

Кэширование и отказоустойчивость
•NTFS использует дисковый кэш для повышения производительности
•Кэширование повышает риск разрушения файловой системы
•NTFS обеспечивает отказоустойчивость с помощью протоколирования транзакций Структура журнала транзакций
•Журнал делится на область рестарта и область протоколирования
•Область рестарта указывает на начало чтения журнала для восстановления
•Область протоколирования содержит записи обо всех изменениях в системных данных Типы записей в журнале транзакций
•Запись модификации, запись контрольной точки, запись фиксации транзакции и другие
•Запись модификации содержит информацию для повторения и отмены действия Процесс выполнения транзакций
•NTFS вызывает службу LFS для регистрации транзакций
•Транзакции фиксируются с помощью записи фиксации
•Сброс данных кэша на диск выполняется в два этапа
Восстановление файловой системы после сбоя
•Несогласованность данных устраняется откатом незафиксированных транзакций
•Потеря изменений восстанавливается повторением транзакций
•Таблицы незавершенных транзакций и модифицированных страниц поддерживаются в оперативной памяти Процесс восстановления
•Чтение области рестарта и определение номера последней записи контрольной точки
•Чтение и корректировка таблиц незавершенных транзакций и модифицированных страниц
•Анализ таблиц и чтение журнала транзакций для устранения несоответствий
•Откат незавершенных транзакций
Связь подопераций транзакций
•Все подоперации каждой транзакции связаны в список
•Система легко переходит от одной записи модификации к другой
•Извлекается информация, необходимая для отмены
Отмена транзакций
•Операция отмены сама является транзакцией
•Связана с модификацией системных блоков файловой системы
•Протоколируется обычным образом в журнале транзакций Дополнительные операции
•По отношению к операции отмены могут быть применены операции повторения или отката
68. Избыточные дисковые подсистемы RAID.
В основе средств обеспечения отказоустойчивости дисковой памяти лежит общий для всех отказоустойчивых систем принцип избыточности, и дисковые подсистемы RAID (Redundant Array of Inexpensive Disks, дословно — «избыточный массив недорогих
дисков») являются примером реализации этого принципа. Идея технологии
RAID-массивов состоит в том, что для хранения данных используется несколько дисков, даже в тех случаях, когда для таких данных хватило бы места на одном диске.
RAID-массив может быть создан на базе нескольких обычных дисковых устройств, управляемых обычными контроллерами, в этом случае для организации управления всей совокупностью дисков в операционной системе должен быть установлен специальный драйвер. Существуют также различные модели дисковых систем, в которых технология RAID реализуется полностью аппаратными средствами, в этом случае массив дисков управляется общим специальным контроллером.
Различают несколько вариантов RAID-массивов, называемых также уровнями: RAID-0, RAID-1, RAID-2, RAID-3, RAID-4, RAID-5 и некоторые другие.
При оценке эффективности RAID-массивов чаще всего используются следующие критерии:
степень избыточности хранимой информации; производительность операций чтения и записи; степень отказоустойчивости.
В логическом устройстве RAID-0 общий для дискового массива контроллер при выполнении операции записи расщепляет данные на блоки и передает их параллельно на все диски, при этом первый блок данных записывается на первый диск, второй — на второй и т. д. Различные варианты реализации технологии RAID-0
могут отличаться размерами блоков данных.
Уровень RAID-1 реализует подход, называемый зеркальным копированием. Логическое устройство в этом случае образуется на основе одной или нескольких пар дисков, в которых один диск является основным, а другой диск (зеркальный) дублирует информацию, находящуюся на основном диске. Если основной диск выходит из строя, зеркальный продолжает сохранять данные, тем самым обеспечивается повышенная отказоустойчивость логического устройства. Все данные хранятся на логическом устройстве RAID-1 в двух экземплярах, в результате дисковое пространство используется лишь на 50%.
При внесении изменений в данные, расположенные на логическом устройстве RAID-1, контроллер (или драйвер) массива дисков одинаковым образом модифицирует и основной, и зеркальный диски, при этом дублирование операций абсолютно прозрачно для пользователя и приложений. Удвоение количества операций записи снижает, хотя и не очень значительно, производительность дисковой подсистемы, поэтому во многих случаях наряду с дублированием дисков дублируются и их контроллеры. Такое дублирование помимо повышения скорости операций записи, обеспечивает большую надежность системы — данные на зеркальном диске останутся доступными не только
при сбое диска, но и в случае сбоя дискового контроллера.
рейд 2 - существует некоторый блок с корректирующим кодом хэмминга
рейд 3 - блок четности, данные распараллеливаются побайтно
рейд 4 как рейд 3 но поблочно
RAID 5. Использует чередование данных с распределением контрольных сумм (парити) по всем дискам в массиве. Обеспечивает высокую надёжность и
эффективное использование дискового пространства, но требует как минимум трёх дисков.
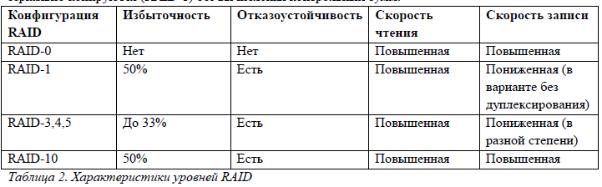
RAID 6. Схож с RAID 5, но использует две группы контрольных сумм, что позволяет сохранять данные даже при одновременном выходе из строя двух дисков.
RAID 10. Комбинация уровней RAID 1 и RAID 0: данные сначала зеркалируются, затем чередуются по нескольким парам дисков.
RAID 50 и RAID 60. Гибридные уровни, сочетающие RAID 5 или RAID 6 с RAID 0.