

CUDA_full / L03_Threads_Memory
.pdfИспользование глобальной памяти
Выделение и освобождение памяти на устройстве:
–cudaError_t cudaMalloc (void** devPtr, size_t count) –
выделяет память на устройстве и возвращает указатель на нее;
–cudaError_t cudaFree (void* devPtr) – освобождает память на устройстве.
Копирование данных между хостом и устройством:
–cudaError_t cudaMemcpy (void* dst, const void* src, size_t count, enum cudaMemcpyKind kind),
kind может принимать значения cudaMemcpyHostToDevice и cudaMemcpyDeviceToHost.
– cudaMemcpyAsync – неблокирующий вариант.
Н. Новгород, 2012 г. |
Исполнение потоков. Иерархия памяти |
31 |
|
|

Пример: выделение памяти и копирование вектора
Выделение памяти на хосте и устройстве: int n = 1000;
float * a = new float[n], * a_gpu; cudaMalloc((void**)&a_gpu, n *
sizeof(float));
Копирование с хоста на устройтво: cudaMemcpy(a_gpu, a, n * sizeof(float),
cudaMemcpyHostToDevice);
Копирование с устройства на хост: cudaMemcpy(a, a_gpu, n * sizeof(float),
cudaMemcpyDeviceToHost);
Н. Новгород, 2012 г. |
Исполнение потоков. Иерархия памяти |
32 |
|
|

Эффективная работа с глобальной памятью
L1/L2 кэш для глобальной памяти появился в архитектуре
Fermi.
Латентность 400-600 тактов (без учета кэша или в случае кэш-промаха).
Оптимизация работы с глобальной памятью обычно имеет очень большое значение.
Н. Новгород, 2012 г. |
Исполнение потоков. Иерархия памяти |
33 |
|
|

Эффективная работа с глобальной памятью
Доступ в глобальную память осуществляется полуварпами.
Каждый поток обращается к 32-, 64или 128-битным словам.
При выполнении определенных условий происходит
объединение запросов (коалесцирование, coalescing) к
памяти всех потоков полуварпа в одну операцию доступа к непрерывному блоку памяти и выполнение их одной инструкцией.
В противном случае доступ полуварпа к памяти разбивается на несколько последовательных доступов к непрерывным блокам памяти.
Условия для объединения запросов зависят от вычислительных возможностей, постепенно они становятся
все более мягкими.
Н. Новгород, 2012 г. |
Исполнение потоков. Иерархия памяти |
34 |
|
|

Эффективная работа с глобальной памятью
Условия, необходимые для объединения запросов:
–Доступ в пределах одного последовательного участка памяти определенного размера.
–Выровненность адресов, с которыми работает каждый поток, по размеру типа. Выровненность автоматически обеспечивается для встроенных векторных типов, для обеспечения выровненности структур используется
__align__ (newsize) при их объявлении.
Н. Новгород, 2012 г. |
Исполнение потоков. Иерархия памяти |
35 |
|
|
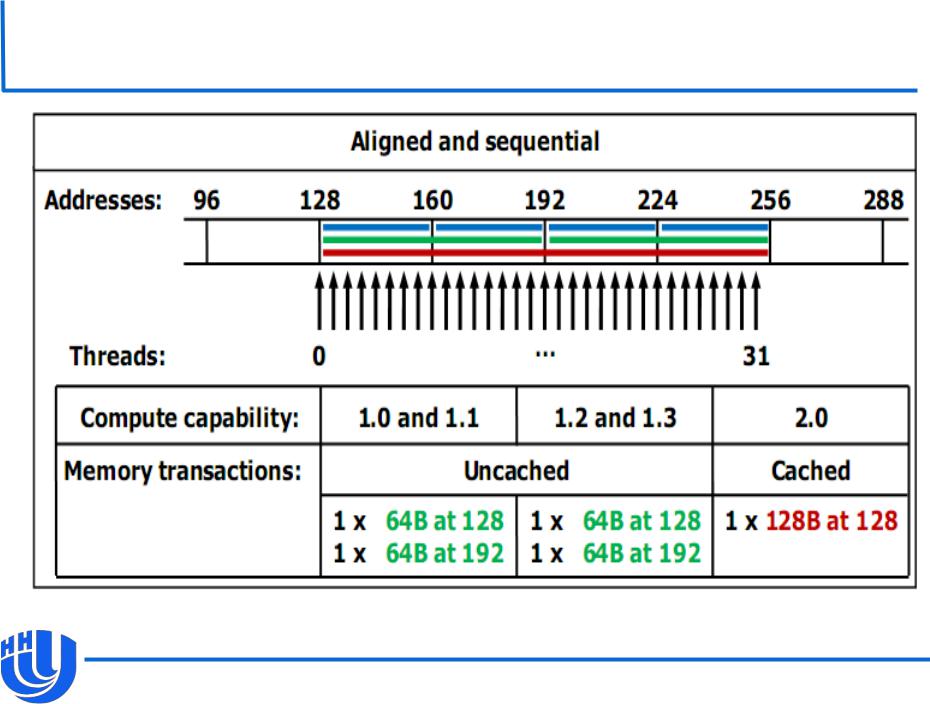
Пример доступа к глобальной памяти
[NVIDIA CUDA C Programming Guide v. 4.0]
Н. Новгород, 2012 г. |
Исполнение потоков. Иерархия памяти |
36 |
|
|
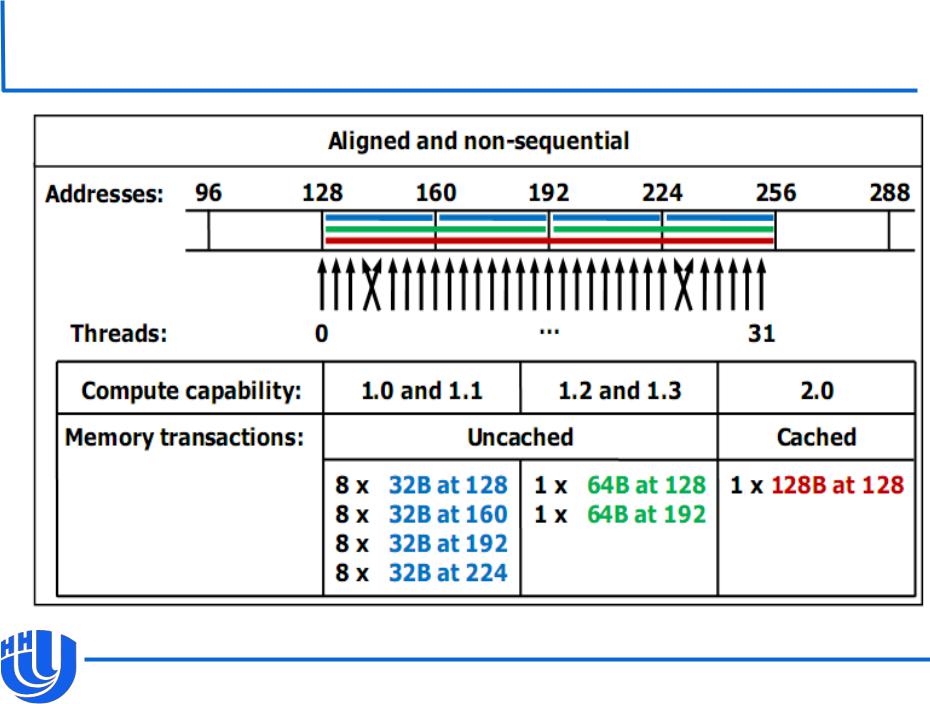
Пример доступа к глобальной памяти
[NVIDIA CUDA C Programming Guide v. 4.0]
Н. Новгород, 2012 г. |
Исполнение потоков. Иерархия памяти |
37 |
|
|
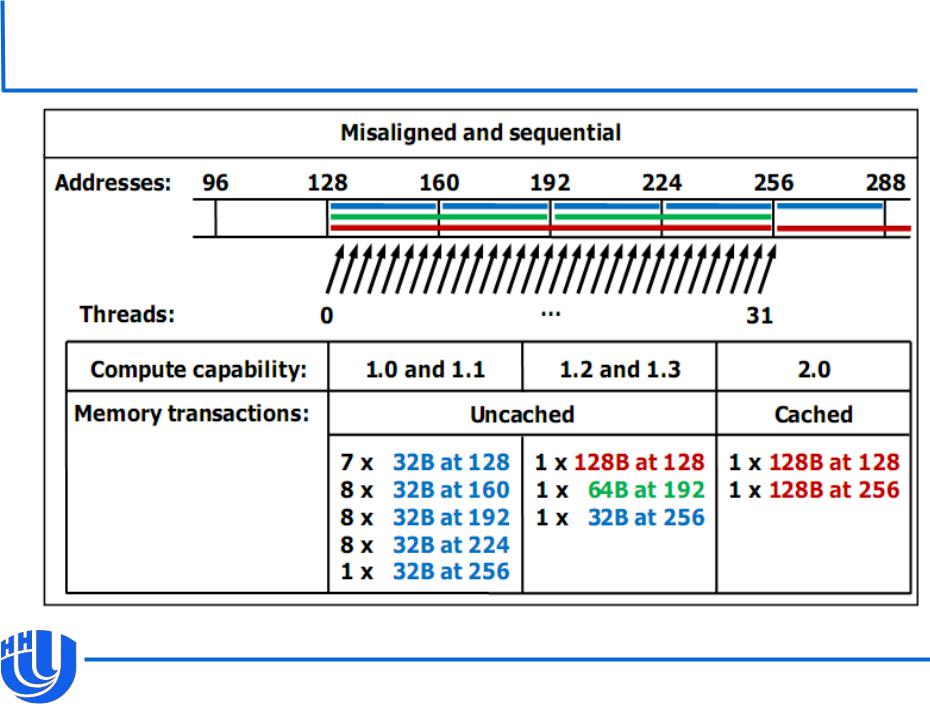
Пример доступа к глобальной памяти
[NVIDIA CUDA C Programming Guide v. 4.0]
Н. Новгород, 2012 г. |
Исполнение потоков. Иерархия памяти |
38 |
|
|

Рекомендации по эффективной работе с глобальной памятью
За счет объединения запросов можно добиться значительного уменьшения времени на доступ к глобальной памяти.
Объединение запросов заведомо невозможно, когда адреса, по которым обращаются потоки одного полуварпа, расположены далеко друг от друга.
Для обеспечения объединения запросов обычно стоит предпочитать регулярные структуры данных нерегулярным.
В случае независимой обработки вместо массива структур обычно лучше использовать массивы отдельных компонент.
Н. Новгород, 2012 г. |
Исполнение потоков. Иерархия памяти |
39 |
|
|

Пример
/* Одна итерация метода Якоби для системы размера n на n: x0
– текущее приближение, x1 – следующее, матрица a хранится
по строкам, f – правая часть. Каждый поток вычисляет свой
элемент вектора x1, общее число потоков равно n. */
__global__ void kernel (float * a, float * f, float * x0, float * x1, int n)
{
int idx = blockIdx.x * blockDim.x + threadIdx.x; int ia = n * idx;
float sum = 0.0f;
for (int i = 0; i < n; i++)
|
|
sum += a[ia + i] * x0[i]; /* плохой вариант |
|
|
доступа к a, лучше хранить ее по столбцам */ |
|
float alpha = 1.0f / a[ia + idx]; |
|
|
x1[idx] = x0[idx] + alpha * (f[idx] - sum); |
|
} |
|
Использованы материалы: А.В. Боресков, А.А. Харламов «Архитектура и |
|
|
программирование массивно-параллельных вычислительных систем» |
|
|
|
Н. Новгород, 2012 г. |
Исполнение потоков. Иерархия памяти |
40 |
|
|