

Минобрнауки России
Санкт-петербургский государственный
Электротехнический университет
«ЛЭТИ» им. В.И. Ульянова (Ленина)
Кафедра вычислительной техники
Отчёт
Лабораторная работа №1
По дисциплине «АиСД»
Тема: множества
Студент гр. 3316 |
|
Руденский И.М. |
Преподаватель |
|
Манирагена Валенс |
Санкт-Петербург
2024
Постановка задачи
Цель работы: исследование четырёх способов хранения множеств в памяти ЭВМ.
Задание на обработку множеств:
Русские буквы |
Множество, содержащее буквы, имеющиеся в A или общие для B и C, но не встречающиеся в D |
Формализация задания: E = (A ∪ (B ∩ C)) \ D
Ход работы
1) Представим множества как массив символов. Возьмём как пример множеств мою фамилию, а также фамилии троих моих друзей.
a = РУДЕНСКИЙ
b = ЧЕТВЕРТАК
c = КИРЕЙКОВА
d = КОТОВ
На скриншоте первые две строки – промежуточные действия, третья строка – результирующее множество Е, последняя строка – скорость выполнения в мс.
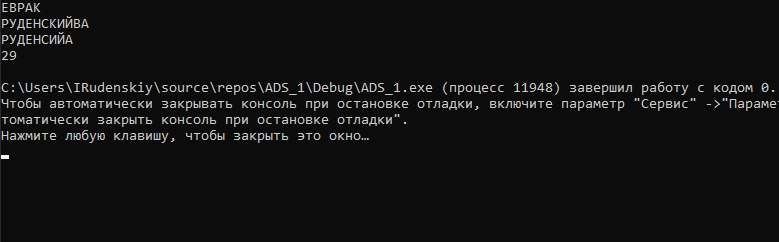
Рисунок 1 - Представление массивом символов
2) Повторим то же самое, но представим множества в виде списков.

Рисунок 2 - Представление списком
Как можно заметить, вариант со списком на 1мс быстрее.
3) Повторим то же самое, но представим множества в виде массивов байт.
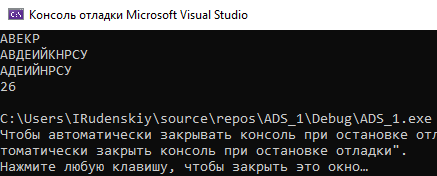
Рисунок 3 - Представление массивом байт
Здесь вышло ещё на 2мс быстрее.
4) Повторим то же самое, но представим множества в виде машинных слов.
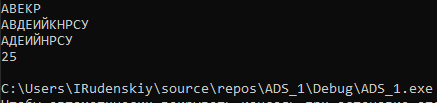
Рисунок 4 - Представление в виде машинных слов
Получили следующие результаты: самый быстрый способ – машинные слова.
5) Теперь, ради интереса, проверим, насколько быстро работают стандартные методы операций с множествами в std::set.
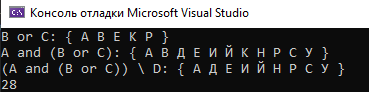
Рисунок 5 - std::set
Здесь скорость точно такая же, как у списка – 28мс.
Временная сложность
Массив символов |
Список |
Массив байт |
Машинные слова |
O(n^2), где n – кол-во символов в двух массивах |
O(n^2), где n – кол-во символов в двух списках |
О(1), побитовые операции очень быстрые |
О(1), побитовые операции очень быстрые |
Фактические временные сложности совпали с ожидаемыми.
Результаты измерения времени
|
Массив символов |
Список |
Массив байт |
Машинные слова |
Время, мс |
29 |
28 |
26 |
25 |
Зависимость от способа представления очевидна. Зависимость от размера данных сильнее всего ощущалась с массивами символов и списками, т.к. временная сложность алгоритмов в них выше. С массивами байт и машинными словами программа выполнялась гораздо быстрее, зависимость проявлялась незначительно.
Вывод
Выполнив лабораторную работу, можно сделать вывод, что наиболее быстрым и эффективным способом представления множеств являются машинные слова. Это легко объяснить тем, что машинное слово представляет собой обычную переменную типа int32 или int64, побитовые операции с такими переменными невероятно быстрые (имеют константную временную сложность). Немного уступают машинным словам списки и массивы байт. К списку нельзя применять побитовые операции, а std::find имеет линейную сложность, что замедляет операции с множествами. Массивы байт быстрые, но совсем немного уступают машинным словам из-за более сложной внутренней реализации. Массивы символов проигрывают по времени, при увеличении размера данных в множестве они ведут себя очень медленно.
|
Массив символов |
Список |
Массив байт |
Машинные слова |
Достоинства |
Всем известный способ, с ним не надо много думать |
Удобно пользоваться, т.к. есть std::list |
Очень быстрый, есть побитовые операции |
Аналогично с массивом байт |
Недостатки |
Очень медленный |
Медленный, не имеет побитовых операций |
Сложность представления слов на русском языке в виде комбинаций единиц и нулей, это ненагядно |
Аналогично с массивом байт |