

Множественный регрессионный анализ (эконометрическая модель в виде одного регрессионного уравнения)
Парная регрессия может дать хороший результат при моделировании, если влиянием других факторов, воздействующих на объект исследования, можно пренебречь. В экономике (в отличие от естественных наук) невозможно контролировать поведение большинства экономических факторов. Однако влияние данных факторов можно учитывать в модели. То есть можно построить модель (уравнение), описывающую множественную связь:
y=f(x1, x2, ...,xm, u) (*),
где y – признак-результат;
x1, x2, ...,xm - признаки-факторы;
u – случайная составляющая.
Причины существования случайной составляющей ui:
1) Отсутствие в модели «важных» факторов, оказывающих существенное влияние на результат. Парная регрессия почти всегда является большим упрощением. В действительности существуют другие факторы, которые не учтены в модели (*). Это могут быть факторы, которые мы не можем измерить (например, психологические факторы). Возможно это факторы, которые мы можем измерить, но которые оказывают очень слабое влияние на результат, и поэтому мы их не учитываем в модели. Кроме того, это могут быть «важные» факторы, которые мы такими не считаем из-за отсутствия опыта. Все это приводит к тому, что наблюдаемые значения лежат вне линии регрессии.
2) Агрегирование переменных. Мы можем пытаться построить зависимость путем агрегирования (объединения) индивидуальных соотношений. Например, функцию суммарного потребления, как агрегирование функций потребления по отдельным потребителям. Так как параметры индивидуальных соотношений различны, то агрегированная зависимость будет приближенной и будут расхождения между фактическим и теоретическим значениями результата - y.
3) Неправильная функциональная спецификация модели (вид функции -f).
4) Ошибки измерения переменных.
Задачи анализа многофакторной зависимости:
-
сравнение степени влияния различных факторов на результат;
-
выделение прямого (непосредственного) влияния фактора на результат и косвенного (опосредованного) влияния фактора на результат (через другие факторы);
-
выявление существенности влияния данного фактора (или группы факторов) на результат на фоне других факторов (т.е. нельзя ли исключить из модели данный фактор без существенного ухудшения описания результирующей переменной).
Изобразим графически связи всех признаков для двухфакторной регрессии: y=f(x1,x2,u) (рис.1).

Рис. 1. Граф связей модели: y=f(х1, х2).
Нормальная линейная модель множественной регрессии.
Естественным обобщением линейной парной регрессии является многомерная регрессионная модель (multiple regression model) или модель множественной регрессии:
yi=b0+b1·xi1+b2·xi2+...+bj·xij+…+bm·xim+ui , i=1;n.
где yi- значение признака-результата (зависимой переменной) для i–ого наблюдения;
xji- значение j–ого фактора (независимой или объясняющей переменной) (j=1;m) для i–ого наблюдения;
ui – случайная составляющая результативного признака для i–ого наблюдения;
b0 – свободный член, который формально показывает среднее значение y при х1=х2=…=хm=0 (или среднее значение результата, сформировавшееся под влиянием неучтенных в модели факторов).
bj- коэффициент «чистой» регрессии при j–ом факторе (j=1;m). Он характеризует среднее изменение признака-результата y с изменением соответствующего фактора хj на единицу, при условии, что прочие факторы модели не изменяются и фиксированы на средних уровнях.
Обычно для многомерной регрессионной модели делаются следующие предпосылки (условия Гаусса-Маркова):
-
(x1i, x2i,…, xji,…, xmi) – детерминированные (нестохастические) переменные;
-
М(ui)=0 , i=1;n – математическое ожидание случайной составляющей равно 0 в любом наблюдении;
-
М(ui2)=2ui= 2= const , i=1;n – теоретическая дисперсия случайной составляющей постоянна для всех наблюдений.
-
М(ui, uj)=Cov(ui, uj)=0 (ij) – отсутствие систематической связи между значениями случайной составляющей в любых 2-ух наблюдениях.
-
Часто добавляется условие: ui N(0, 2), т.е. ui – нормально распределенная случайная величина.
Первая предпосылка - сильное предположение. Иногда достаточно сделать предположение о независимости распределения случайной составляющей ui от хi.
Третья предпосылка - о независимости дисперсий случайной составляющей от наблюдения называется гомоскедастичностью (homoscedasticity в переводе означает одинаковый разброс). Случай, когда условие гомоскедастичности не выполняется называется гетероскедастичностью (heteroscedasticity - неодинаковый разброс).
Четвертая предпосылка указывает на некоррелированность случайных составляющих для разных наблюдений. Это условие нарушается в случае, когда данные являются временными рядами. В случае, когда это условие не выполняется, говорят об автокорреляции случайных составляющих (serial correlation).
Модель линейной множественной регрессии, для которой выполняются данные предпосылки, называется нормальной линейной регрессионной (classical normal regression model).
В матричной форме нормальная (классическая) регрессионная модель имеет вид:
Y=X·b + u
Где Y- вектор-столбец размерности (n1) наблюдаемых значений результативного признака.
X – матрица размерности (n(m+1)) наблюдаемых значений факторных признаков. Добавление 1 к общему числу факторов (m) учитывает свободный член (b0) в уравнении регрессии. Значения фактора (х0) для свободного члена принято считать равным единице.
b – вектор-столбец размерности ((m+1)1) неизвестных, подлежащих оценке параметров модели (коэффициентов регрессии).
u - случайный вектор-столбец размерности (n1) ошибок наблюдений.

Предпосылки для модели в матричной форме:
1) (x1, x2,…, xj,…, xm) – детерминированные (нестохастические) переменные, т.е. ранг матрицы Х равен m+1<n;
2) М(u)=0n ;
3,4) ковариационная матрица должна иметь вид:
Сu= =
= =σ2u·I,
где σ2u –
дисперсия случайной составляющей; I
– единичная матрица размером n×n.
=σ2u·I,
где σ2u –
дисперсия случайной составляющей; I
– единичная матрица размером n×n.
5) u N(0, 2u),
Традиционный метод наименьших квадратов для многомерной регрессии (OLS – Least Squares).
Основная задача регрессионного анализа заключается в нахождении по выборке объемом n оценки неизвестных коэффициентов регрессии (b0,b1,…,bm) - вектора b размерности (т + 1).
Пусть имеется п наблюдений вектора
х и зависимой переменной у. Для
того, чтобы формально можно было решить
задачу, то есть найти некоторый наилучший
вектор параметров, должно быть п
т+1. Если это условие не выполняется,
то можно найти бесконечно много разных
векторов коэффициентов, при которых
линейная формула связывает между собой
х и у для имеющихся наблюдений
абсолютно точно. Если, в частном случае,
п = т+1, то оценки коэффициентов b
рассчитываются единственным образом.
Например, при двух объясняющих переменных
в уравнении
![]() =
=
![]() 0+
0+![]() 1х1
+
1х1
+![]() 2х2
и трех наблюдениях для оценки параметров
нужно решить систему:
2х2
и трех наблюдениях для оценки параметров
нужно решить систему:
y1=![]() 0+
0+![]() 1х11
+
1х11
+![]() 2х21
2х21
y2=![]() 0+
0+![]() 1х12
+
1х12
+![]() 2х22
2х22
y3=![]() 0+
0+![]() 1х13
+
1х13
+![]() 2х23
2х23
Система из двух уравнений содержит три
неизвестных (![]() 0,
0,
![]() 1,
1,
![]() 2).
Следовательно, можно найти одно
единственное значение вектора
коэффициентов.
2).
Следовательно, можно найти одно
единственное значение вектора
коэффициентов.
Если число наблюдений больше минимально необходимого, то есть п > т+1, то уже нельзя подобрать линейную формулу, в точности удовлетворяющую всем наблюдениям, и возникает необходимость оптимизации, то есть выбора наилучшей формулы-приближения для имеющихся наблюдений. Положительная разность (п-т-1) в этом случае называется числом степеней свободы. Если число степеней свободы мало, то статистическая надежность оцениваемой формулы невысока. Так, если проведена плоскость "в точности" через имеющиеся три точки наблюдений, любая четвертая точка-наблюдение из той же генеральной совокупности будет практически наверняка лежать вне этой плоскости, возможно - достаточно далеко от нее. Обычно при оценке множественной регрессии для обеспечения статистической надежности требуется, чтобы число наблюдений, по крайней мере, в 3 раза превосходило число оцениваемых параметров.
Оценка параметров многомерной модели,
как и в случае парной регрессии,
осуществляется обычно традиционным
методом наименьших квадратов (МНК).
Согласно данному методу в качестве
оптимальной («наилучшей») оценки вектора
b принимают вектор
![]() ,
который минимизирует сумму квадратов
отклонений наблюдаемых значений yi
от рассчитанных по модели
,
который минимизирует сумму квадратов
отклонений наблюдаемых значений yi
от рассчитанных по модели
![]() :
:
![]() .
.
В![]() матричной форме функционал S
будет записан так:
матричной форме функционал S
будет записан так:
МНК-оценки в матричной форме находят по формулам:
![]() ,
где
,
где
 .
.
Рассмотрим применение МНК путем решения системы алгебраических уравнений при оценивании параметров линейной двухфакторной модели:
yi=b0+b1·x1i+b2·x2i +ui , i=1;n..
Для этого минимизируем функционал:
 .
.
Функционал
S
является функцией 3-ех переменных
![]() ,
,
![]() ,
,
![]() .
Чтобы найти экстремум функции нескольких
переменных нужно взять ее частные
производные по этим переменным и
приравнять их нулю:
.
Чтобы найти экстремум функции нескольких
переменных нужно взять ее частные
производные по этим переменным и
приравнять их нулю:
![]() =0,
=0,
![]() =0,
=0,
![]() =0.
=0.
Получим следующую систему нормальных линейных уравнений:

Формула
расчета оценки параметра
![]() из данной системы:
из данной системы:
 .
.
Аналогично
рассчитывается оценка
![]() .
.
В общем случае, система линейных уравнений может быть решена методами: К.Гаусса, Крамера (определителей), методом итераций.
* Пример. Имеются данные об объеме продаж магазина– y (тыс.ден.ед. за период), численности населения в торговой зоне –х1 (тыс.чел.), расстоянии от магазина до центра –х2 (км) по 12 магазинам розничной торговли, принадлежащем одному владельцу (см. таблицу). Требуется построить регрессионную модель, для прогноза объема продаж.
Возьмем регрессионную модель в виде линейного двухфакторного уравнения регрессии: yi=b0+b1·x1i+b2·x2i +ui .
Оценим параметры этого уравнения с помощью МНК.
Расчет необходимых сумм для системы нормальных линейных уравнений сведем в таблицу.
Таблица.
|
i |
y-объем продаж, тыс.ден.ед. за период |
х1- численность населения в торговой зоне, тыс.чел. |
х2- расстояние от магазина до центра, км |
yх1 |
yх2 |
х12 |
х22 |
х1x2 |
|
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
|
1 |
27 |
1,6 |
9,7 |
43,2 |
261,9 |
2,56 |
94,09 |
15,52 |
|
2 |
26 |
1,7 |
10,7 |
44,2 |
278,2 |
2,89 |
114,49 |
18,19 |
|
3 |
28 |
1,9 |
9,5 |
53,2 |
266 |
3,61 |
90,25 |
18,05 |
|
4 |
31 |
1,9 |
8 |
58,9 |
248 |
3,61 |
64 |
15,2 |
|
5 |
30 |
2 |
9,3 |
60 |
279 |
4 |
86,49 |
18,6 |
|
6 |
31 |
2 |
6,1 |
62 |
189,1 |
4 |
37,21 |
12,2 |
|
7 |
32 |
2,1 |
7,5 |
67,2 |
240 |
4,41 |
56,25 |
15,75 |
|
8 |
35 |
2,5 |
7 |
87,5 |
245 |
6,25 |
49 |
17,5 |
|
9 |
33 |
2,8 |
8,8 |
92,4 |
290,4 |
7,84 |
77,44 |
24,64 |
|
10 |
33 |
3 |
7,1 |
99 |
234,3 |
9 |
50,41 |
21,3 |
|
11 |
36 |
3,1 |
6,5 |
111,6 |
234 |
9,61 |
42,25 |
20,15 |
|
12 |
38 |
3,3 |
7,2 |
125,4 |
273,6 |
10,89 |
51,84 |
23,76 |
|
Сумма |
380 |
27,9 |
97,4 |
904,6 |
3039,5 |
68,67 |
813,72 |
220,86 |
|
Ср. |
31,67 |
2,325 |
8,12 |
75,38 |
253,29 |
5,72 |
67,81 |
18,41 |
|
СКО |
3,47 |
0,53 |
1,39 |
|
|
|
|
|
Тогда система нормальных линейных уравнений будет иметь вид:
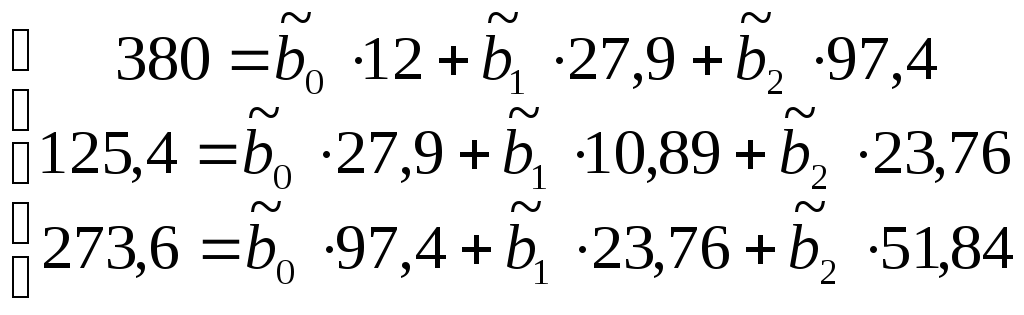
Решив
систему, найдем значения
![]() ,
,
![]() ,
,
![]() :
:
![]() =
29,4;
=
29,4;
![]() =
4,2 ;
=
4,2 ;
![]() =
-0,92.
=
-0,92.
Найдем МНК-оценки для нашего примера матричным способом.
Воспользовавшись правилами умножения матриц будем иметь:
XTX=
 =
=
= .
.
XTY=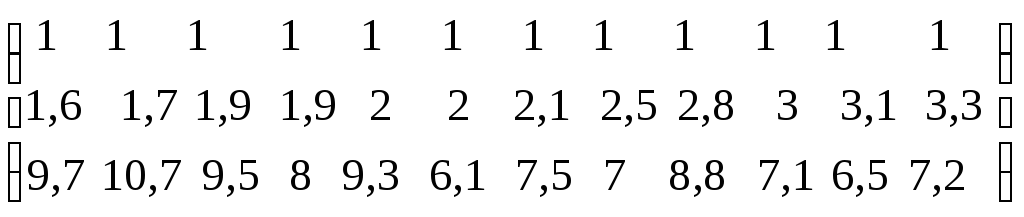
 =
=
= .
.
Найдем обратную матрицу.
Матрицей обратной к матрице А, называется матрица А-1, такая, что АА-1=I (I-единичную матрицу).
Обозначим
aij
элементы матрицы А-1.
Тогда
![]() ,
где Мji
–матрица, получающаяся из А вычеркиванием
j-й
строки и i-ого
столбца.
,
где Мji
–матрица, получающаяся из А вычеркиванием
j-й
строки и i-ого
столбца.
Для
нашего примера: |A|= =680,99;
=680,99;
|M11|= =7099,013;
=7099,013;
a11=(-1)2·7099,013/680,99=10,42 и т.д.
В результате получим:
(ХТХ)-1= -1=
-1= .
.
Тогда вектор оценок коэффициентов регрессии равен:
![]() =
= ·
· =
=![]() .
.
То
есть
![]() =
29,4 ;
=
29,4 ;
![]() =
4,2 ;
=
4,2 ;
![]() =
-0,92 (оценки такие же, что и найденные
1-ым способом).
=
-0,92 (оценки такие же, что и найденные
1-ым способом).
Кроме того, для линейной множественной регрессии существует другой подход получения МНК-оценок параметров - через -коэффициенты (параметры уравнения регрессии в стандартных масштабах).
При построении уравнения регрессии в стандартном масштабе все значения исследуемых признаков переводятся в стандарты (стандартизованные значения) по формулам:
![]() ,
j=1;m,
,
j=1;m,
где хji - значение переменной xj в i-ом наблюдении.
![]() .
.
Таким образом, начало отсчета каждой стандартизованной переменной совмещается с ее средним значением, а в качестве единицы изменения принимается ее среднее квадратическое отклонение (). Если связь между переменными в естественном масштабе линейная, то изменение начала отсчета и единицы измерения этого свойства не нарушат, так что и стандартизованные переменные будут связаны линейным соотношением:
![]() .
(β0=0).
.
(β0=0).
-коэффциенты могут быть оценены с помощью обычного МНК.
При этом система нормальных уравнений будет иметь вид:
rx1y=1+rx1x22+…+ rx1xmm
rx2y= rx2x11+2+…+ rx2xmm
…
rxmy= rxmx11+rxmx22+…+m
(т.к.
![]() )
)
Найденные
из данной системы –коэффициенты
позволяют определить значения
коэффициентов регрессии в естественном
масштабе по формулам:
![]() ,
j=1;m;
,
j=1;m;
![]() .
.
Значения коэффициентов корреляции берут из корреляционной матрицы - матрице парных линейных коэффициентов корреляции :

где rjk – коэффициент парной линейной корреляции между j-ым и k-ым факторными признаками (j,k=1;m);
ryj - коэффициент парной линейной корреляции между результативным признаком- y и j-ым фактором (j=1;m).
Коэффициент корреляции, измеряющий связь признака с самим собой, равен единице, т.к. в этом случае имеет место максимально тесная связь. Поэтому на главной диагонали в корреляционной матрице стоят единицы. Корреляционная матрица является симметричной относительно главной диагонали, т.к. rjk=rki.
* Пример. Найдем коэффициенты регрессии через –коэффициенты (по данным о магазинах). Система нормальных линейных уравнений (в случае двух факторов) будет иметь вид:
rx1y=1+rx1x22
rx2y= rx2x11+2
Рассчитаем коэффициенты линейной парной корреляции и построим корреляционную матрицу:
![]()
![]()
![]()