

Лаба 5
.docxМИНИСТЕРСТВО ЦИФРОВОГО РАЗВИТИЯ, СВЯЗИ И МАССОВЫХ КОММУНИКАЦИЙ
Ордена Трудового Красного Знамени
Федеральное государственное бюджетное образовательное учреждение высшего образования
«Московский технический университет связи и информатики»
Кафедра «Математическая кибернетика и информационные технологии»
Дисциплина «Большие данные»
Лабораторная работа №5
Москва, 2024
Содержание
1 Цель работы 3
2 Ход работы 3
3 Вывод 10
1 Цель работы
Получить навыки работы с Spark.
2 Ход работы
Устанавливаем библиотеку pyspark (рисунок 1).

Рисунок 1 – Установка библиотеки pyspark
Создаём сессию Spark. Чтобы создать SparkSession, используем метод builder() (рисунок 2).
getOrCreate() возвращает уже существующий SparkSession; если он не существует, создается новый SparkSession.
appName() используется для установки имени приложения.
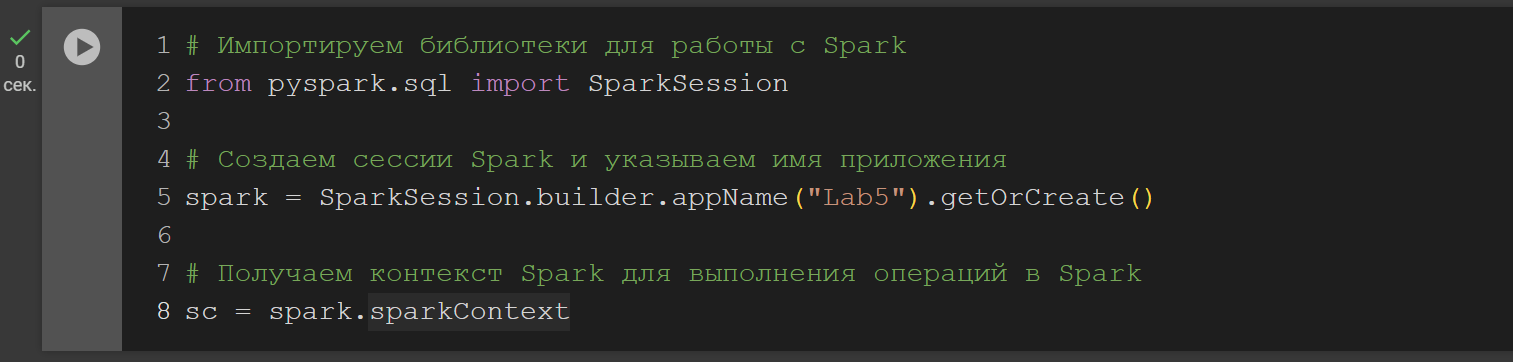
Рисунок 2 – Создание сессии
Задача 1
При подсчёте отсеять пунктуацию и слова короче 3 символов. При фильтрации можно использовать регулярку: re.sub(u"\\W+", " ", x.strip(), flags=re.U). RDD - набор данных, распределённый по партициям.
Filter() – фильтрует элементы RDD по определенному условию.
Map() – преобразует каждый элемент RDD в новый элемент.
FlatMap() – преобразует каждый элемент RDD в несколько элементов.
reduceByKey() - объединение значения для каждого ключа.
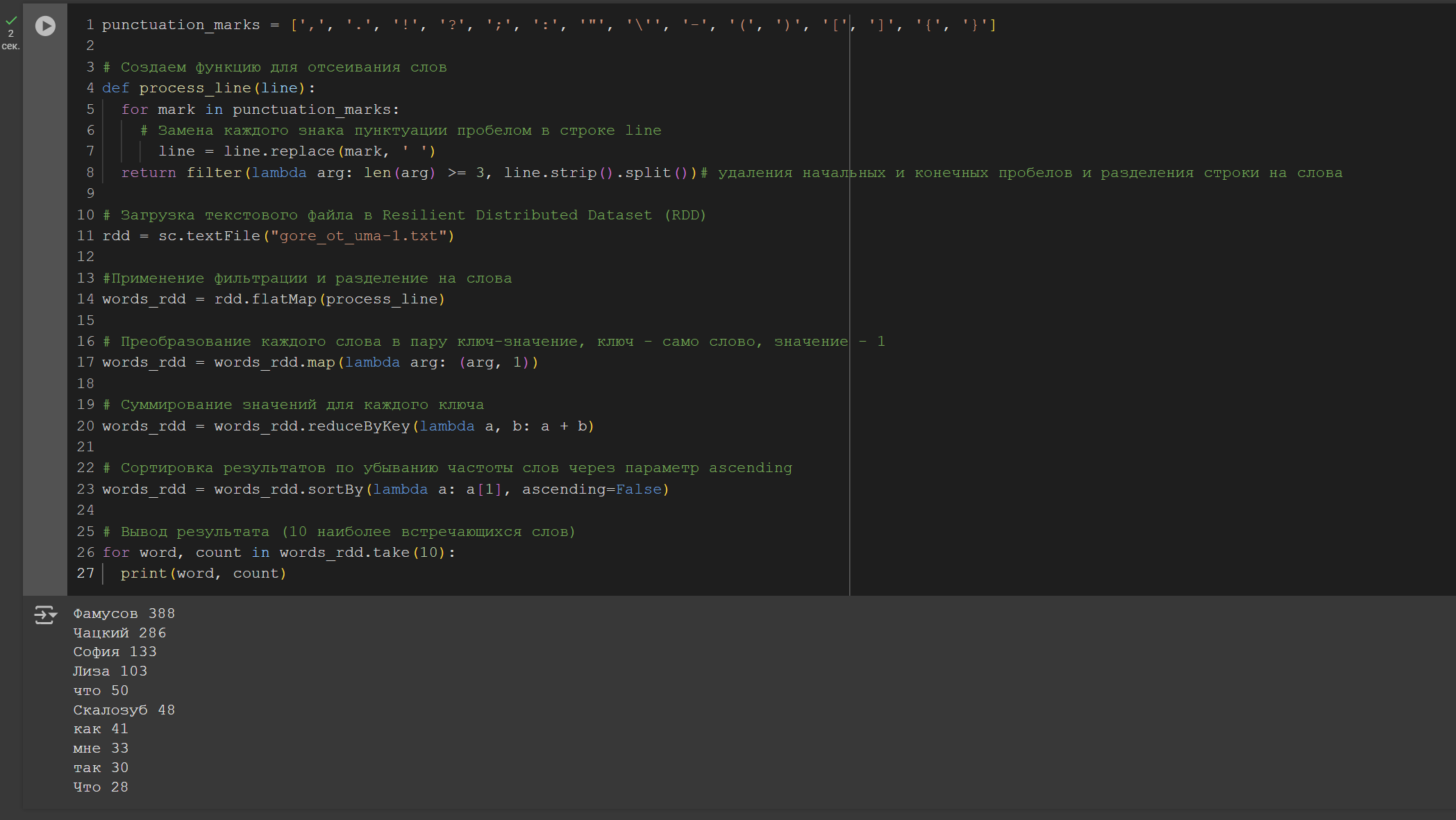
Рисунок 3 – Код и результат выполнения задачи 1
Задача 2
Считать только имена собственные. Именами собственными будем считать такие слова, у которых 1-я буква заглавная, остальные – прописные (рисунок 4).
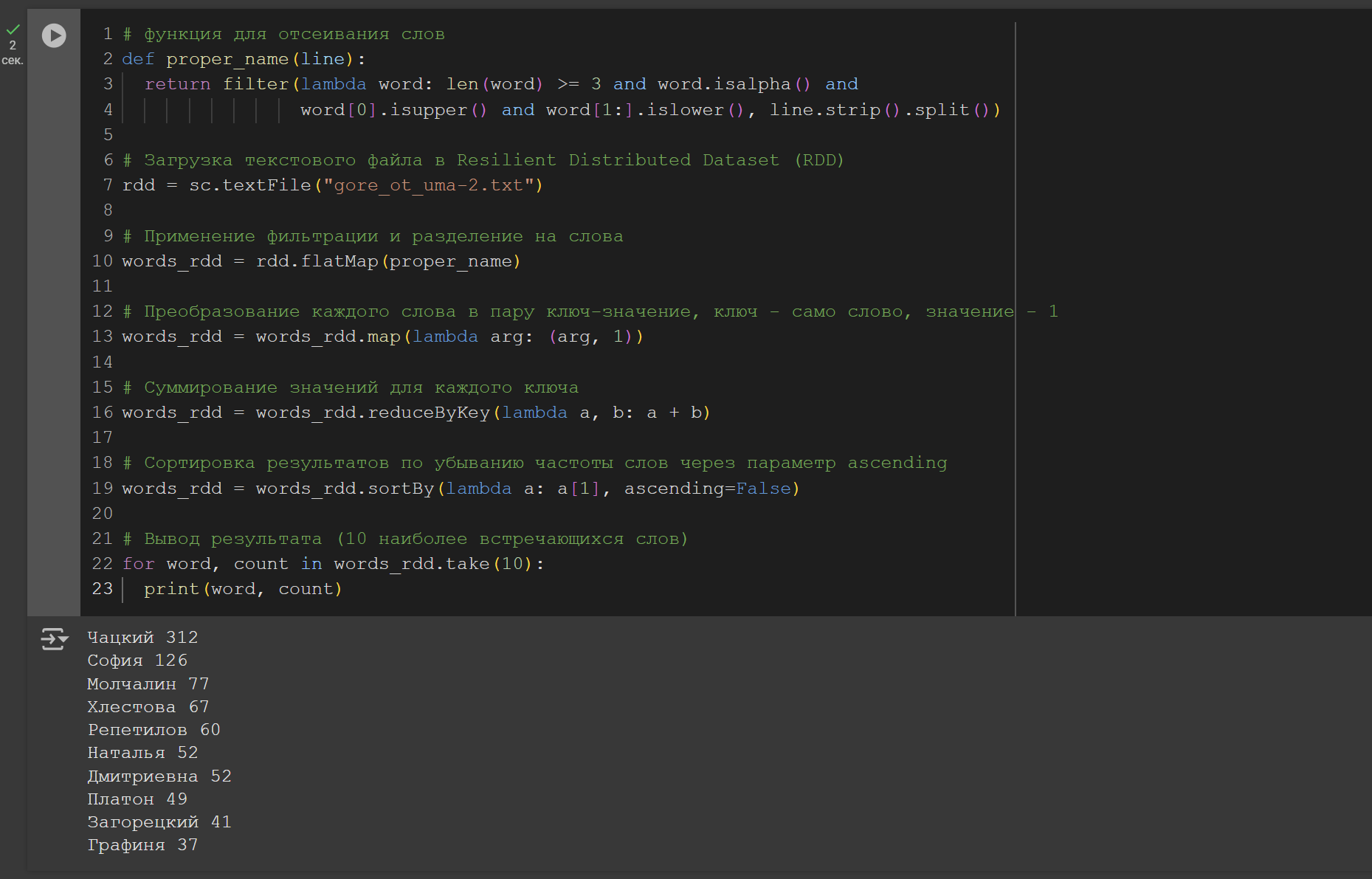
Рисунок 4 – Код и результат выполнения задачи 2
Задача 3
Переделайте задачу 2 так, чтоб кол-во имён собственных вычислялось с помощью аккумулятора (рисунок 5).
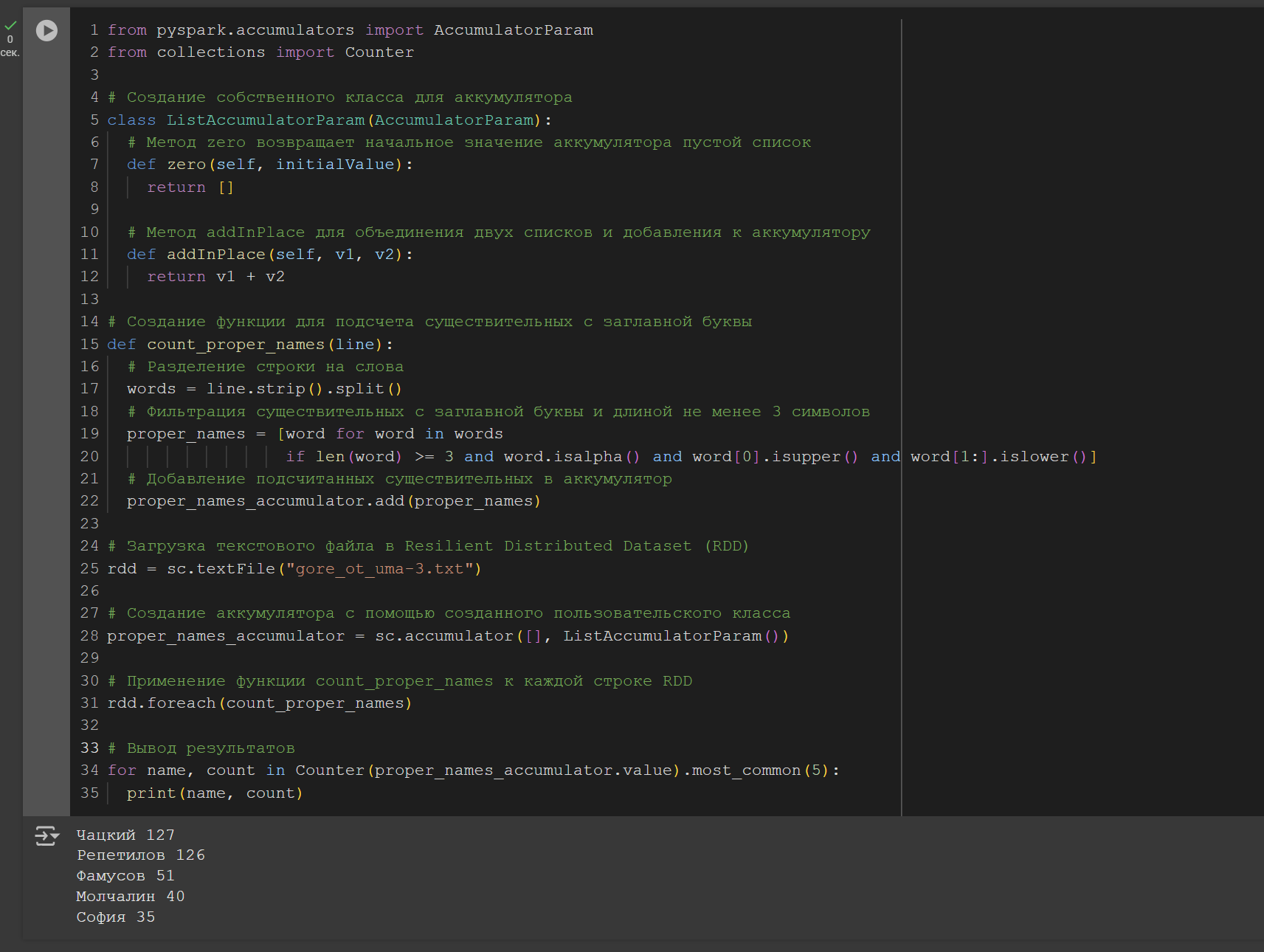
Рисунок 5 – Код и результат выполнения задачи 3
Задания
1. Считать csv-файл в формате DataFrame
2. Вывести первые n-записей
3. Применить фильтр к данным
4. Вывести данные с группировкой
5. Вывести данные с группировкой и агрегированием
«Header» - Определяет наличие заголовка в CSV файле. Если значение True, то первая строка файлов CSV будет использована в качестве заголовка столбцов.
«inferSchema» - Определяет автоматическое определение типов данных столбцов на основе данных в CSV файле. Если значение True, то PySpark будет пытаться автоматически определить типы данных для каждого столбца.

Рисунок 6 – Решение задания 1
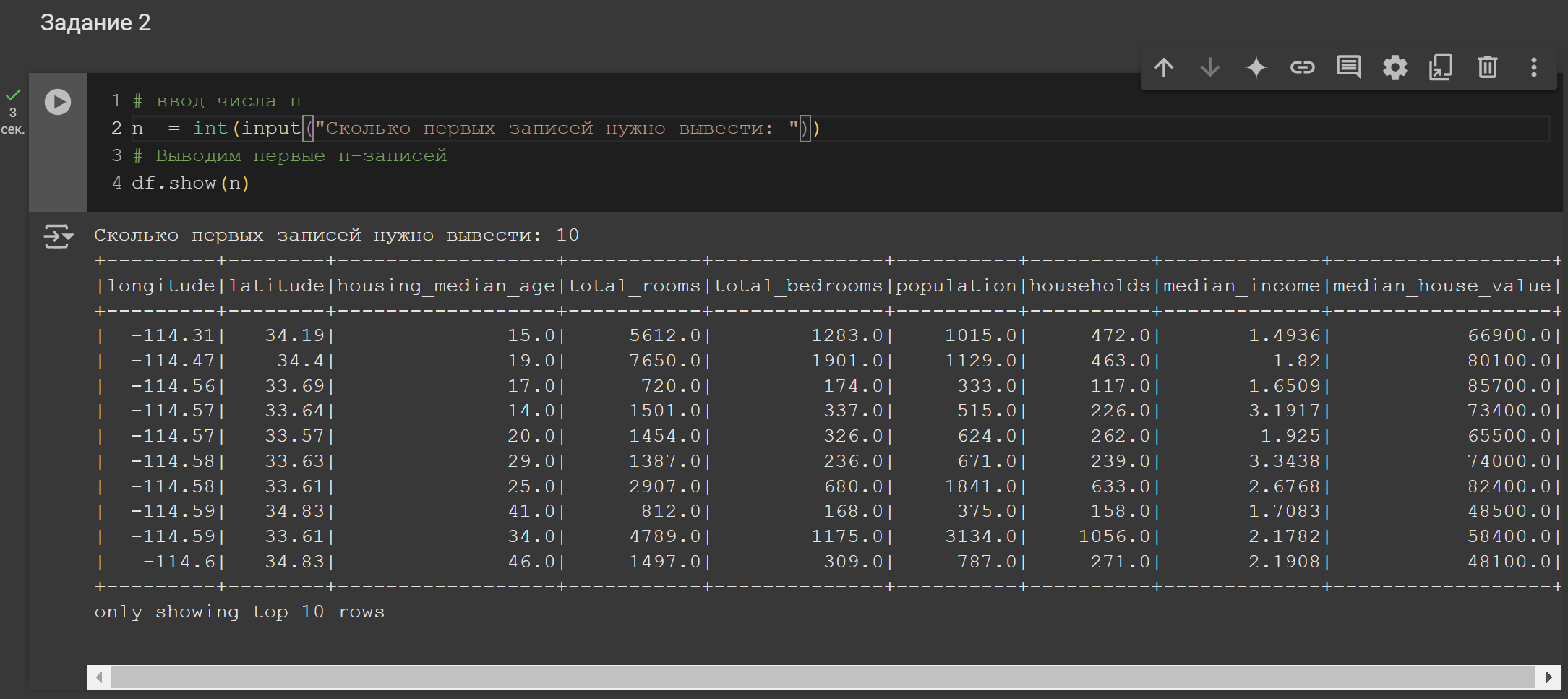
Рисунок 7 – Решение задания 2
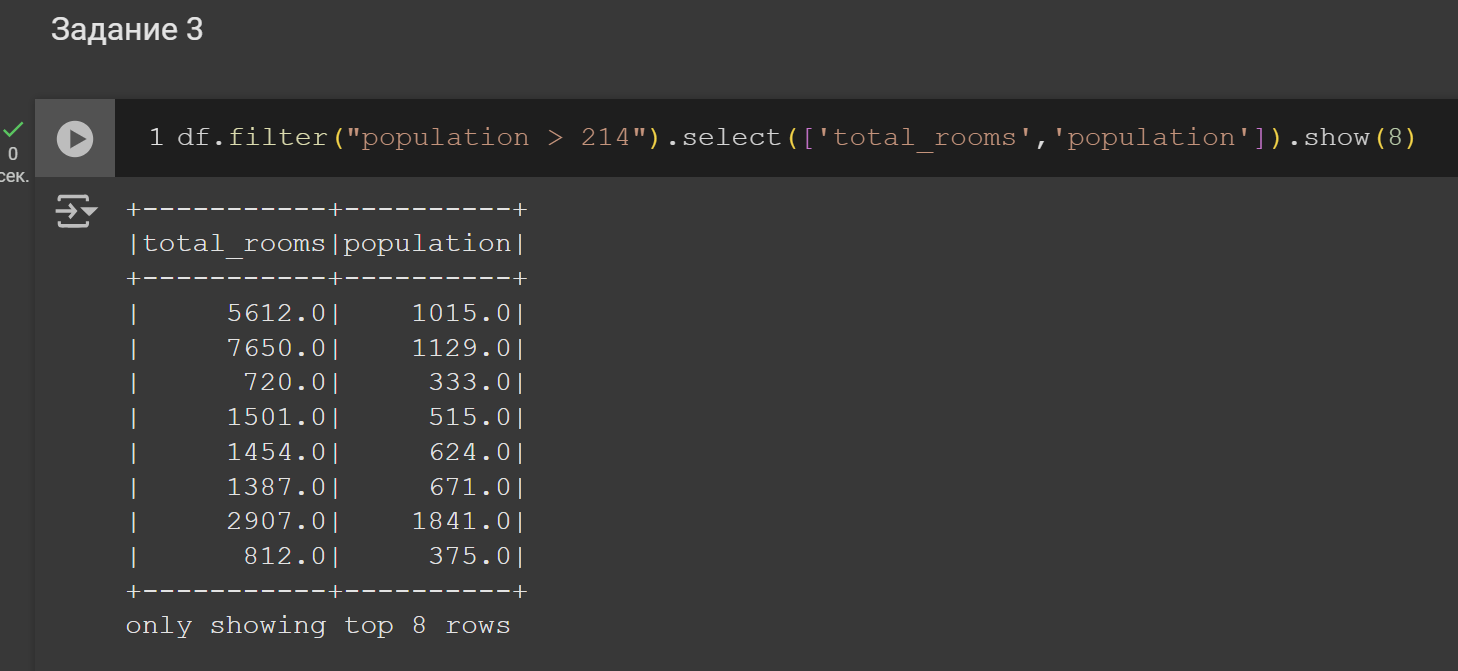
Рисунок 8 – Решение задания 3
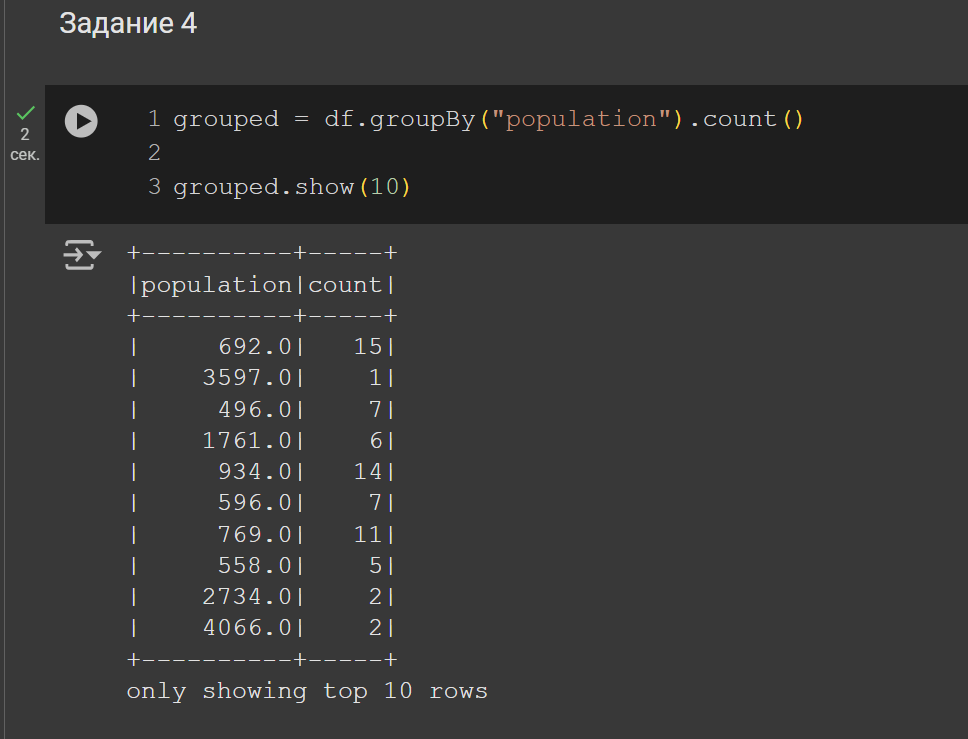
Рисунок 9 – Решение задания 4
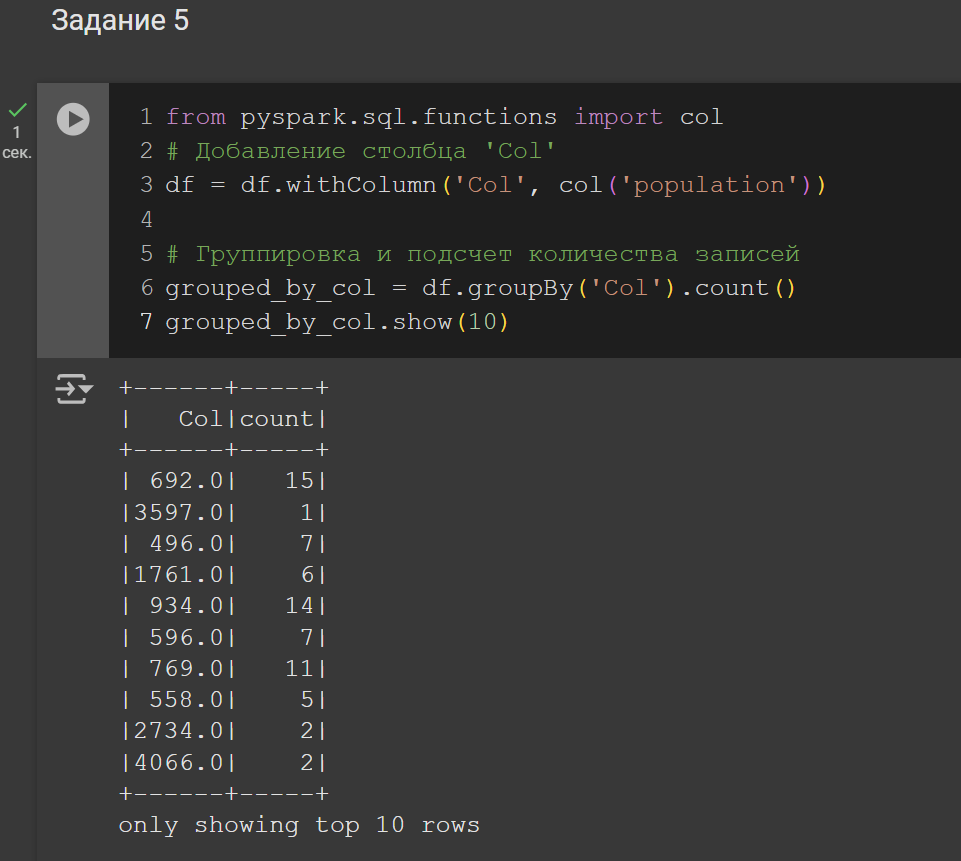
Рисунок 10 – Решение задания 5
3 Вывод
Получил навыки работы с Spark.