

2.4. Реализация программного инструмента
Разработка системы построена по модульному принципу. Основной управляющий скрипт __main__.py отвечает за получение и обработку конфигурации, поиск логов, организацию их парсинга и генерацию отчёта. Вспомогательный модуль analyzer.py реализует ядро логики анализа — накапливает статистику, вычисляет метрики, определяет ошибки и возвращает агрегированные результаты [27].
Основной цикл обработки в __main__.py
1. Загрузка конфигурации:
Конфигурация считывается из командной строки (параметр --config) либо используется дефолтная.
Конфигурационные параметры включают:
REPORT_SIZE — количество строк в итоговом отчёте;
REPORT_DIR — каталог для HTML-отчётов;
LOG_DIR — каталог логов (например, ./log);
ERROR_PERC — порог допустимых ошибок (в процентах).
2. Поиск последнего лога:
Файл лога ищется по регулярному шаблону nginx-access-ui.log-YYYYMMDD(.gz) в каталоге логов.
Используется регулярное выражение для извлечения даты и расширения файла (.gz или обычный .log).
3. Проверка наличия готового отчёта:
Если для этого лог-файла отчёт уже сгенерирован — скрипт завершает выполнение.
4. Парсинг логов:
Каждая строка журнала анализируется с помощью регулярного выражения line_pattern, из строки извлекаются:
URL запроса;
Время выполнения запроса (request_time).
При ошибке (например, строка не соответствует шаблону) вместо значения возвращаются дефолтные '-' и '0.0'.
5. Анализ логов через класс Analyzer:
Для каждой строки вызывается метод analyzer.get_temp_result(url, request_time), который:
увеличивает счётчики;
суммирует время;
регистрирует уникальные значения времени;
определяет наличие ошибки (url == '-' and request_time == '0.0').
Если количество ошибочных записей превышает ERROR_PERC, выполнение прекращается.
6. Формирование итогового результата:
Вызывается метод analyzer.get_final_result(), возвращающий список словарей с данными по каждому URL:
количество обращений,
процент обращений от общего числа,
суммарное время,
среднее, максимальное и медианное время.
7. Генерация HTML-отчёта:
В шаблон report.html подставляется сериализованный JSON-фрагмент таблицы.
Отчёт сохраняется в REPORT_DIR с именем report-YYYY.MM.DD.html.
Алгоритмы анализа и вычислений в analyzer.py
Модуль реализует класс Analyzer, содержащий как внутренние счётчики и накопители, так и методы для статистического анализа:
1. Временные структуры:
_temp_result: словарь вида url → {count, time_sum, set_times_url}
_count_requests: общее количество записей.
_time_requests: сумма всех времён выполнения.
_errors: количество строк, не поддавшихся парсингу.
errors_perc: процент ошибок от общего количества.
2. Методы анализа представлены в таблице 8.
Таблица 8 - Методы анализа
Метод |
Назначение |
get_temp_result() |
Добавление строки в статистику |
count_perc() |
Процент от общего числа запросов |
time_perc() |
Доля от общего времени |
time_avg() |
Среднее время запроса |
time_med() |
Медианное время запроса |
get_final_result() |
Формирует отсортированный список словарей по time_sum |
Все функции декорированы через @round_decorate, округляющий результат до трёх знаков.
Пример результата:
[
{
"url": "/api/v2/banner",
"count": 1200,
"count_perc": 3.6,
"time_sum": 405.9,
"time_perc": 7.3,
"time_avg": 0.338,
"time_max": 3.114,
"time_med": 0.202
},
...
]
Таким образом, реализованный механизм обеспечивает полный цикл [28]:
от конфигурации и извлечения данных,
через фильтрацию и накопление статистики,
до вычисления рискоориентированных метрик и формирования отчётов.
Это делает систему гибкой, расширяемой и применимой как для ручного аудита логов, так и в составе автоматизированных систем мониторинга и управления рисками.
На рисунке 10 демонстрируется запуск системы без предварительно размещённых лог-файлов в директории ./log. Программа выводит в журнал логирования сообщение:
Поиск последнего лога в директории ./log
Файл логов не найден
Это указывает на успешную инициализацию программы и корректную отработку механизма проверки наличия входных данных. После отсутствия подходящих файлов выполнение завершается автоматически. Данный сценарий служит защитой от ошибочного запуска без данных.
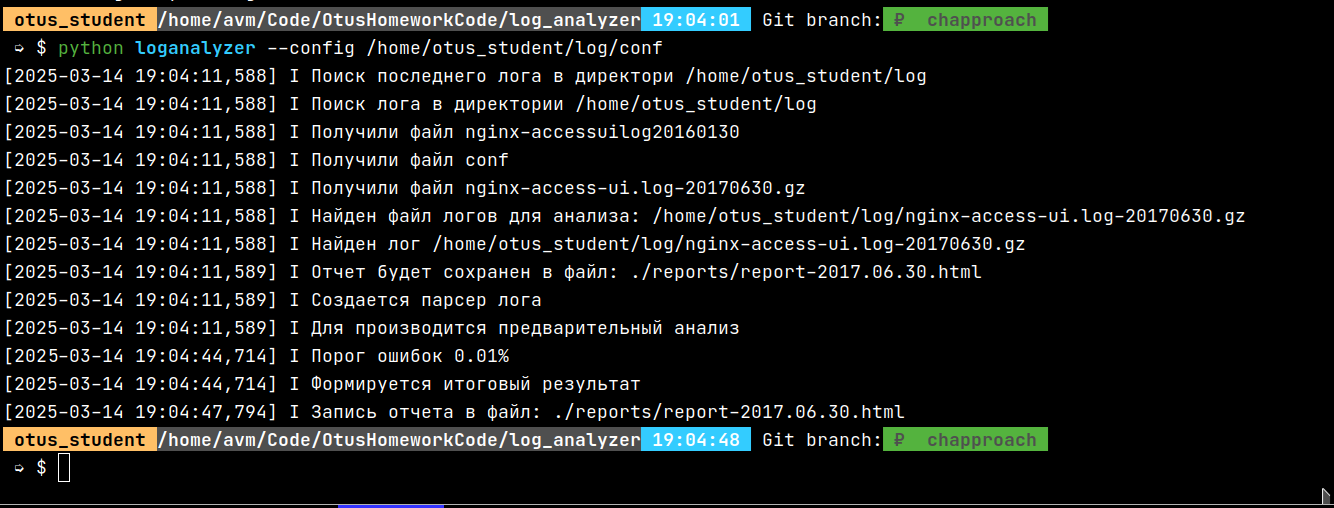
Рисунок 10 - Запуск анализатора без доступных логов
На рисунке 11 видно, как пользователь запускает систему с параметром --config, указывающим путь к пользовательскому конфигурационному файлу /home/otus_student/log/conf. В процессе выполнения программа:
определяет наличие файла nginx-access-ui.log-20170630.gz для анализа;
логирует факт нахождения нужного файла;
проверяет наличие уже сформированного HTML-отчёта по данному логу (report-2017.06.30.html);
завершает выполнение, поскольку такой отчёт уже существует.
Это демонстрирует корректную работу логики поиска и предотвращение дублирования отчётов.

Рисунок 11 - Запуск системы с пользовательской конфигурацией и найденным логом
На рисунке 12 показано успешное выполнение полного цикла анализа, начиная с загрузки пользовательской конфигурации. Система:
Загружает конфигурационный файл;
Определяет целевой лог-файл для анализа (nginx-access-ui.log-20170630.gz);
Генерирует путь для HTML-отчёта;
Инициализирует лог-парсер;
Выполняет предварительный анализ (выводится процент ошибок, в данном случае 0.01%);
Формирует агрегированный результат;
Сохраняет HTML-отчёт в папке ./reports/.
Данный скриншот фиксирует идеальный сценарий успешной генерации отчёта без критических ошибок, что подтверждает корректность работы всей системы.

Рисунок 12 - Полный цикл анализа и генерации отчёта