

лаба2 ООП
.docxМИНОБРНАУКИ РОССИИ
САНКТ-ПЕТЕРБУРГСКИЙ ГОСУДАРСТВЕННЫЙ
ЭЛЕКТРОТЕХНИЧЕСКИЙ УНИВЕРСИТЕТ
«ЛЭТИ» ИМ. В.И. УЛЬЯНОВА (ЛЕНИНА)
КАФЕДРА САПР
Практическая работа № 2
по дисциплине
«Объектно-ориентированное программирование»
Студентки гр. 3352 |
|
|
Преподаватель |
|
|
Санкт-Петербург
2024
Задание
Разработать консольное приложение для работы с двумя файлами-справочниками городов в формате xml и csv. Приложение ожидает ввода пути до файла и отображает сводную статистику о дублирующихся записях, количестве зданий с определенным числом этажей и время обработки файла. После вывода статистики приложение должно запросить новый путь до файла. Выход должен завершаться только по команде завершения работы.
Спецификация программы
Описание реализованных классов:
Address
Этот класс представляет собой адрес и содержит следующие методы и атрибуты:
Атрибуты:
city: название города.
street: название улицы.
house: номер дома (преобразуется в целое число).
floor: номер этажа (преобразуется в целое число).
Методы:
__init__(self, city, street, house, floor): конструктор, инициализирующий атрибуты объекта.
__str__(self): метод, возвращающий строковое представление адреса в удобном формате.
as_key(self): метод, возвращающий кортеж, который может быть использован в качестве ключа для поиска дубликатов адресов.
FileParser
Этот класс отвечает за чтение данных из файлов и парсинг адресов:
Атрибуты:
file_path: путь к файлу, который нужно прочитать.
addresses: список объектов Address, которые будут созданы из данных файла.
Методы:
__init__(self, file_path): конструктор, инициализирующий путь к файлу и список адресов.
parse(self): метод, определяющий тип файла (CSV или XML) и вызывающий соответствующий метод парсинга.
parse_csv(self): метод, который читает данные из CSV-файла и создает объекты Address.
parse_xml(self): метод, который читает данные из XML-файла и создает объекты Address.
Класс Statistics
Этот класс отвечает за вычисление статистики на основе списка адресов:
Атрибуты:
addresses: список объектов Address, переданный в конструктор.
Методы:
__init__(self, addresses): конструктор, инициализирующий список адресов.
find_duplicates(self): метод, который находит дубликаты адресов и возвращает их количество.
floor_statistics(self): метод, который собирает статистику по этажам для каждого города.
print_statistics(self, duplicates, floor_stats): метод, который выводит статистику дубликатов и статистику по этажам на экран.
Application
Этот класс управляет основным потоком выполнения программы:
Методы:
run(self): метод, который запускает основной цикл приложения. Он запрашивает у пользователя путь к файлу, обрабатывает его, создает объекты FileParser и Statistics, а затем выводит результаты.
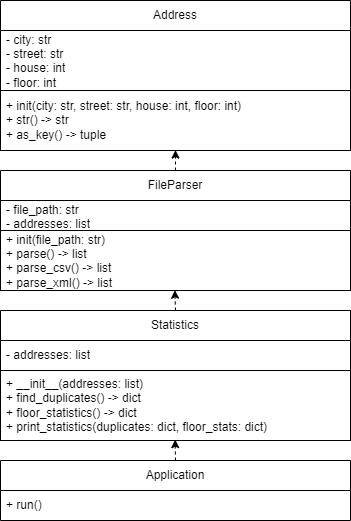
Рисунок 1- UML-диаграмма классов.
Описание интерфейса пользователя программы
При запуске программы, пользователю предлагается ввести путь до файла, который требуется просмотреть (рисунок 2). После того, как программа завершит обработку, в консоли отображается информация о дублирующихся записях, а также статистика по количеству домов с определенным количеством этажей в каждом городе.
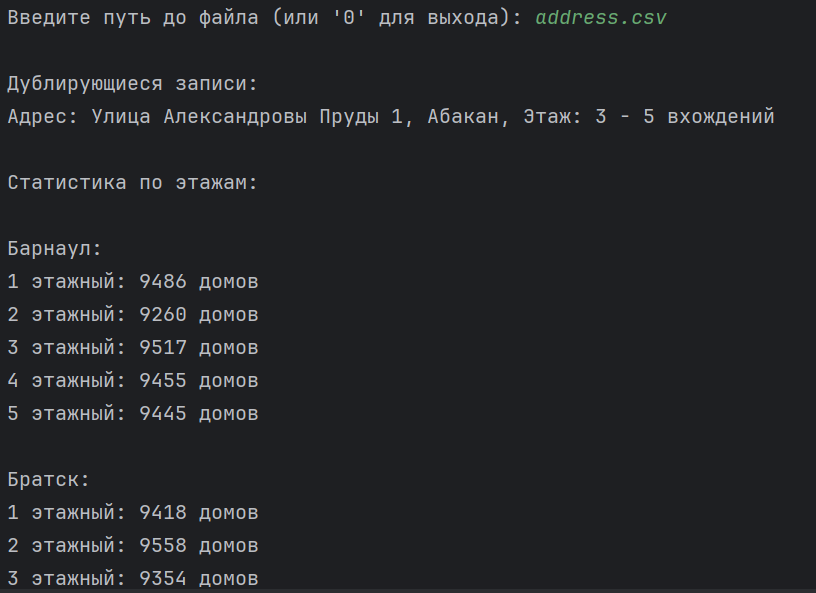
Рисунок 2 – ввод пути до файла
После вывода данной статистики отображается время, за которое был обработан файл. В первом случае рассматривался файл в формате csv (рисунок 3).
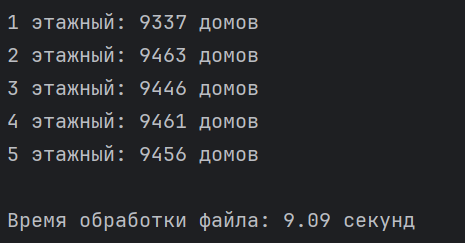
Рисунок 3 – время обработки csv файла
Ту же обработку и получение результатов можно наблюдать для файла в формате xml (рисунок 4).
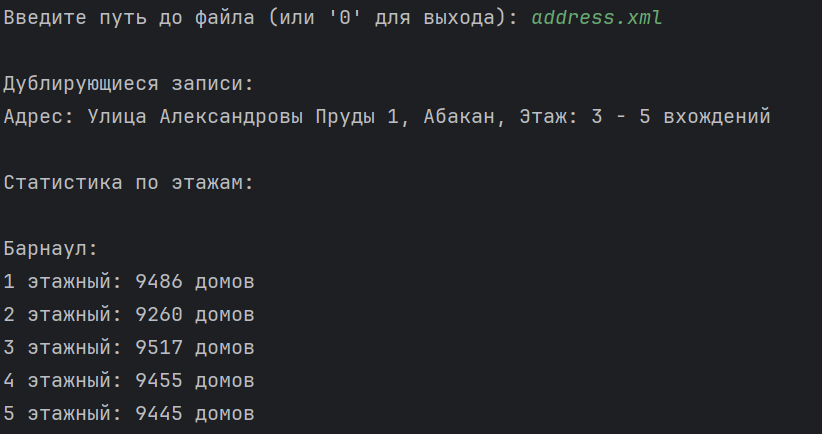
Рисунок 4 – результат обработки xml файла. Информация по городам
Также программа показывает время обработки xml файла (рисунок 5).

Рисунок 5 – результат обработки xml файла. Время выполнения
После обработки файла приложение запрашивает новый адрес, не завершая работу. При вводе неправильного расширения, программа предупреждает о некорректных данных и просит повторить запрос (рисунок 6).
Рисунок 6 – некорректный адрес до файла
При некорректном названии файла или его пустоте, приложение так же указывает на ошибку (рисунок 7).

Рисунок 7 – некорректное название файла
Программа завершает работу, если пользователем введен 0 (рисунок 8).

Рисунок 8 – завершение работы
Текст программы
address.py
class Address:
def __init__(self, city, street, house, floor):
self.city = city
self.street = street
self.house = int(house)
self.floor = int(floor)
def __str__(self):
return f"Адрес: Улица {self.street} {self.house}, {self.city}, Этаж: {self.floor}"
def as_key(self):
#ключ для дубликатов
return (self.city, self.street, self.house, self.floor)
import csv
import xml.etree.ElementTree as ET
from address import Address
parse.py
# чтения данных
class FileParser:
def __init__(self, file_path):
self.file_path = file_path
self.addresses = []
def parse(self):
#тип файла и парсинг
if self.file_path.endswith('.csv'):
return self.parse_csv()
elif self.file_path.endswith('.xml'):
return self.parse_xml()
else:
raise ValueError("Поддерживаются только файлы CSV или XML.")
def parse_csv(self):
#CSV
try:
with open(self.file_path, 'r', encoding='utf-8') as csvfile:
reader = csv.DictReader(csvfile, delimiter=';')
for row in reader:
self.addresses.append(Address(row["city"], row["street"], row["house"], row["floor"]))
except Exception as e:
print(f"Ошибка при чтении CSV: {e}")
return self.addresses
def parse_xml(self):
#XML
try:
tree = ET.parse(self.file_path)
root = tree.getroot()
for item in root.findall("item"):
self.addresses.append(Address(item.get("city"), item.get("street"), item.get("house"), item.get("floor")))
except Exception as e:
print(f"Ошибка при чтении XML: {e}")
return self.addresses
from collections import defaultdict
statistics.py
#вычисление и вывод статистики
class Statistics:
def __init__(self, addresses):
self.addresses = addresses
def find_duplicates(self):
#поиск дубликатов и их количество
counter = defaultdict(int)
for address in self.addresses:
counter[address.as_key()] += 1
duplicates = {key: count for key, count in counter.items() if count > 1}
return duplicates
def floor_statistics(self):
#статистика по этажам
stats = defaultdict(lambda: defaultdict(int))
for address in self.addresses:
stats[address.city][address.floor] += 1
return stats
def print_statistics(self, duplicates, floor_stats):
#статистика вывод
print("\nДублирующиеся записи:")
for (city, street, house, floor), count in duplicates.items():
print(f"Адрес: {street} {house}, {city}, Этаж: {floor} - {count} вхождений")
print("\nСтатистика по этажам:")
for city, floors in floor_stats.items():
print(f"\n{city}:")
for floor, count in sorted(floors.items(), key=lambda x: x[0]):
print(f"{floor} этажный: {count} домов")
main.py
from statistics import Statistics
from parse import FileParser
import time
class Application:
def run(self):
while True:
user_input = input("\nВведите путь до файла (или '0' для выхода): ").strip()
if user_input.lower() == '0':
print("Завершение работы.")
break
try:
start_time = time.time()
parser = FileParser(user_input)
addresses = parser.parse()
if not addresses:
print("Файл пуст или содержит ошибки.")
continue
statistics = Statistics(addresses)
duplicates = statistics.find_duplicates()
floor_stats = statistics.floor_statistics()
statistics.print_statistics(duplicates, floor_stats)
elapsed_time = time.time() - start_time
print(f"\nВремя обработки файла: {elapsed_time:.2f} секунд")
except Exception as e:
print(f"Ошибка обработки файла: {e}")
if __name__ == "__main__":
app = Application()
app.run()
5. Выводы
В ходе выполнения практической работы была создана программа,
способная взаимодействовать с xml и csv файлами.