

Параллельные Процессы и Параллельное Программирование / SNNSv4.2.Manual
.pdf13.2. ANALYZE |
269 |
-r |
numbers of patterns which were classi ed right are printed |
-u |
numbers of patterns which were not classi ed are printed |
-a |
same as -w -r -u |
-S "t c" |
speci c: numbers of class t pattern which are |
|
classi ed as class c are printed (-1 = noclass) |
-v |
verbose output. Each printed number is preceded by one of the |
|
words 'wrong', 'right', 'unknown', or 'speci c' depending |
|
on the result of the classi cation. |
-s |
statistic information containing wrong, right and not classi ed |
|
patterns. The network error is printed also. |
-c |
same as -s, but statistics for each output unit (class) is displayed. |
-m |
show confusion matrix (only works with -e 402040 or -e WTA) |
-i <file name> |
name of the 'result le' which is going to be analyzed. |
-o <file name> |
name of the le which is going to be produced by analyze. |
-e <function> |
de nes the name of the 'analyzing function'. |
|
Possible names are: 402040, WTA, band (description see below) |
-l <real value> |
rst parameter of the analyzing function. |
-h <real value> |
second parameter of the analyzing function. |
Starting analyze without any options is equivalent to: analyze -w -e 402040 -l 0.4 -h 0.6
13.2.1Analyzing Functions
The classi cation of the patterns depends on the analyzing function. 402040 stands for the '402040' rule. That means on a range from 0 to 1 h will be 0.6 (upper 40%) and l will be 0.4 (lower 40%). The middle 20% is represented by h ; l. The classi cation of the patterns will depend on h, l and other constrains (see 402040 below).
WTA stands for winner takes all. That means the classi cation depends on the unit with the highest output and other constrains (see WTA below). Band is an analyzing function that checks a band of values around the teaching output.
402040:
A pattern is classi ed correctly if:
the output of exactly one output unit is h.
the 'teaching output' of this unit is the maximum teaching output (> 0) of the pattern.
the output of all other output units is l.
A pattern is classi ed incorrectly if:
the output of exactly one output unit is h.
the 'teaching output' of this unit is NOT the maximum 'teaching output' of the pattern or there is no 'teaching output' > 0.

270 |
CHAPTER 13. TOOLS FOR SNNS |
the output of all other units is l.
A pattern is unclassi ed in all other cases. Default values are: l = 0:4 h = 0:6
WTA:
A pattern is classi ed correctly if:
there is an output unit with the value greater than the output value of all other output units (this output value is supposed to be a).
a > h.
the 'teaching output of this unit is the maximum 'teaching output' of the pattern (> 0).
the output of all other units is < a ; l.
A pattern is classi ed incorrectly if:
there is an output unit with the value greater than the output value of all other output units (this output value is supposed to be a).
a > h.
the 'teaching output' of this unit is NOT the maximum 'teaching output' of the pattern or there is no 'teaching output' > 0.
the output of all other output units is < a ; l.
A pattern is unclassi ed in all other cases. Default values are: l = 0:0 h = 0:0
Band:
A pattern is classi ed correctly if for all output units:
the output is >= the teaching output - l.
the output is <= the teaching output + h.
A pattern is classi ed incorrectly if for all output units:
theor output is < the teaching output - l.
the output is > the teaching output + h. Default values are: l = 0:1 h = 0:1
13.3bignet
The program bignet can be used to automatically construct complex neural networks. The synopsis is kind of lengthy, so when networks are to be constructed manually, the graphical version included in xgui is preferrable. If, however, networks are to be constructed automatically, e.g. a whole series from within a shell script, this program is the method of choice.

13.5. LINKNETS |
273 |
-o <output network file> [ options ]
It is possible to choose between the following options:
-inunits |
use copies of input units |
-inconnect <n> |
fully connect with <n> input units |
-direct |
connect input with output one-to-one |
-outconnect <n> |
fully connect to <n> output units |
-inunits and -inconnect may not be used together. -direct is ignored if no output networks are given.
If no input options are given (-inunits, -inconnect), the resulting network uses the same input units as the given input networks.
If -inconnect <n> is given, <n> new input units are created. These new input units are fully connected to the (former) input units of all input networks. The (former) input units of the input networks are changed to be hidden units in the resulting network. The newly created network links are initialized with weight 0:0.
To use the option -inunits, all input networks must have the same number of input units. If -inunits is given, a new layer input units is created. The number of new input units is equal to the number of (former) input units of a given input network. The new input units are connected by a one-to-one scheme to the (former) input units, which means, that every former input unit gets input activation from exactly one new input unit. The newly created network links are initialized with weight 1:0. The (former) input units of the input networks are changed to be special hidden units in the resulting network (incoming weights of special hidden units are not changed during further training). This connection scheme is usefull to feed several networks with similar input structure with equal input patterns.
Similar to the description of -inconnect, the option -outconnect may be used to create a new set of output units: If -outconnect <n> is given, <n> new output units are created. These new output units are fully connected either to the (former) output units of all output networks (if output networks are given) or to the (former) output units of all input networks. The (former) output units are changed to be hidden units in the resulting network. The newly created network links are initialized with weight 0:0.
There exsists no option -outunits (similar to -inunits), so far since it is not clear, how new output units should be activated by a xed weighting scheme. This heavily depends on the kind of used networks and type of application. However, it is possible to create a similar structure by hand, using the graphical user interface. Doing this, don't forget to change the unit type of the former output units to hidden.
By default all output units of the input networks are fully connected to all input units of the output networks. In some cases it is usefull, not to use a full connection but a one-by- one connection scheme. This is performed by giving the option -direct. To use the option -direct, the sum of all (former) output units of the input networks must equal the sum of all (former) input units of the output networks. Following the given succession of input and output networks (and the network dependent succession of input and output units),
274 |
CHAPTER 13. TOOLS FOR SNNS |
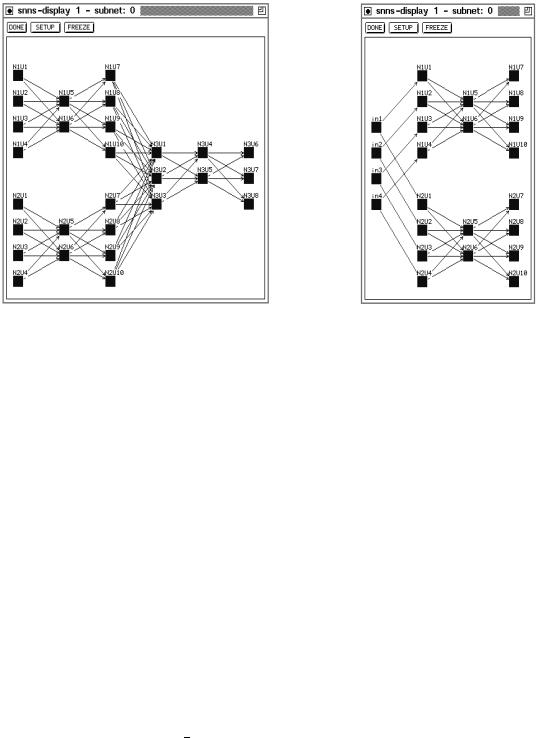
Figure 13.1: A 2-1 interconnection |
Figure 13.2: Sharing an input layer |
every (former) output unit of the input networks is connected to exactly one (fomer) input unit of the output networks. The newly created network links are initialized with weight 1:0. The (former) input units of the output networks are changed to be special hidden units in the resulting network (incoming weights of special hidden units are not changed during further training). The (former) output units of the input networks are changed to be hidden units. This connection scheme is usefull to directly feed the output from one (or more) network(s) into one (or more) other network(s).
13.5.1Limitations
linknets accepts all types of SNNS networks. But.... It is only tested to use feedforward type networks (multy layered networks, RBF networks, CC networks). It will de nately not work with DLVQ, ART, reccurent type networks, and networks with DUAL units.
13.5.2Notes on further training
The resulting networks may be trained by SNNS as usual. All neurons that receive input by a one-by-one connection are set to be special hidden. Also the activation function of these neurons is set to Act Identity. During further training the incoming weights to these neurons are not changed.
If you want to keep all weights of the original (sub) networks, you have to set all involved neurons to type special hidden. The activation function does not have to be changed!
Due to a bug in snns2c all special units (hidden, input, output) have to be set to their corresponding regular type. Otherwise the C-function created by snns2c will fail to produce
276 |
CHAPTER 13. TOOLS FOR SNNS |
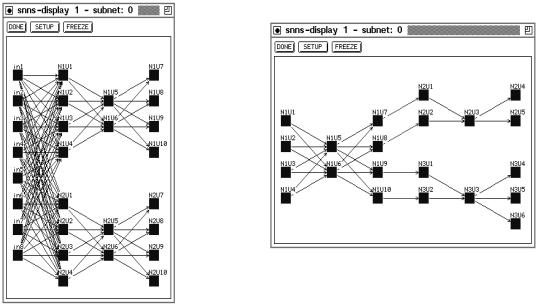
hidden units. Generated by: linknets -innets 4-2-4.net 4-2-4.net -o result.net -inconnect 8
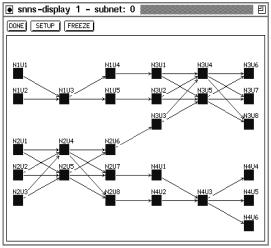
Figures 13.4 and 13.5 show examples of one-to-one connections. In gure 13.5 the links have been created following the given succession of networks. The link weights are set to 1.0. Former input units of the output networks have become special hidden units. Former output units of the input networks are now hidden units. This network was generated by: linknets -innets 2-1-2.net 3-2-3.net -outnets 3-2-3.net 2-1-3.net -o result.net -direct
Figure 13.5: Two input networks one-by-one connected to two output networks
13.6Convert2snns
In order to work with the KOHONEN tools in SNNS, a pattern le and a network le with a special format are necessary.
Convert2snns will accomplish three important things:
Creation of a 2-dimensional Kohonen Feature Map with n components
Weight les are converted in a SNNS compatible .net le
A le with raw patterns is converted in a .pat le
When working with convert2snns, 3 les are necessary:
1.A control le, containing the con guration of the network
2.A le with weight vectors
3.A le with raw patterns
13.7. FEEDBACK-GENNET |
277 |
13.6.1Setup and Structure of a Control, Weight, Pattern File
Each line of the control le begins with a KEYWORD followed by the respective declaration. The order of the keywords is arbitrary.
Example of a control le:
PATTERNFILE eddy.in |
** |
|
WEIGHTFILE eddy.dat |
|
|
XSIZE 18 |
|
|
YSIZE 18 |
|
|
COMPONENTS 8 |
|
|
PATTERNS 47 |
** |
|
For creation of a network le you need at least the statements marked |
and for the .pat |
|
le additionally the statements marked **. |
|
|
Omitting the WEIGHTFILE will initialize the weights of the network with 0.
The WEIGHTFILE is a simple ASCII le, containing the weight vectors row by row. The PATTERNFILE contains in each line the components of a pattern.
If convert2snns has nished the conversion it will ask for the name of the network and pattern les to be saved.
13.7Feedback-gennet
The program feedback-gennet generates network de nition les for fully recurrent networks of any size. This is not possible by using bignet.
The networks have the following structure:
-input layer with no intra layer connections
-fully recurrent hidden layer
-output layer: connections from each hidden unit to each output unit
AND
optionally fully recurrent intra layer connections in the output layer
AND
optionally feedback connections from each output unit to each hidden unit.
The activation function of the output units can be set to sigmoidal or linear. All weights are initialized with 0.0. Other initializations should be performed by the init functions in SNNS.
Synopsis: feedback-gennet example:
