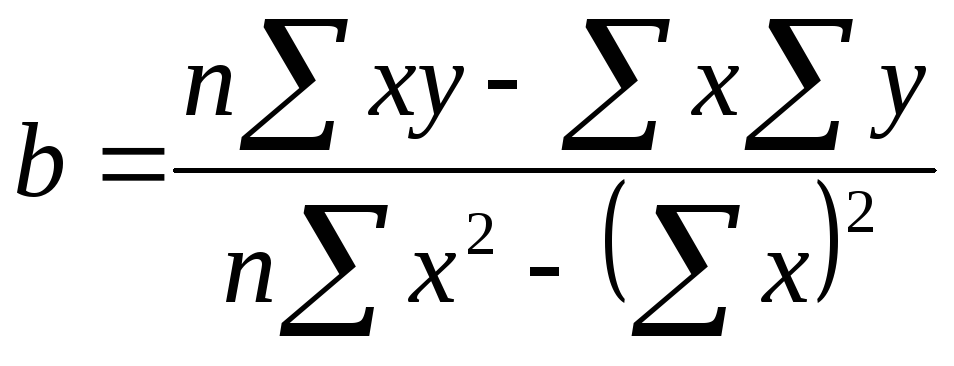 ,
,
![]() ,
,
где x – порядковый номер квартала, y – значение (T + E) в предыдущей таблице. С помощью калькулятора подсчитаем:
x = 91, x2 = 819, y = 4158,7, xy = 32747,1, n = 13.
Подставим найденные значения в соответствующие формулы, получим:
b = 19,978, a = 180,046
Следовательно, уравнение модели тренда имеет следующий вид:
Трендовое значение объема продаж, тыс. шт. = 180,0 + 20,0 х номер квартала
1.3.3. Расчет ошибок
Шаг 3 нашего алгоритма, предшествующий составлению прогнозов, состоит в расчете ошибок или остатка. Наша модель имеет следующий вид:
A = T + S + E
Значение S было найдено в файле Пример 1.1.xls, а значение T – в файле Пример 1.3.xls. Вычитая каждое это значение из фактических объемов продаж, получим значения ошибок.
П
В
данном примере использованы следующие
функции: I. 1. В
колонке «Ошибка, тыс. шт. A-S-T=E»
- функция=Xi-Yi-Zi,
гдеXi-
адрес ячейки, содержащей соответствующее
значение в колонке «Объём продаж, тыс.
шт.»,Yi- адрес ячейки, содержащей соответствующее
значение в колонке «Сезонная компонента»,
аZi-
адрес ячейки, содержащей соответствующее
значение в колонке «Трендовое значение». II. 2. Остальные
данные копируются из таблиц, приведённых
в предыдущих файлах
оследний столбец таблицы (файлПример 1.5.xls)
можно использовать в шаге 4 при расчете среднего абсолютного отклонения (MAD) или средней квадратической ошибки (MSE):
![]() ,
,
![]() .
.
В нашем случае ошибки достаточно малы и составляют от 1 до 2%. Тенденция, выявленная по фактическим данным, достаточно устойчивая и позволяет получить хорошие краткосрочные прогнозы.