

UTF-8
Материал из Википедии — свободной энциклопедии
Перейти к: навигация, поиск
UTF-8 (от англ. Unicode Transformation Format, 8-bit — «формат преобразования Юникода, 8-битный») — распространённая кодировка символов Юникода, совместимая с ASCII и имеющая официальный статус. Нашла широкое применение в операционных системах и веб-пространстве[1]. Формат UTF-8 был изобретён 2 сентября 1992 года Кеном Томпсоном и Робом Пайком и реализован в Plan 9.[2]. Сейчас стандарт UTF-8 официально закреплён в документах RFC 3629 и ISO/IEC 10646 Annex D.
Одним из преимуществ является совместимость с ASCII — любые их 7-битные символы отображаются как есть, а остальные выдают пользователю мусор (шум). Поэтому в случае, если латинские буквы и простейшие знаки препинания (включая пробел) занимают существенный объём текста, UTF-8 даёт выигрыш по объёму по сравнению с UTF-16.[3][4]
Замечание: Символы, закодированные в UTF-8, могут быть длиной до шести байт, однако стандарт Unicode не определяет символов выше 0x10ffff, поэтому символы Unicode могут иметь максимальный размер в 4 байта в UTF-8.
|
Содержание
|
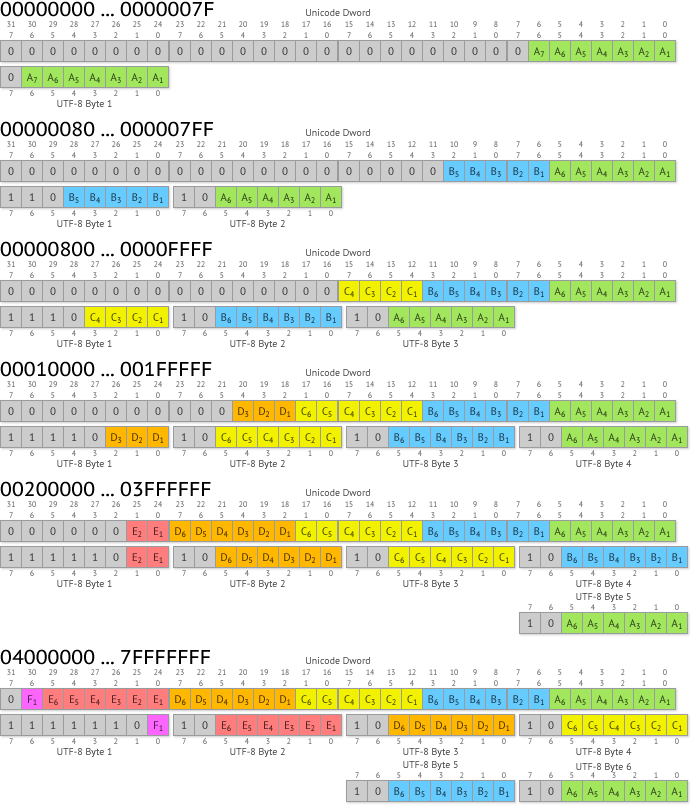
Принцип кодирования
Кодировка UTF-8 использует значения конкретных битов и учитывает расположение битовых блоков. Поэтому она может быть полноценно проиллюстрирована очевидным графическим образом. Если вам требуется быстро реализовать кодирование и раскодирование, то можете воспользоваться следующей схемой:
Примеры последовательностей
В таблице ниже значения представлены в шестнадцатиричной системе счисления. Порядок байт в значении: Little Endian. На практике для каждого значения выбирается представление с минимальной длиной байт (большие — не рациональны).
|
Значение |
1 байт |
2 байта |
3 байта |
4 байта |
5 байт |
6 байт |
|
0000 (NUL) |
00 |
C0 80 |
E0 80 80 |
F0 80 80 80 |
F8 80 80 80 80 |
FC 80 80 80 80 80 |
|
0073 (малая латинская «s») |
73 |
C1 B3 |
E0 81 B3 |
F0 80 81 B3 |
F8 80 80 81 B3 |
FC 80 80 80 81 B3 |
|
041A (большая кириллическая «К») |
- |
D0 9A |
E0 90 9A |
F0 80 90 9A |
F8 80 80 90 9A |
FC 80 80 80 90 9A |
|
0BF5 («௵» — год на тамильском) |
- |
- |
E0 AF B5 |
F0 80 AF B5 |
F8 80 80 AF B5 |
FC 80 80 80 AF B5 |
|
26218 («𦈘» — китайский иероглиф) |
- |
- |
- |
F0 A6 88 98 |
F8 80 A6 88 98 |
FC 80 80 A6 88 98 |
|
10FFFF (максимальный код Unicode) |
- |
- |
- |
F4 8F BF BF |
F8 84 8F BF BF |
FC 80 84 8F BF BF |
|
ABCDEF (произвольное 5-байтовое) |
- |
- |
- |
- |
F8 AA BC B7 AF |
FC 80 AA BC B7 AF |
|
7FFFFFFF (максимальный код UCS-4) |
- |
- |
- |
- |
- |
FD BF BF BF BF BF |
Диапазоны кодирования
В таблице ниже представлены диапазоны кодирования символов Unicode в UTF-8.
|
Коды символов Unicode (HEX) |
Размер в UTF-8 |
Представленные классы символов |
|
00000000 — 0000007F |
1 байт |
ASCII, в том числе латинский алфавит, простейшие знаки препинания и арабские цифры |
|
00000080 — 000007FF |
2 байта |
кириллица, расширенная латиница, арабский, армянский, греческий, еврейский и коптский алфавит; сирийское письмо, тана, нко; МФА; некоторые знаки препинания |
|
00000800 — 0000FFFF |
3 байта |
все другие современные формы письменности, в том числе грузинский алфавит, индийское, китайское, корейское и японское письмо; сложные знаки препинания; математические и другие специальные символы |
|
00010000 — 001FFFFF |
4 байта |
музыкальные символы, редкие китайские иероглифы, вымершие формы письменности |
|
00200000 — 03FFFFFF |
5 байт |
не используется в Unicode |
|
04000000 — 7FFFFFFF |
6 байт |
не используется в Unicode |
Отличительные значения байтов
Отличительные значения байтов представлены для использования в алгоритмах автоматического определения кодировки текста. Первичным признаком можно считать BOM, которая повышает вероятность использования той или иной кодировки (см. отдельную статью). Следует отметить, что UTF-8 поддерживает кодирование 31-битных кодов UCS-4. Если речь касается символов Unicode, то 5-ти и 6-тибайтовые значения оказываются сильно маловероятными.
Все значения представлены в 16-ричной системе счисления. Под значением «сильно маловероятен» в колонке «статус» следует рассматривать использование кодировщика, который не отбрасывает лидирующие нули.
|
Значение байта |
Статус |
Значение |
|
00..7F |
без сомнений |
ASCII-символы. |
|
80 |
сильно маловероятен |
Не отброшены лидирующие нули у двухбайтового символа. |
|
81..BF |
без сомнений |
Любой не первый байт символа. |
|
C0 |
маловероятен |
Если не отброшены лидирующие нули у многобайтового символа, то ряд этих байтов также бестолков. |
|
C1..DF |
без сомнений |
Первый байт двухбайтового символа. |
|
E0 |
сильно маловероятен |
Не отброшены лидирующие нули у трёхбайтового символа. |
|
E1..EF |
без сомнений |
Первый байт трёхбайтового символа. |
|
F0 |
сильно маловероятен |
Не отброшены лидирующие нули у четырёхбайтового символа. |
|
F1..F7 |
без сомнений |
Первый байт четырёхбайтового символа. |
|
F8 |
сильно маловероятен |
Не отброшены лидирующие нули у пятибайтового символа. |
|
F9..FB |
без сомнений |
Первый байт пятибайтового символа. |
|
FC |
сильно маловероятен |
Не отброшены лидирующие нули у шестибайтового символа. |
|
FD |
без сомнений |
Первый байт шестибайтового символа. |
|
FE..FF |
однозначно невозможны |
Невозможны в UTF-8 исходя из принципа кодирования. У первого байта символа устанавливается столько старших битов, сколько байтов отводится под символ. Их конец обозначается терминальным битом 0, а оставшиеся биты соответствуют старшим битам значения. Байты 254 и 255 в двоичной системе: 1111111102 и 1111111112. Отсюда очевидно, что у них просто не остаётся битов для значения. |
UTF-8 и ошибки кодирования/раскодирования
Примеры ниже приведены для быстрой ориентации в случаях не корректного раскодирования текста (так называемые кракозябры).
Так выглядит фраза «Человек сейчас увидит лишь то, что ожидает увидеть.» если она воспринята раскодировщиком в кодировке Windows-1251, а не UTF-8:
Человек сейчас увидит лишь то, что ожидает увидеть.
Фраза «Человек сейчас увидит лишь то, что ожидает увидеть.» при двойном кодировании UTF-8 в UTF-8:
Человек сейчас увидит лишь то, что ожидает увидеть.