

Data Mining: классификация, кластеризация, регрессия, ассоциативные правила, анализ отклонений
Шестой метод Big Data – это технологии Data Mining, которые представляют собой комплекс технологий «добычи» новой значимой информации из большого объема данных. Наиболее часто в сельском хозяйстве используются такие из них, как: классификация, кластеризация, регрессия, ассоциативные правила, анализ отклонений.
Рассмотрим основные из них более подробно и как они применяются в сельском хозяйстве.
Для задач классификации используют методы ближайшего соседа (Nearest Neighbor); k – ближайшего соседа (k – Nearest Neighbor); байесовские сети (Bayesian Networks); индукцию деревьев решений; нейронные сети (Neural Networks).
Методы классификации (big data)
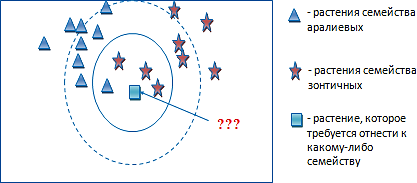
Одним из наиболее часто используемых методов классификации является метод k-ближайшего соседа. Сущность метода состоит в том, что существуют (известны) определенные классы (виды) чего- либо. И стоит задача – отнести неизвестный нам ранее объект к какому-то классу (виду). Например, в растениеводстве – к виду, классу или семейству растений. Например, растение Тмин мы хотим отнести к какому-то семейству).
 Метод
k-ближайшего
соседа
Метод
k-ближайшего
соседа
На рисунке звездочками отмечены растения семейства аралиевых (по основным признакам), которые входят в одно семейство с зонтичными растениями (зонтичные представлены синими треугольниками). Неизвестному объекту присваивается среднее значение по ближайшим к нему объектам, значения которых уже известны. Значит, тмин будет отнесен к семейству зонтичных.
Учитывая, что разные признаки растений имеют различные единицы измерения, то они все нормализуются. Затем выделяются наиболее значимые атрибуты среди всех. И по ним осуществляется классификация.
Кластеризация имеет алгоритм, сходный с алгоритмом классификации. Единственное различие состоит в том, что группы или классы заранее не выделены и требуется их выделить. Поскольку кластеризация проводится также по множеству признаков, имеющих разные единицы измерения, то конкретные значения признаков также нормализуются.
В качестве применения кластерного анализа в растениеводстве можно привести следующий. Технологии точного земледелия предполагают выделение на поле разграниченных зон управления – то есть разделение поля на относительно однородные части, куда можно впоследствии направить технику с однородными задачами – определенными дозами внесения удобрений, определенными дозами полива растений. Причем, эти участки должны быть по возможности смежными. Эти несколько условий формируют кластерные, то есть, относительно группы участков на поле.

Кластеризация объектов
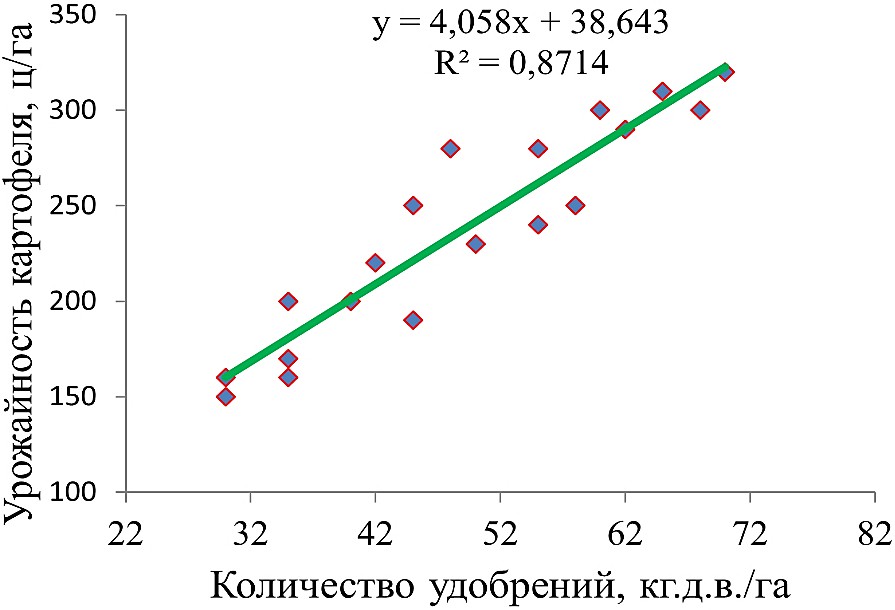
Также к методам Data mining относят регрессию – один из статистических методов, позволяющих определить направление, характер и степень тесноты связи между факторным и результативными признаками. В сельском хозяйстве регрессионный анализ давно и широко используется. Однако регрессионный анализ, опирающийся на Big Data, характеризуется большей степенью вероятности суждений, что более ценно. Однако при этом следует уделять большое вни мание очистке данных и их трансформации в требуемый формат.
В агрономии использовать регрессионный анализ используют, например, при определении характера зависимости между данными почвенного плодородия, поступающими после анализа спутниковых снимков, и урожайностью сельскохозяйственных культур; факторами, влияющими на урожайность, также являются температура и количество осадков, массовые данные о которых поступают с датчиков температуры и влажности, количество вносимых удобрений и другие факторы.
 Регрессионная
зависимость
урожайности
картофеля
от
количества
вносимых
минеральных
удобрений
Регрессионная
зависимость
урожайности
картофеля
от
количества
вносимых
минеральных
удобрений
Метод ассоциативных правил позволяет на основе анализа больших данных выявить шаблоны и на их основе предсказать будущие действия, то есть позволяют находить некоторые закономерности, которые показывают, что их некоего события X будет следовать событие Y. В растениеводческом предприятии с помощью метода ассоциативных правил можно прогнозировать, например, шаблон покупок сельхозпродукции оптовыми покупателями или торговыми сетями.
Инструментами программной реализации Data Mining являются такие, как:
Rapid Miner – это ПО с расширенными аналитическими сервисами с открытым исходным кодом;
R – это свободная программная среда для статистических вычислений и графики, написанная на C ++;
R Studio – это IDE, специально разработанная для языка R;
Weka – это набор алгоритмов машинного обучения для задач интеллектуального анализа данных;
Knime – это мощный инструмент с графическим интерфейсом, который показывает сеть узлов данных;
TANAGRA – бесплатное программное обеспечение для интеллектуального анализа данных с открытым исходным кодом для академических и исследовательских целей;
XLMiner является единственной всеобъемлющей надстройкой интеллектуального анализа данных для Excel с нейронными сетями, деревьями классификации и регрессии, логистической регрессией, линейной регрессией, классификатором Байеса, ближайшими соседями К, дискриминантным анализом, правилами ассоциации, кластеризацией, основными компонентами и т. Д.
Итак, множество методов и технологий Data Mining позволяет провести анализ больших данных в производстве, оценить результаты опытов, разработать модели для просчетов результатов будущих исследований.