

3. Работа с кодом
3.1. Загрузка первичных данных
Для начала работы с уже существующей базой данных, мы подключаем библиотеки для работы с информацией: pandas - библиотека для работы с табличными данными, numpy - библиотек для работы с математическими функциями, matplotlib - библиотека для визуализации данных, plotly - библиотека для визуализации данных. Для убеждения в том, что данные библиотеки успешно были импортированы, напишем некоторые команды, которые будут продемонстрированы в пункте 3.2. В таблице 2, показана команда, позволяющая считать содержимое файла “songs_normalize.csv”, чтобы убедиться в наличие информации, будет использована команда
print(df) |
Таб. 1. Вывод содержимого базы данных
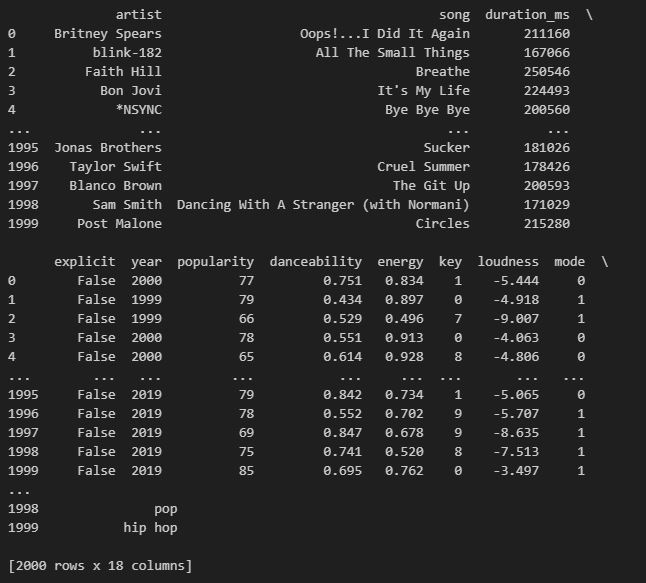
Рисунок 1. Содержимое базы данных
3.2. Запросы к базе данных
Для дальнейшего анализа и визуализации содержимого базы данных, нужно отредактировать ее саму, например, очистить от дубликатов, получить информацию о содержимом и так далее. Для удаления дубликатов, сначала узнаем их количество (рисунок 2), а затем используя команду df.drop_duplicates(inplace=True)очищаем от дубликатов. В конечном счете мы получим базу данных в табличном виде, готовую к изъятию информации для работы с ней. В данном пункте мы удалили дубликаты из столбцов и строк, а также получили информацию о количестве дубликатов, хранившихся в дата фрэйме.
Также использую команду df.describe()(рисунок 4) мы получили детальную информацию, такую как минимальное и максимальное значение, медиана, среднее значение и много подобных данных. В последующих строчках кода была использована переменная songs_per_years (рисунок 3), которая дает возможность узнать количество выпущенных песен за текущий год.
df = pd.read_csv('songs_normalize.csv') #Считываем информацию из файла "songs_normalize" |
Таб. 2. Загрузка базы данных для дальнейшей работы

Рисунок 2. Количество дубликатов в таблице

Рисунок 3. Количество песен по годам

Рисунок 4. Пример использование кода df.describe()
3.3. Визуализация данных
В данном пункте мы будем использовать визуализацию в виде графиков, чтобы показать, как можно применить существующие данные, а также показать умение анализировать информацию. Для построения графиков в языке программирования Python существует библиотеки plotly и matlib. В этом разделе мы построим такие графики, как гистограмма, тепловая диаграмма, график распределения, а также обычная диаграмма. Для точного построения и удобной визуализации вызывается команда iplot, используются параметры, при помощи которых можно: подписать оси(labels = dict(index=’x’, value=’y’), выбор внешнего вида(px.bar), цвет таблиц(color_discrete_sequence). Все эти параметры в совокупности влияют на внешний вид и содержимое столбцов и графика в целом.
Первый график, который был построен, отображает количество выпущенных популярных песен за год. Как мы можем увидеть на рисунке 5, начиная с 1999 года по 2019 среднее количество популярных песен примерно одинаково. Поскольку мы строим гистограмму, был задействован параметр px.bar.
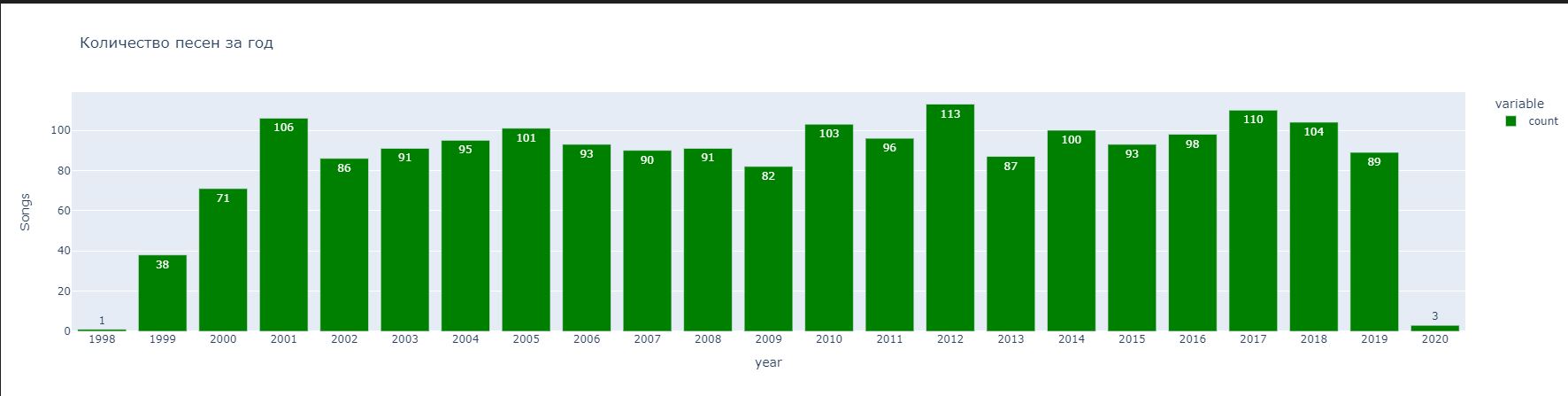
Рисунок 5. Гистограмма, отображающая количество выпущенных популярных песен за год
Следующий график именуется, как тепловая диаграмма, позволяет отобразить концентрацию популярных песен у первых 10 популярных исполнителей. Для реализации данного метода используется параметр px.scatter, также в коде используется метод, который до этого не был использован, а именно size_max, который влияет на размер кругов на графике рисунок 6.
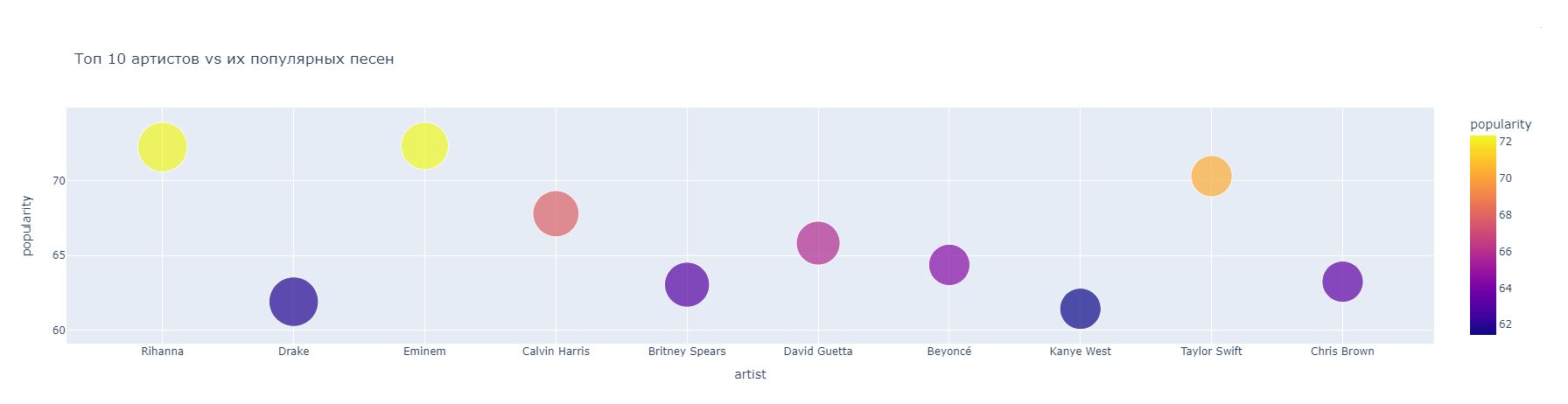
Рисунок 6. Тепловая диаграмма, сравнивающая топ-10 исполнителей с популярными песнями
Третий график, показывает среднее изменение продолжительность песни по годам. Как мы можем заметить на рисунке 7, каждый из моментов времени соединён отрезком, что позволяет обратить внимание, что продолжительность песни изменяется постепенно, а не резко. Для реализации данного графика, нам понадобилось обратиться к информации, которая содержится в столбцах “duration_ms” и “year”, в которых хранится информация о длительности песни и годе выпуска, соответственно. Следующим шагом мы группируем информацию, содержащуюся в столбце “year” и собираем среднее значение по годам, а также удаляем индекс у значений.
В результате мы получаем график, изображенный на рисунке 6. Анализируя его, мы можем заметить, что с годами, средняя продолжительность песен уменьшается и песни становятся короче. Так как, если в 1999 году песня длилась еще 4:13 минуты, то в 2019 году популярная песня может длиться всего 3 минуты и 16 секунд.
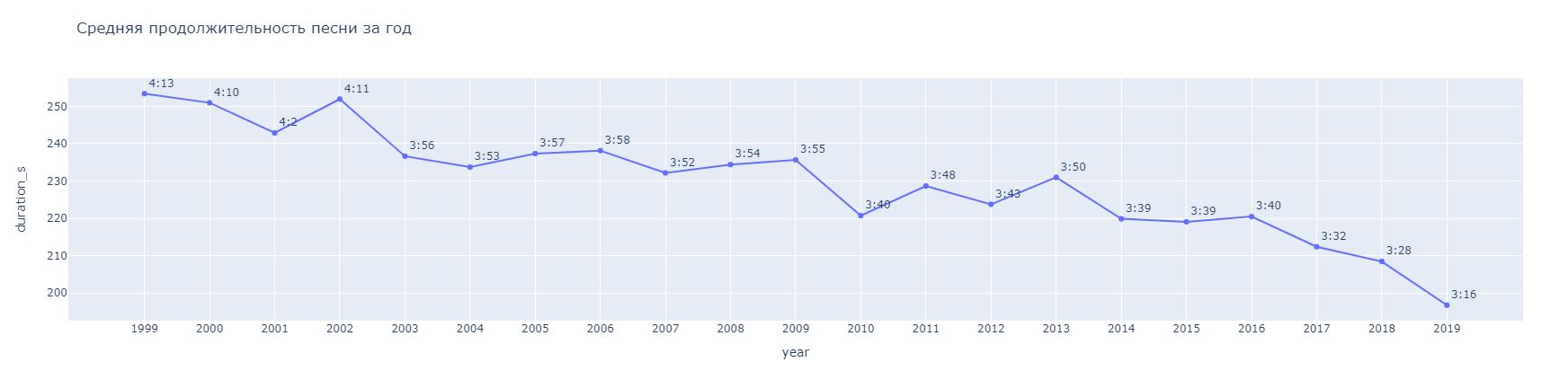
Рисунок 7. График распределения средней продолжительности песни
Следующие построенные графики является гистограммами, отображают количество песен по популярности и различным коэффициентам из базы данных. Для построения данных диаграмм используется px.histogram,причем информацию по каждому графику мы берем в цикле.
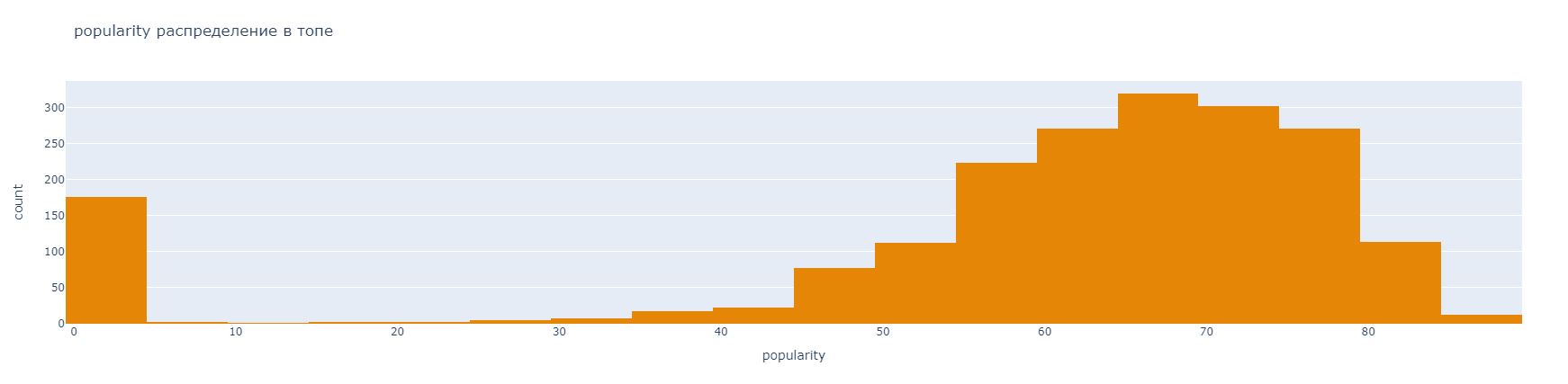 Рисунок
8. Диаграмма, отображающая распределение
количества песен относительно их
популярности
Рисунок
8. Диаграмма, отображающая распределение
количества песен относительно их
популярности
По данной гистограмме, что больше всего песен обладает рейтингом 60-70.
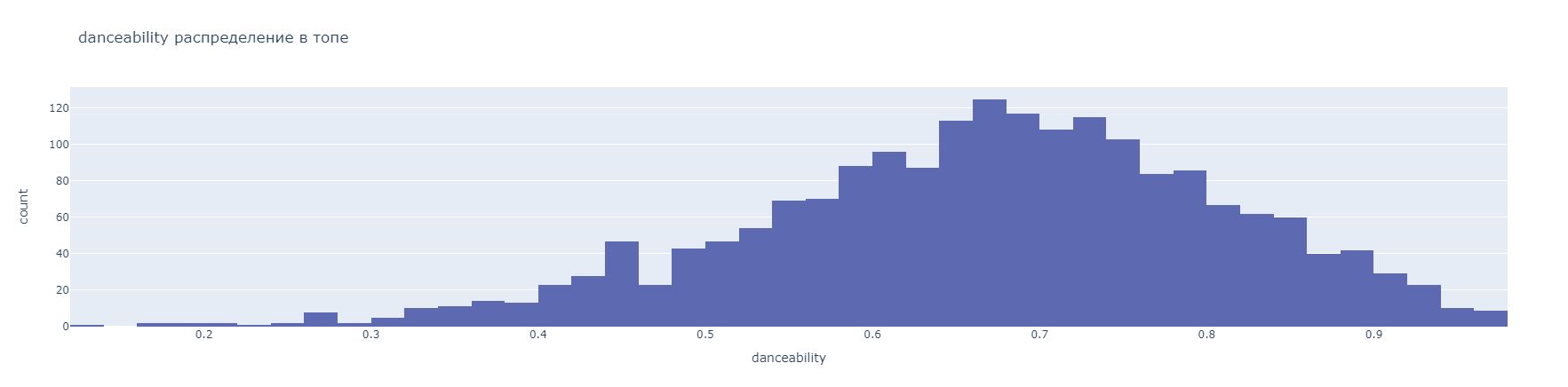
Рисунок 9. Диаграмма, отображающая распределение количества песен относительно их коэффициента танцевальности
Используя этот график, можно заметить, что самая большая концентрация песен находится на промежутке 0.6 – 0.8.
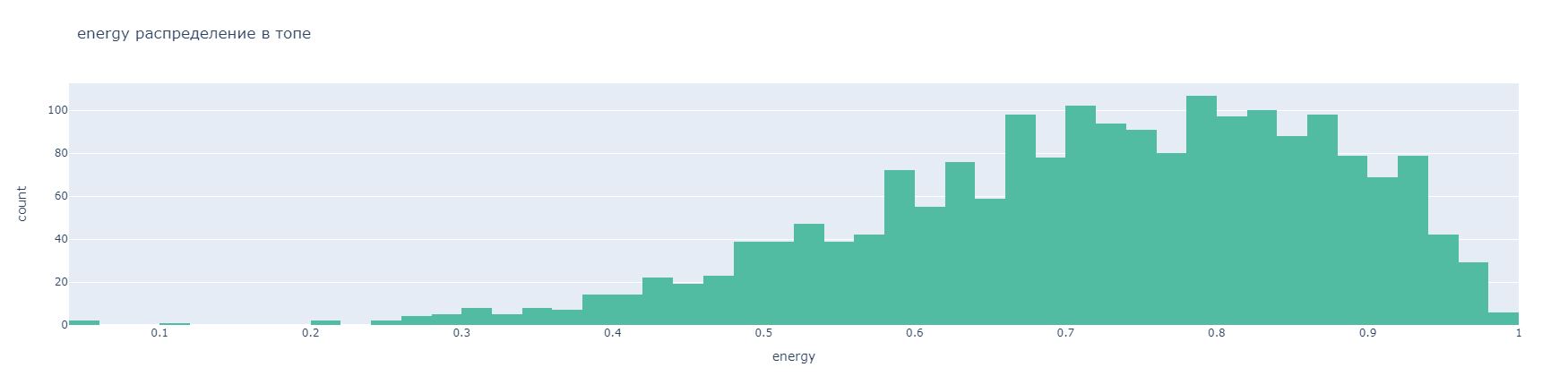
Рисунок 10. Диаграмма, отображающая распределение количества песен относительно ее коэффициента энергичности
На этом графике, количество самых энергичным песен находится на промежутке 0.7 – 0.8.
Следующим типом графиков является, диаграмма на которой показывается сравнение количества песен, в которых содержится нецензурная лексика и не содержится, за каждый год. Для реализации потребовалось создать два цвета, а также для параметра, определяющего данные которые хранятся на оси Оy, задать какая информация и какой цвет соответствует пункту “Explicit”, а также пункту “Clean”. Реализацию данного кода можно увидеть на рисунке 11.
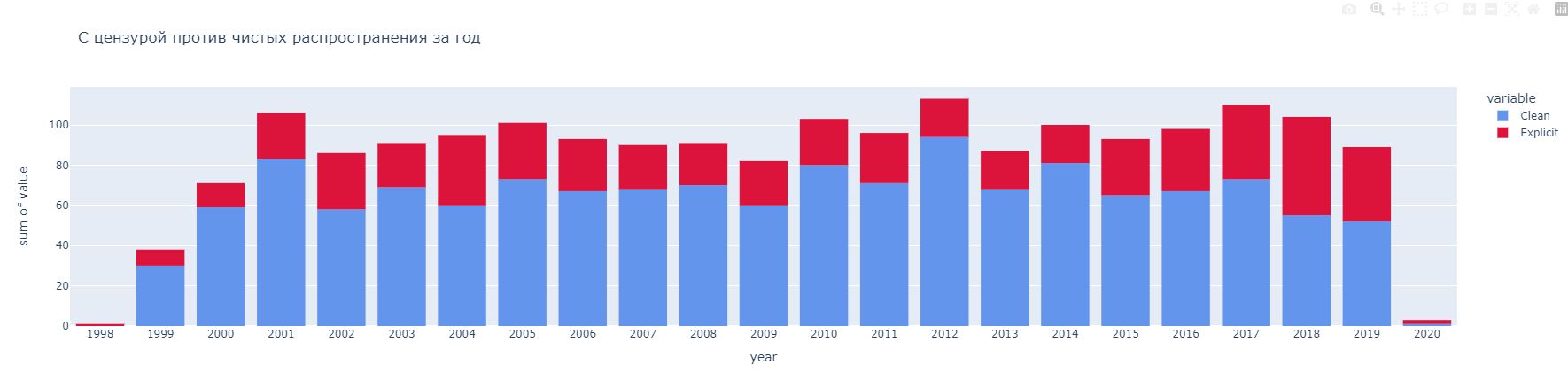
Рисунок 11. График отображения зависимости
Анализируя данный график, можно сказать, что в каждый год преобладают песни без нецензурной лексики, нежели чем с нецензурной лексикой.