

МИНИСТЕРСТВО НАУКИ И ВЫСШЕГО ОБРАЗОВАНИЯ РОССИЙСКОЙ ФЕДЕРАЦИИ
федеральное государственное автономное образовательное учреждение высшего образования
«САНКТ-ПЕТЕРБУРГСКИЙ ГОСУДАРСТВЕННЫЙ УНИВЕРСИТЕТ
АЭРОКОСМИЧЕСКОГО ПРИБОРОСТРОЕНИЯ»
Кафедра 41
ПРЕПОДАВАТЕЛЬ
Профессор, д-р техн. наук |
|
|
|
Т. М. Татарникова |
должность, уч. степень, звание |
|
подпись, дата |
|
инициалы, фамилия |
Лабораторная работа №1
Кластеризация данных
по курсу: Введение в анализ данных
СТУДЕНТКА ГР. № |
Z0411 |
|
23.05.23 |
|
М. В. Карелина |
|
|
номер группы |
|
подпись, дата |
|
инициалы, фамилия |
|
Номер студенческого билета: 2020/3477
Санкт-Петербург
2023
Цель работы:
изучить алгоритмы и методы кластерного анализа на практике.
Задание:
1.Получить у преподавателя набор данных для проведения кластерного анализа, при необходимости провести нормализацию и кодирование данных. Одним из двух методов: иерархическим агломеративным или методом k-средних выполнить кластеризацию объектов, представленных в варианте задания.
Вариант 4. Датасет heart.
Код вместе с описанием и скриншотами:
Для начала загрузим необходимые библиотеки.
import pandas as pd
import csv
import matplotlib.pyplot as plt
import numpy as np
from sklearn.preprocessing import StandardScaler
from sklearn.cluster import KMeans
from scipy.cluster.hierarchy import dendrogram, linkage
from sklearn.metrics import silhouette_score
from scipy.spatial import distance
from sklearn.cluster import AgglomerativeClustering
from yellowbrick.cluster import KElbowVisualizer
import seaborn as sns
Специально для Google Colab загрузим необходимый файл csv.
from google.colab import files
uploaded = files.upload()
Далее на экран выведем первые 10 строк из файла (Рис. 1).
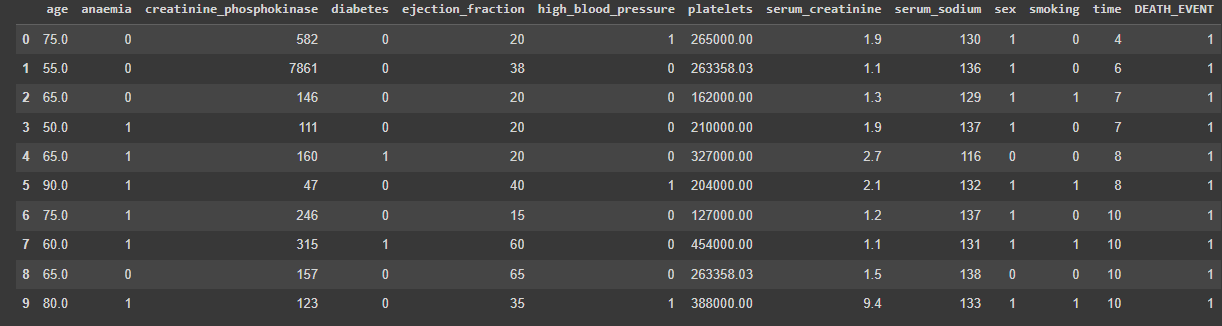
Рисунок 1 - Вывод на экран первых 10 строк
Теперь необходимо было оценить данные. На рисунке 2 видно, что некоторые названия столбцов неправильные, а именно начинаются с большой буквы.
dataframe.info()
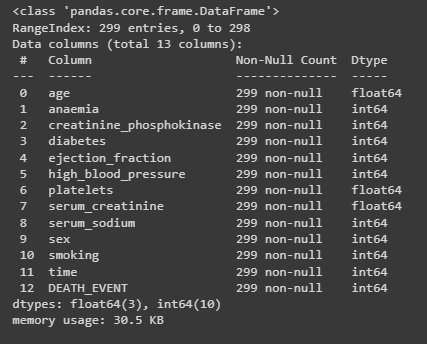
Рисунок 2 – Оценка данных
Для того, чтобы, верно, ввести текущие названия столбцов для их последующего исправления, применила метод columns, который выводит названия колонок через запятую (Рис.3).
print(dataframe.columns)

Рисунок 3 – Применения метода columns
С помощью метода rename() столбцы переименовываются, а с помощью метода info() проверяется правильность этого переименования (Рис.4).
for Name, values in dataframe.items():
dataframe.rename(columns={Name:Name.lower()},inplace=True)
dataframe.rename(columns={'death_event':'died'},inplace=True)
dataframe.rename(columns={'time':'time_since_first_visit'},inplace=True)
print(dataframe.info())
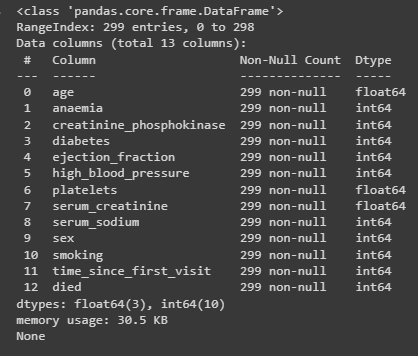
Рисунок 4 – Переименование столбцов
Описание колонок:
age - здесь представлен возраст пациентов. Столбец имеет целочисленный тип данных.
anaemia - здесь представлена информация, есть ли у пациента анемия, где 1 - есть, а 0 - нет. Столбец имеет булев тип данных.
creatinine_phosphokinase - здесь представлена информация о количестве креатинфосфокиназы в крови. Столбец имеет целочисленный тип данных.
diabetes - здесь представлена информация, есть ли у пациента диабет, где 1 - есть, а 0 - нет. Столбец имеет булев тип данных.
ejection_fraction - здесь представлена информация об объеме фракции выброса. Столбец имеет целочисленный тип данных.
high_blood_pressure - здесь представлена информация об артериальном давлении. Столбец имеет целочисленный тип данных.
platelets - здесь представлена информация о количестве тромборцитов. Столбец имеет тип данных: числовой с плавающей точкой.
serum_creatinine - здесь представлена информация о количестве креатинина в сыворотке. Столбец имеет тип данных: числовой с плавающей точкой.
serum_sodium - здесь представлена информация о количестве натрия в сыворотке. Столбец имеет тип данных: числовой с плавающей точкой.
sex - здесь представлен пол посетителя спортзала, где 1 - мужской пол, а 0 - женский. Столбец имеет булев тип данных.
smoking - здесь представлена информация, курит ли пациент, где 1 - да, а 0 - нет. Столбец имеет булев тип данных.
time_since_first_visit - здесь представлена информация о времени с первого визита. Столбец имеет целочисленный тип данных.
died - здесь представлена информация, умер ли пациент, где 1 - да, а 0 - нет. Столбец имеет булев тип данных.
Далее необходимо проверить, есть ли пропуски в данных, с помощью метода df.isna().sum(). Видно, что пропуски отсутствуют, а значит, можно приступать к поиску дубликатов.
Далее проверила, есть ли пропуски в данных, с помощью метода df.isna().sum(). На рисунке 5 видно, что пропуски отсутствуют.
print(dataframe.isna().sum())
#fillna(0)
#dropna
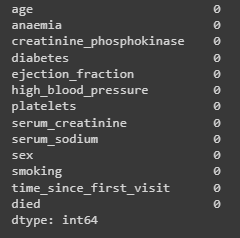
Рисунок 5 – Обнаружение пропусков данных
Явные дубликаты рациональнее удалять уже после устранения неявных, а именно замены, объектов, имеющих немного отличающиеся названия, но при этом являющихся одним и тем же объектом по сути. С помощью метода unique и sort на экран выводятся все, что есть в столбце "пол" по возрастанию. Сортировка нужна, чтобы было легче искать дубликаты. Некорректных значений нигде обнаружено (Рис.6).
dataframe['sex'].unique()
array([1, 0])
for Name, values in dataframe.items():
print(Name)
gen = dataframe[Name].unique()
gen.sort()
print(gen, '\n')

Рисунок 6 – Поиск некорректных результатов
Далее производится проверка на наличие явных дубликатов. print(dataframe.duplicated().sum())
Явных дубликатов не обнаружено.
С помощью метода df.dtypes производим проверку типов данных столбцов (Рис.7).
print(dataframe.dtypes)
# str - object
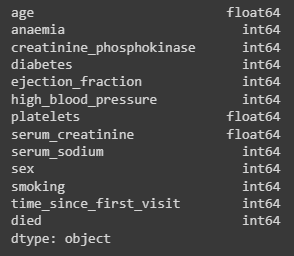
Рисунок 7 – Проверка типа данных столбцов
Необходимо поменять тип данных столбца "Возраст" и "Тромбоциты" на целочисленный, а после ещё раз проверить правильность. У столбцов, где ожидается булев тип данных, тип данных не будет изменён с целочисленного, т.к. это помешает дальнейшему построению графиков (Рис.18).
dataframe['age'] = dataframe['age'].astype('int64')
dataframe['platelets'] = dataframe['platelets'].astype('int64')
print(dataframe.dtypes)
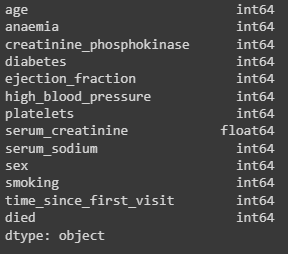
Рисунок 8 – Замена age и platelets на int
Далее перейдем непосредственно к самой кластеризации.