

9. Средняя и предельная ошибка выборки. Построение доверительных интервалов.
Ошибки выборки бывают систематические и случайные.
Систематические — в том случае, когда нарушен основной принцип выборки — случайности.
Случайные — возникают обычно ввиду того, что структура выборочной совокупности всегда отличается от структуры генеральной совокупности, как бы правильно ни был произведен отбор, то есть, несмотря на принцип случайности отбора единиц совокупности, все же имеются расхождения между характеристиками выборочной и генеральной совокупности. Изучение и измерение случайных ошибок репрезентативности и является основной задачей выборочного метода.
Как правило, чаще всего рассчитывают ошибку средней и ошибку доли. При расчетах используются следующие условные обозначения:
![]() —средняя, рассчитанная
в пределах генеральной совокупности;
—средняя, рассчитанная
в пределах генеральной совокупности;
— средняя, рассчитанная в пределах выборочной совокупности;
p — доля данной группы в генеральной совокупности;
w — доля данной группы в выборочной совокупности.
Используя условные обозначения, ошибки выборки для средней и для доли можно записать следующим образом:
![]()

В этих формулах дисперсия признака является характеристикой генеральной совокупности, которые при выборочном наблюдении неизвестны. На практике их заменяют аналогичными характеристиками выборочной совокупности на основании закона больших чисел, по которому выборочная совокупность при большом объеме точно воспроизводит характеристики генеральной совокупности.
Формулы определения средней ошибки для различных способов отбора:
|
|
|
Повторный |
|
Бесповторный |
|
| ||||||
|
Способ отбора |
ошибка средней |
ошибка доли |
ошибка средней |
ошибка доли | ||||||||
|
|
|
|
|
|
|
|
| |||||
|
Собственно-случайный |
|
|
|
|
|
| ||||||
|
и механический |
|
|
|
|
|
| ||||||
|
|
|
|
|
|
|
|
| |||||
|
|
|
|
|
|
|
|
| |||||
|
Типический |
|
|
|
|
|
| ||||||
|
|
|
|
|
|
|
|
| |||||
|
|
|
|
|
|
|
|
| |||||
|
|
|
|
|
|
|
|
| |||||
|
Серийный |
|
|
|
|
|
| ||||||
|
|
|
|
|
|
|
|
| |||||
|
|
|
|
|
|
|
|
| |||||
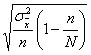





D — предельная ошибка;
m — средняя ошибка;
n — численность выборки;
N — численность генеральной совокупности;
![]() —
общая дисперсия;
—
общая дисперсия;
w — доля данной категории в общей численности выборки;
![]() —
средняя из внутригрупповых дисперсий;
—
средняя из внутригрупповых дисперсий;
d2 — межгрупповая дисперсия;
r — число серий в выборке;
R — общее число серий.
Предельная ошибка для всех способов отбора связана со средней ошибкой выборки следующим образом:
D = tm,
где t — коэффициент доверия, функционально связанный с вероятностью, с которой обеспечивается величина предельной ошибки. В зависимости от вероятности коэффициент доверия t принимает следующие значения:
t P
1 0,683
1,5 0,866
2 0,954
2,5 0,988
3 0,997
4 0,9999
Величина предельной ошибки зависит от следующих величин:
колеблемости признака (прямая связь), которую характеризует величина дисперсии;
численности выборки (обратная связь);
доверительной вероятности (прямая связь);
метода отбора.
Помимо прямой задачи (определение величины ошибки) формула предельной ошибки позволяет решать еще две задачи.
Определить необходимую численность выборки, при которой пределы возможной ошибки не превышают некоторой заданной величины.
Определить вероятность того, что в проведенной выборке ошибка будет заключаться в заданных пределах.
Решение этих задач зависит от способа отбора. Например, необходимая численность выборки для повторного отбора:

при без повторной:
![]()
Построение доверительных интервалов.
При выборке малого объема точечная оценка может значительно отличаться от оцениваемого параметра, что приводит к грубым ошибкам. Поэтому в таком случае лучше пользоваться интервальными оценками, то есть указывать интервал, в который с заданной вероятностью попадает истинное значение оцениваемого параметра. Разумеется, чем меньше длина этого интервала, тем точнее оценка параметра. Поэтому, если для оценки Θ* некоторого параметра Θ справедливо неравенство | Θ* - Θ | < δ, число δ > 0 характеризуетточность оценки ( чем меньше δ, тем точнее оценка). Но статистические методы позволяют говорить только о том, что это неравенство выполняется с некоторой вероятностью.
Определение 18.1. Надежностью (доверительной вероятностью)оценки Θ* параметра Θ называется вероятность γ того, что выполняется неравенство | Θ* - Θ | < δ. Если заменить это неравенство двойным неравенством – δ < Θ* - Θ < δ, то получим:
p(Θ* -δ<Θ<Θ* +δ) =γ.
Таким образом, γ есть вероятность того, что Θ попадает в интервал ( Θ* - δ, Θ* + δ).
Определение 18.2. Доверительным называется интервал, в который попадает неизвестный параметр с заданной надежностью γ.
Построение доверительных интервалов.
1. Доверительный интервал для оценки математического ожидания нормального распределения при известной дисперсии.
Пример. Найдем доверительный интервал
для математического ожидания нормально
распреде-ленной случайной величины,
если объем выборки п= 49,σ
= 1,4, а доверительная вероятность γ = 0,9.
Определим t, при котором Ф(t) = 0,9:2 = 0,45:t= 1,645. Тогда
, или 2,471 < a< 3,129. Найден доверительный интервал, в который попадаетас надежностью 0,9.
2. Доверительный интервал для оценки математического ожидания нормального распределения при неизвестной дисперсии.
Пример. Пусть объем выборки п= 25,= 3,s= 1,5. Найдем доверительный интервал дляапри γ = 0,99. Из таблицы находим, чтоtγ(п= 25, γ = 0,99) = 2,797. Тогда, или 2,161<a< 3,839 – доверительный интервал, в
который попадаетас вероятностью
0,99.
3. Доверительные интервалы для оценки среднего квадратического отклонения нормального распределения.
Будем искать для среднего квадратического отклонения нормально распределенной случайной величины доверительный интервал вида (s – δ, s +δ), гдеs– исправленное выборочное среднее квадратическое отклонение, а для δ выполняется условие:p( |σ –s| < δ ) = γ.
. Тогда Существуют таблицы для распределения «хи-квадрат», из которых можно найти qпо заданнымпи γ, не решая этого уравнения. Таким образом, вычислив по выборке значениеsи определив по таблице значение q, можно найти доверительный интервал (18.4), в который значение σ попадает с заданной вероятностью γ.
Замечание.Еслиq> 1, то с учетом условия σ > 0 доверительный интервал для σ будет иметь границы
Пример.
Пусть п= 20,s= 1,3. Найдем доверительный интервал для σ при заданной надежности γ = 0,95. Из соответствующей таблицы находимq(n= 20,γ= 0,95 ) = 0,37. Следовательно, границы доверительного интервала: 1,3(1-0,37) = 0,819 и 1,3(1+0,37) = 1,781. Итак, 0,819< σ < 1,781 с вероятностью 0,95.
Виды выборок.
В зависимости от методики формирования выборочной совокупности различают следующие основные виды выборки:
собственно случайную;
механическую;
типическую (стратифицированную, районированную);
серийную (гнездовую);
комбинированную;
многоступенчатую;
многофазную;
взаимопроникающую.
Собственно случайная выборка формируется в строгом соответствии с научными принципами и правилами случайного отбора. Для получения собственно случайной выборки генеральная совокупность строго подразделяется на единицы отбора, и затем в случайном повторном или бесповторном порядке отбирается достаточное число единиц.
Случайный порядок подобен жеребьевке. На практике он чаще всего применяется при использовании специальных таблиц случайных чисел. Если, например, из совокупности, содержащей 1587 единиц, следует отобрать 40 единиц, то из таблицы отбирают 40 четырехзначных чисел, которые меньше 1587.
В том случае, когда собственно случайная выборка организуется как повторная, расчет стандартной ошибки производится в соответствии с формулой (6.2). При бесповторном способе отбора формула для расчета стандартной ошибки будет:

где 1 – n / N – доля единиц генеральной совокупности, не попавших в выборку. Так как эта доля всегда меньше единицы, то ошибка при бесповторном отборе при прочих равных условиях всегда меньше, чем при повторном. Бесповторный отбор организовать легче, чем повторный, и он применяется намного чаще. Однако величину стандартной ошибки при бесповторном отборе можно определять по более простой формуле (5.1). Такая замена возможна, если доля единиц генеральной совокупности, не попавших в выборку, большая и, следовательно, величина близка к единице.
Формировать выборку в строгом соответствии с правилами случайного отбора практически очень сложно, а иногда невозможно, так как при использовании таблиц случайных чисел необходимо пронумеровать все единицы генеральной совокупности. Довольно часто генеральная совокупность такая большая, что провести подобную предварительную работу чрезвычайно сложно и нецелесообразно, поэтому на практике применяют другие виды выборок, каждая из которых не является строго случайной. Однако организуются они так, чтобы было обеспечено максимальное приближение к условиям случайного отбора.
При чисто механической выборке вся генеральная совокупность единиц должна быть прежде всего представлена в виде списка единиц отбора, составленного в каком-то нейтральном по отношению к изучаемому признаку порядке, например по алфавиту. Затем список единиц отбора разбивается на столько равных частей, сколько необходимо отобрать единиц. Далее по заранее установленному правилу, не связанному с вариацией исследуемого признака, из каждой части списка отбирается одна единица. Этот вид выборки не всегда может обеспечить случайный характер отбора, и полученная выборка может оказаться смещенной. Объясняется это тем, что, во-первых, упорядочение единиц генеральной совокупности может иметь элемент неслучайного характера. Во-вторых, отбор из каждой части генеральной совокупности при неправильном установлении начала отсчета может также привести к ошибке смещения. Однако практически легче организовать механическую выборку, чем собственно случайную, и при проведении выборочных обследований чаще всего пользуются этим видом выборки. Стандартную ошибку при механической выборке определяют по формуле собственно случайной бесповторной выборки (6.2).
Типическая (районированная, стратифицированная) выборка преследует две цели:
• обеспечить представительство в выборке соответствующих типических групп генеральной совокупности по интересующим исследователя признакам;
• увеличить точность результатов выборочного обследования.
При типической выборке до начала ее формирования генеральная совокупность единиц разбивается на типические группы. При этом очень важным моментом является правильный выбор группировочного признака. Выделенные типические группы могут содержать одинаковое или различное число единиц отбора. В первом случае выборочная совокупность формируется с одинаковой долей отбора из каждой группы, во втором – с долей, пропорциональной ее доле в генеральной совокупности. Если выборка формируется с равной долей отбора, по существу она равносильна ряду собственно случайных выборок из меньших генеральных совокупностей, каждая из которых и есть типическая группа. Отбор из каждой группы осуществляется в случайном (повторном или бесповторном) либо механическом порядке. При типической выборке, как с равной, так и неравной долей отбора, удается устранить влияние межгрупповой вариации изучаемого признака на точность ее результатов, так как обеспечивается обязательное представительство в выборочной совокупности каждой из типических групп. Стандартная ошибка выборки будет зависеть не от величины общей дисперсии ?2, а от величины средней из групповых дисперсий ?i2. Поскольку средняя из групповых дисперсий всегда меньше общей дисперсии, постольку при прочих равных условиях стандартная ошибка типической выборки будет меньше стандартной ошибки собственно случайной выборки.
При определении стандартных ошибок типической выборки применяются следующие формулы:
• при повторном способе отбора

• при бесповторном способе отбора:

– средняя из групповых дисперсий в выборочной совокупности.
Серийная (гнездовая) выборка – это такой вид формирования выборочной совокупности, когда в случайном порядке отбираются не единицы, подлежащие обследованию, а группы единиц (серии, гнезда). Внутри отобранных серий (гнезд) обследованию подвергаются все единицы. Серийную выборку практически организовать и провести легче, чем отбор отдельных единиц. Однако при этом виде выборки, во-первых, не обеспечивается представительство каждой из серий и, во-вторых, не устраняется влияние межсерийной вариации изучаемого признака на результаты обследования. В том случае, когда эта вариация значительна, она приведет к увеличению случайной ошибки репрезентативности. При выборе вида выборки исследователю необходимо учитывать это обстоятельство. Стандартная ошибка серийной выборки определяется по формулам:
• при повторном способе отбора -

где ?– межсерийная дисперсия выборочной совокупности; r – число отобранных серий;
• при бесповторном способе отбора -

где R – число серий в генеральной совокупности.
В практике те или иные способы и виды выборок применяются в зависимости от цели и задач выборочных обследований, а также возможностей их организации и проведения. Чаще всего применяется комбинирование способов отбора и видов выборки. Такие выборки получили название комбинированные. Комбинирование возможно в разных сочетаниях: механической и серийной выборки, типической и механической, серийной и собственно случайной и т. д. К комбинированной выборке прибегают для обеспечения наибольшей репрезентативности с наименьшими трудовыми и денежными затратами на организацию и проведение обследования.
При комбинированной выборке величина стандартной ошибки выборки состоит из ошибок на каждой ее ступени и может быть определена как корень квадратный из суммы квадратов ошибок соответствующих выборок. Так, если при комбинированной выборке в сочетании использовались механическая и типическая выборки, то стандартную ошибку можно определить по формуле

где ?1 и ?2 – стандартные ошибки соответственно механической и типической выборок.
Особенность многоступенчатой выгборки состоит в том, что выборочная совокупность формируется постепенно, по ступеням отбора. На первой ступени с помощью заранее определенного способа и вида отбора отбираются единицы первой ступени. На второй ступени из каждой единицы первой ступени, попавшей в выборку, отбираются единицы второй ступени и т. д. Число ступеней может быть и больше двух. На последней ступени формируется выборочная совокупность, единицы которой подлежат обследованию. Так, например, для выборочного обследования бюджетов домашних хозяйств на первой ступени отбираются территориальные субъекты страны, на второй – районы в отобранных регионах, на третьей – в каждом муниципальном образовании отбираются предприятия или организации и, наконец, на четвертой ступени – в отобранных предприятиях отбираются семьи.
Таким образом, выборочная совокупность формируется на последней ступени. Многоступенчатая выборка более гибкая, чем другие виды, хотя в общем она дает менее точные результаты, чем выборка того же объема, но сформированная в одну ступень. Однако при этом она имеет одно важное преимущество, которое заключается в том, что основу выборки при многоступенчатом отборе нужно строить на каждой из ступеней только для тех единиц, которые попали в выборку, а это очень важно, так как нередко готовой основы выборки нет.
Стандартную ошибку выборки при многоступенчатом отборе при группах разных объемов определяют по формуле

где ?1, ?2, ?3, ... – стандартные ошибки на разных ступенях;
n1, n2, n3, ... – численность выборок на соответствующих ступенях отбора.
В том случае, если группы неодинаковы по объему, то теоретически этой формулой пользоваться нельзя. Но если общая доля отбора на всех ступенях постоянна, то практически расчет по этой формуле не приведет к искажению величины ошибки.
Сущность многофазной выгборки состоит в том, что на основе первоначально сформированной выборочной совокупности образуют подвыборку, из этой подвыборки – следующую подвыборку и т. д. Первоначальная выборочная совокупность представляет собой первую фазу, подвыборка из нее – вторую и т. д. Многофазную выборку целесообразно применять в случаях, если:
для изучения различных признаков требуется неодинаковый объем выборки;
колеблемость изучаемых признаков неодинакова и требуемая точность различна;
в отношении всех единиц первоначальной выборочной совокупности (первая фаза) необходимо собрать менее подробные сведения, а в отношении единиц каждой последующей фазы – более подробные.
Одним из несомненных достоинств многофазной выборки является то обстоятельство, что сведениями, полученными на первой фазе, можно пользоваться как дополнительной информацией на последующих фазах, информацией второй фазы – как дополнительной информацией на следующих фазах и т. д. Такое использование сведений повышает точность результатов выборочного обследования.
При организации многофазной выборки можно применять сочетание различных способов и видов отбора (типическую выборку с механической и т. д.). Многофазный отбор можно сочетать с многоступенчатым. На каждой ступени выборка может быть многофазной.
Стандартная ошибка при многофазной выборке рассчитывается на каждой фазе в отдельности в соответствии с формулами того способа отбора и вида выборки, при помощи которых формировалась ее выборочная совокупность.
Взаимопроникающие выгборки – это две или более независимые выборки из одной и той же генеральной совокупности, образованные одним и тем же способом и видом. К взаимопроникающим выборкам целесообразно прибегать, если необходимо за короткий срок получить предварительные итоги выборочных обследований. Взаимопроникающие выборки эффективны для оценки результатов обследования. Если в независимых выборках результаты одинаковы, то это свидетельствует о надежности данных выборочного обследования. Взаимопроникающие выборки иногда можно применять для проверки работы различных исследователей, поручив каждому из них провести обследование разных выборок.
Стандартная ошибка при взаимопроникающих выборках определяется по той же формуле, что и типическая пропорциональная выборка (5.3). Взаимопроникающие выборки по сравнению с другими видами требуют больших трудовых затрат и денежных расходов, поэтому исследователь должен учитывать это обстоятельство при проектировании выборочного обследования.
Предельные ошибки при различных способах отбора и видах выборки определяются по формуле ? = t?, где ? – соответствующая стандартная ошибка.
Малые выборки.
Таблицы интеграла вероятностей используются для выборок большого объема из бесконечно большой генеральной совокупности. Но уже при п < \ 00 получается несоответствие между табличными данными и вероятностью предела; при п < 100 погрешность становится значительной. Несоответствие вызывается главным образом характером распределения единиц генеральной совокупности. При большом объеме выборки особенность распределения в генеральной совокупности не имеет значения, так как распределение отклонений выборочного показателя от генеральной характеристики при большой выборке всегда оказывается нормальным.
В выборках небольшого объема п ≤ 30 характер распределения генеральной совокупности сказывается на распределении ошибок выборки. Поэтому для расчета ошибки выборки при небольшом объеме наблюдения (уже менее 100 единиц) отбор должен проводиться из совокупности, имеющей нормальное распределение.
Теория малых выборок разработана английским статистиком В. Госсетом (писавшим под псевдонимом Стьюдент) в начале XX в. В 1908 г. им построено специальное распределение, которое позволяет и при малых выборках соотносить t и доверительную вероятность F(t). При п > 100 таблицы распределения Стьюдента дают те же результаты, что и таблицы интеграла вероятностей Лапласа, при 30 ≤ п ≤ 100 различия незначительны. Поэтому практически к малым выборкам относят выборки объемом менее 30 единиц (безусловно, большой считается выборка с объемом более 100 единиц).
Использование малых выборок в ряде случаев обусловлено характером обследуемой совокупности. Так, в селекционной работе «чистого» опыта легче добиться на небольшом числе делянок. Производственный и экономический эксперимент, связанный с экономическими затратами, также проводится на небольшом числе испытаний.
Как уже отмечалось, в случае малой выборки только для нормально распределенной генеральной совокупности могут быть рассчитаны и доверительные вероятности, и доверительные пределы генеральной средней.
Плотность вероятностей распределения Стьюдента описывается функцией

где t - текущая переменная;
п — объем выборки;
В — величина, зависящая лишь от п.
Распределение Стьюдента имеет только один параметр: d.f. -число степеней свободы (иногда обозначается k).
Это распределение, как и нормальное, симметрично относительно точки t = 0, но оно более пологое. При увеличении объема выборки, а следовательно, и числа степеней свободы распределение Стьюдента быстро приближается к нормальному. Число степеней свободы равно числу тех индивидуальных значений признаков, которыми нужно располагать для определения искомой характеристики.
Так, для расчета дисперсии должна быть известна средняя величина. Поэтому при расчете дисперсии d.f. = п - 1
Таблицы распределения Стьюдента публикуются в двух вариантах:
1) аналогично таблицам интеграла вероятностей приводятся значения t и соответствующие вероятности F(t) при разном числе степеней свободы;
2) значения t приводятся для наиболее употребимых доверительных вероятностей 0,90; 0,95 и 0,99 или для 1 - 0,9 = 0,1, 1 - 0,95 = = 0,05 и 1 - 0,99 == 0,01 при разном числе степеней свободы. Такого рода таблица приведена в приложении (табл. 2), а также значение t-критерия Стьюдента при уровне значимости 0,10; 0,05; 0,01.
При малых выборках расчет средней возможной ошибки основан на выборочных дисперсиях, поэтому

Приведенная формула используется для определения предела возможной ошибки выборочного показателя:
![]()
Порядок расчетов тот же, что и при больших выборках.
Пример. Для изучения интенсивности труда было организовано наблюдение за 10 отобранными рабочими. Доля работавших все время оказалась равной 0,40, дисперсия 0,4•0,6 = 0,24. По табл. 2 приложения находим для F(t) = 0,95 и d.f. = n - 1 = 9, t = 2,26. Рассчитаем среднюю ошибку выборки доли работавших все время:

Тогда предельная ошибка выборки ?p = 2,26•0,16 = ± 0,36. Таким образом, с вероятностью 0,95 доля рабочих, работавших без простоев, в данном цехе предприятия находится в пределах
39,64% ≤ ? ≤ 40,36%
или
39,6% ≤ ? ≤ 40,4%.
Если бы мы использовали для расчета доверительных границ генерального параметра таблицу интеграла вероятностей, то t было бы равно 1,96 и ?p - ± 0,31, т. е. доверительный интервал был бы несколько уже.
Малые выборки широко используются для решения задач, связанных с испытанием статистических гипотез, особенно гипотез о средних величинах.
Индексный анализ финансовых показателей.
Индексный метод позволяет определить влияние факторов на обобщающий показатель в динамике. Метод основывается на использовании относительных показателей, выражающих отношение уровня данного явления к его уровню, принятому в качестве базы. Различают индивидуальные и групповые индексы. Кроме того, в анализе хозяйственной деятельности используются индексы базисные, показывающие изменение явления относительно базисного периода, и цепные, характеризующие изменение явления относительно предыдущего периода.
Например, анализируется изменение объема товарной продукции (Т) за четыре месяца – Т1, Т2, Т3,
Принимая в качестве базисного периода один месяц, получаем для каждого 1-го месяца базисный
Iбаз = Тi /Т1 и цепной индекс Iцеп = Тi /Тi–1:
Iбаз5/1 = Iцеп1/1 • Iцеп2/1 • Iцеп3/2 • Iцеп4/3.
Индексный метод может быть использован для факторного анализа какого-либо показателя.
Например, необходимо определить изменение по сравнению с прошлым годом объема товарной продукции ?Т под влиянием переменной численности рабочих (а) и производительности их труда (в). Для решения строится система взаимосвязанных индексов:
Iобщ = (в1• а1)/(в0• а0) = Т1/ Т0,
где Iобщ – общий групповой индекс изменения объема выпуска продукции; в1, в0 – среднегодовая выработка товарной продукции на одного рабочего соответственно в анализируемом и базисном периодах; а1, а0 – среднегодовая выработка товарной продукции на одного рабочего соответственно в анализируемом и базисном периодах; Т1, Т0 – объем товарной продукции соответственно в анализируемом и прошлом базисном периодах.
При построении факторных индексов для определения влияния количественного показателя качественный фиксируется на базисном уровне в0, а при установлении влияния качественного показателя количественный фиксируется на уровне а1. Тогда:
Iобщ = Iа • Iв,
где Iа – факторный индивидуальный индекс изменения численности рабочих;
Iв– факторный индивидуальный индекс изменения средней годовой выработки одного рабочего.
При этой величине отклонение товарной продукции под действием обоих факторов равна:
?Т = (в0а1 – в0а0) + (в1а1 – в0а1) = в1а1 – в0а0.
Виды статистических индексов.
Статистический индекс — это относительная величина сравнения сложных совокупностей и отдельных их единиц. При этом под сложной понимается такая статистическая совокупность, отдельные элементы которой непосредственно не подлежат суммированию.
Основой индексного метода при определении изменений в производстве и обращении товаров является переход от натурально-вещественной формы выражения товарных масс к стоимостным (денежным) измерителям. Именно посредством денежного выражения стоимости отдельных товаров устраняется их несравнимость и достигается единство.
Виды индексов различают по следующим факторам:
по степени охвата элементов совокупности:
индивидуальные – характеризуют изменение только одного элемента совокупности;
сводные (общие) – отражают изменения по всей совокупности элементов сложного явления. Их разновидностью являются групповые индексы.
в зависимости от содержания и характера индексируемой величины:
индексы количественных показателей (например, индекс физического объема);
индексы качественных показателей (например, индекс цен, себестоимости, производительности труда).
в зависимости от методологии расчета:
агрегатные – могут быть рассчитаны как индексы переменного и постоянного состава;
средние из индивидуальных – получаются путем нахождения общих индексов с использованием индивидуальных.
Для удобства восприятия индексов в теории статистики разработана символика:
- q – количество единиц какого-либо вида продукции;
- p – цена единицы какого-либо вида продукции;
- z – себестоимость единицы какого-либо вида продукции;
- t – трудоемкость единицы какого-либо вида продукции
Индивидуальные индексы. Правила построения и анализа.
индивидуальные индексы - это индексы, которые характеризуют изменение только одного элемента совокупности.
Различают следующие индивидуальные индексы:
индекс физического объема – показывает во сколько раз увеличился (уменьшился) объем в натуральных единицах в отчетном периоде по сравнению с базисным
![]()
где q1 и q0 - количество продукции данного вида в натуральном выражении в текущем и базисном периодах.
Аналогично рассчитывается индекс затрат на выпуск продукции (ЗВП), который отражает изменение затрат на производство и может быть как индивидуальным, так и агрегатным.
индекс цен – показывает во сколько раз увеличилась (уменьшилась) цена единицы продукции в отчетном периоде по сравнению с базисным;
![]()
где p1 и p0 - цена за единицу продукции в текущем и базисном периодах.
индекс себестоимости – показывает во сколько раз увеличилась (уменьшилась) себестоимость единицы продукции в отчетном периоде по сравнению с базисным.
![]()
где p1 и p0 - цена единицы продукции данного вида в текущем и базисном периодах; q1 p1 и q0 p0 - стоимость продукции данного вида в текущем и базисном периодах.
15. Агрегатная форма сводного индекса. Правила построения и анализа.
Основной формой общих индексов являются агрегатные индексы.
Расчет индексов по агрегатным формулам возможен, если есть полные данные о физическом объеме продукции и о ценах как на уровне отчетного так и базисного периодов. В реальной действительности полные данные имеются не всегда. В таких случаях приходится исчислять индексы как среднюю взвешенную величину из индивидуальных индексов. Средний из индивидуальных индексов будет тогда правильным, когда он тождественен агрегатному индексу. Это означает, что средние из индивидуальных индексов не самостоятельные индексы, а преобразованная форма агрегатного индекса. При исчислении средних индексов могут быть использованы только две формы средних: средняя арифметическая и средняя гармоническая:
