

ГУАП
КАФЕДРА № 41
ОТЧЕТ ЗАЩИЩЕН С ОЦЕНКОЙ
ПРЕПОДАВАТЕЛЬ
старший преподаватель |
|
|
|
Н.В. Апанасенко |
должность, уч. степень, звание |
|
подпись, дата |
|
инициалы, фамилия |
ОТЧЕТ О ЛАБОРАТОРНОЙ РАБОТЕ №2 |
СТРАТЕГИИ РАСПРЕДЕЛЕНИЯ РЕСУРСНЫХ БЛОКОВ В ЦЕНТРАЛИЗОВАННОЙ СЕТИ СО СЛУЧАЙНЫМ ТРАФИКОМ |
по курсу: МОДЕЛИРОВАНИЕ СИСТЕМ РАСПРЕДЕЛЕНИЯ РЕСУРСОВ |
|
|
РАБОТУ ВЫПОЛНИЛ
СТУДЕНТ гр. № |
|
|
|
|
|
|
|
|
подпись, дата |
|
инициалы, фамилия |
Санкт-Петербург 2025
Цель работы: получение навыков моделирования стандартных сценариев работы телекоммуникационных систем с топологией типа «звезда». Изучение свойств алгоритмов планирования ресурсов нисходящего кадра в подобных системах. Изучение стратегий распределения ресурсных блоков в централизованной сети со случайным трафиком
Вариант 13:
На рисунке 1 представлены параметры сети согласно варианту задания.

Рисунок 1 – Параметры сети по варианту 13
Расчетные формулы для оценки предельно достижимой скорости:
Рассчитаем мощность шума:
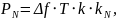 (1)
(1)
здесь
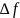 – полоса
пропускания канала связи,
– полоса
пропускания канала связи,
T – абсолютная температура (К),
k
– постоянная
Больцмана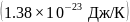 ,
,
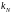 -
коэффициент теплового шума приемника
-
коэффициент теплового шума приемника
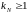 .
.
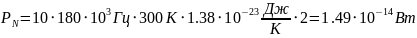
Рассчитаем потери L:
 (2)
(2)
где
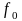 -
частота (МГц),
-
частота (МГц),
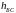 -
высота базовой станции (м), возьмем 40м,
-
высота базовой станции (м), возьмем 40м,
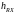 -
высота точки приема (м), возьмём средний
рост человека 1.7м,
-
высота точки приема (м), возьмём средний
рост человека 1.7м,
d – расстояние от АБ до БС (км), возьмем максимальное расстояние 2.5км,
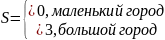 ,
,
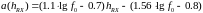 (3)
(3)
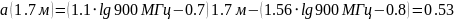
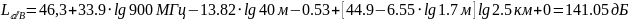
Переведем из «дБ» в «разы»:
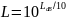 (4)
(4)
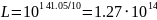
Рассчитаем мощность, принятую АБ:
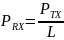 (5)
(5)
где
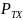 -
излучаемая мощность БС (Вт),
-
излучаемая мощность БС (Вт),
L - уровень потерь мощности при преодолении сигналов расстояния от БС к АБ
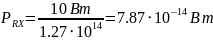
Рассчитаем отношение сигнал/шум:
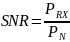 (6)
(6)
где
PRX – мощность, принятая АБ,
PN - мощность шума.

Рассчитаем пропускную способность канала связи:
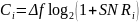 (7)
(7)
где
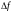 -
полоса пропускания канала связи,
-
полоса пропускания канала связи,
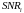 -
отношение сигнал/шум (Signal-to-Noise
Ratio,
SNR)
у абонента с индексом
-
отношение сигнал/шум (Signal-to-Noise
Ratio,
SNR)
у абонента с индексом
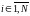 .
.
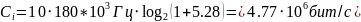
Рассмотрим алгоритмы распределения ресурсов.
Equal Blind
Данный алгоритм выравнивает среднюю скорость закачки. Для алгоритма Equal Blind приоритет пользователя i на ресурсный блок j определяется как:
|
(7) |
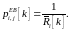
Соответственно, ресурсный блок отдается тому пользователю, у которого самый высокий приоритет:
|
(8) |
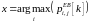
здесь x номер абонента, которому выделен ресурсный блок j в слоте k.
Maximum Throughput
Алгоритм MT «отдает» ресурсный блок тому пользователю, у которого максимальна пропускная канала связи. Приоритет пользователя i на ресурсный блок j определяется как:
|
(9) |
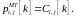
Соответственно, ресурсный блок отдается тому пользователю, у которого самый высокий приоритет:
|
(10) |
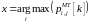
здесь x номер абонента, которому отдается ресурсный блок j в слоте k.
Proportional fair (выравнивание ресурсов, отдаваемых пользователям):
|
(11) |
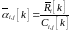
средняя доля ресурса, которую i-ый абонент получил от базовой станции к моменту k. Приоритет пользователя i на ресурсный блок j определяется как:
|
(12) |
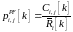 .
.Соответственно, ресурсный блок отдается тому пользователю, у которого самый высокий приоритет:
|
(13) |
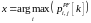
здесь x номер абонента, которому отдан ресурсный блок j в слоте k.
Рассмотрим
сглаживающий фильтр для нахождения
значения
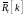 :
:
Зафиксируем интервал времени y (выраженную в секундах) на котором рассчитаем среднюю скорость, с которой АБ скачивал данные. Тогда количество слотов, на котором рассчитывается средняя скорость находится как:
|
(14) |
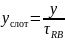
Средняя скорость, с которой абонент скачивал, полученная на основе сглаживающего фильтра может быть записана как:
|
(15) |
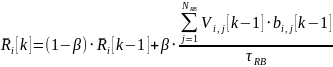
где
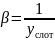 .
.
Пример случайных расположений абонентских станций
Была разработана программа для моделирования и визуализации пространственного распределения абонентов вокруг базовой станции в полярной системе координат (Листинг 1).
Сначала определяется функция place_users, которая принимает количество абонентов N и радиус окружности R как входные параметры. Функция генерирует случайные углы в диапазоне от 0 до 2π с равномерным распределением с помощью метода np.random.uniform, а также случайные радиусы, равномерно распределённые по площади круга. Для получения радиусов используется метод квадратного корня от случайных значений, что обеспечивает равномерную плотность распределения абонентов по всей площади окружности.
С целью обеспечения воспроизводимости результатов устанавливается фиксированное значение зерна генератора случайных чисел с помощью функции np.random.seed.
Далее выполняется визуализация полученного распределения абонентов. В полярной системе координат с использованием библиотеки matplotlib строится диаграмма, где положения абонентов отображаются в виде точек. Центр координат обозначает местоположение базовой станции и выделяется красным маркером. Также задаются параметры отображения: ориентация начального угла по направлению на восток и направление оси углов по часовой стрелке, добавляются сетка и легенда.
В результате работы программы визуализируется схема с размещением 64 абонентов в пределах окружности заданного радиуса, позволяющая наглядно оценить пространственное распределение пользователей относительно базовой станции (Рисунок 1).
Листинг 1- Генерация и визуализация размещения абонентов вокруг БС
# Функция для размещения абонентов внутри окружности
def place_users(N, R):
angles = np.random.uniform(0, 2 * np.pi, N)
radii = np.sqrt(np.random.uniform(0, R**2, N))
return angles, radii
np.random.seed(123) # Зерно рандома для воспроизводимости результатов
# Визуализация распределения абонентов в полярной системе координат
angles, radii = place_users(64, R) # Пример для 64 абонентов
plt.figure(figsize=(8, 8))
ax = plt.subplot(111, projection='polar')
ax.scatter(angles, radii, s=30, label='Абоненты')
ax.plot(0, 0, color='red', marker='o', markersize=10, label='Базовая станция')
ax.set_theta_zero_location('E')
ax.set_theta_direction(1)
ax.grid(True)
ax.set_title('Распределение 64 абонентов вокруг базовой станции', pad=20)
ax.legend(loc='upper right')
plt.show()
Рисунок 1 – Распределение абонентов вокруг БС
Описание разработанной программы:
Была разработана программа для моделирования распределения ресурсов в сети с использованием алгоритмов планирования. Программа симулирует работу радиосети с расчетом пропускной способности, потерь сигнала, отношения сигнал/шум (SNR) и распределения ресурсов между пользователями.
Определяется основная модель симуляции, которая включает несколько компонентов, таких как расчёт потерь по модели Окамура-Хата, вычисление мощности принятого сигнала, а также пропускной способности сети для каждого пользователя. Для каждого абонента выполняются вычисление затухания сигнала, вычисление пропускной способности на основе отношения сигнал/шум (SNR) и распределение ресурсных блоков с использованием различных алгоритмов планирования.
Для выполнения модели используется асинхронное выполнение через библиотеку asyncio, что позволяет параллельно обрабатывать большое количество конфигураций пользователей и интенсивности потока данных, значительно ускоряя процесс моделирования. При таких условиях время выполнения моделирования занимает около 20 минут.
В результате работы программы получаем следующие данные: для каждой конфигурации (разное количество пользователей и интенсивность потока) вычисляются средние значения размера буфера для каждого алгоритма.
В таблице 1 представлены использованные прееменные, в Листинге 2 представлен программный код для моделирования.
Таблица 1 – Исопльзованные переменные
Переменная |
Описание |
R |
Радиус зоны покрытия (метры). |
Ptx |
Мощность передатчика (Вт). |
F0 |
Несущая частота (МГц). |
KN |
Коэффициент потерь (единицы измерения зависят от конкретной модели). |
N_RB |
Количество ресурсных блоков (RB) в сети. |
packet_size |
Размер пакета в битах. |
tau_RB |
Длительность одного ресурсного блока (секунды). |
delta_f_RB |
Полоса частот одного ресурсного блока (Гц). |
simulation_slots |
Число слотов симуляции. |
N2_lambda, N4_lambda, N16_lambda, N32_lambda |
Интенсивности потока пакетов для разных конфигураций пользователей. |
Hbs |
Высота базовой станции (м). |
Hrx |
Высота абонента (м). |
S |
Параметр затенения. |
K |
Постоянная Больцмана (единицы измерения). |
T |
Абсолютная температура (К). |
Pn |
Мощность шума (Вт). |
distances |
Массив расстояний от БС до каждого пользователя (метры). |
Li_base |
Базовое затухание сигнала для каждого пользователя (дБ). |
Li |
Общее затухание сигнала для каждого пользователя и ресурсного блока. |
C |
Пропускная способность для каждого пользователя и ресурсного блока (бит/с). |
V |
Максимальный объем данных, который может быть передан за один слот (биты). |
p_ij_k |
Приоритеты для каждого пользователя и ресурсного блока. |
buffers |
Буферы для разных алгоритмов планирования (бит). |
R_avg |
Средняя скорость передачи данных для каждого пользователя и алгоритма. |
hist |
История суммарных размеров буферов для каждого алгоритма. |
rb_allocation |
Массив, показывающий распределение ресурсных блоков среди пользователей. |
transmit_volume |
Объем переданных данных для каждого пользователя. |
Листинг 2 – Программа для моделирования
import numpy as np
import matplotlib.pyplot as plt
from scipy.stats import poisson, norm
import asyncio
import time
import nest_asyncio
# Параметры
R = 2500 # радиус зоны покрытия (м)
Ptx = 10 # мощность передатчика (Вт)
F0 = 900 # несущая частота (МГц)
KN = 2 # коэффициент потерь
N_RB = 25 # количество ресурсных блоков
packet_size = 8*1024 # размер пакета в битах
tau_RB = 0.5*10**(-3) # длительность слота (0.5 мс)
delta_f_RB = 180*10**3 # полоса частот
simulation_slots = 10**5 # число слотов
N2_lambda = [0, 1, 1.5, 2.0, 2.5]
N4_lambda = [0, 0.5, 0.75, 1.0, 1.5]
N16_lambda = [0, 0.1, 0.15, 0.2, 0.3]
N32_lambda = [0, 0.05, 0.1, 0.2, 0.3]
N_users_values = [2, 4, 16, 32] # число пользователей, shape: (4,)
# Параметры для модели Окамура-Хата
Hbs = 40 # Высота БС (м)
Hrx = 1.7 # Высота абонента (м)
S = 0 # Параметр затенения
K = 1.38 * 10**(-23) # Постоянная Больцмана
T = 300 # Абсолютная температура (К)
Pn = K * T * delta_f_RB * KN # Мощность шума
# Векторизованная функция для расчета потерь по модели Окамура-Хата
def okumura_hata_vectorized(d, f0, hbs, hrx, s):
# d: distances - shape: (N_users,) - расстояния от БС до каждого пользователя
# Возвращает: L_db - shape: (N_users,) - потери сигнала в дБ для каждого пользователя
# Преобразуем расстояние в километры
d_km = d / 1000 # shape: (N_users,)
# Расчет коэффициента a(hrx)
a_hrx = (1.1 * np.log10(f0) - 0.7) * hrx - (1.56 * np.log10(f0) - 0.8)
# Расчет потерь по модели Окамура-Хата
L_db = 46.3 + 33.9 * np.log10(f0) - 13.82 * np.log10(hbs) - a_hrx + (44.9 - 6.55 * np.log10(hrx)) * np.log10(d_km) + s # shape: (N_users,)
return L_db
# Векторизованная функция для расчета мощности принятого сигнала
def calculate_received_power_vectorized(ptx, L_db):
# L_db: shape (N_users, N_RB) - затухание сигнала в дБ
# Возвращает: Prx - shape (N_users, N_RB) - мощность принятого сигнала в ваттах
# L_db должен быть уже вычислен и передан
Prx = ptx / (10 ** (L_db / 10)) # Принятая мощность в ваттах, shape: (N_users, N_RB)
return Prx
# Векторизованная функция для расчета SNR
def calculate_snr_vectorized(ptx, L_db):
# L_db: shape (N_users, N_RB) - затухание сигнала в дБ
# Возвращает: snr - shape (N_users, N_RB) - отношение сигнал/шум
Prx = calculate_received_power_vectorized(ptx, L_db) # shape: (N_users, N_RB)
snr = Prx / Pn # shape: (N_users, N_RB)
return snr
# Векторизованная функция для расчета пропускной способности (скорости)
def calculate_data_rate_vectorized(snr, DF):
# snr: shape (N_users, N_RB) - отношение сигнал/шум
# DF: полоса частот
# Возвращает: shape (N_users, N_RB) - пропускная способность в бит/с
return DF * np.log2(1 + snr) # shape: (N_users, N_RB)
# Функция для размещения абонентов внутри окружности
def place_users(N, R):
# N: число пользователей
# R: радиус зоны покрытия
# Возвращает: radii - shape: (N,) - расстояния от БС до каждого пользователя
radii = np.sqrt(np.random.uniform(0, R**2, N)) # shape: (N,)
return radii
def model(N_users, lambda_val):
# N_users: число пользователей
# lambda_val: интенсивность поступления пакетов
# Возвращает: кортеж из трех значений - средние размеры буферов для трех алгоритмов
distances = place_users(N_users, R) # shape: (N_users,) - расстояния от БС до каждого пользователя
# Буферы для каждого алгоритма - словарь с тремя ключами, каждый содержит numpy array
# shape каждого массива: (N_users,) - размер буфера для каждого пользователя в битах
buffers = {'Equal Blind': np.zeros(N_users),
'Maximum Throughput': np.zeros(N_users),
'Proportional Fair': np.zeros(N_users)}
# Начальные средние скорости - словарь с тремя ключами, каждый содержит numpy array
# shape каждого массива: (N_users,) - средняя скорость передачи в бит/с для каждого пользователя
R_avg = {'Equal Blind': np.ones(N_users)*1e-6,
'Maximum Throughput': np.ones(N_users)*1e-6,
'Proportional Fair': np.ones(N_users)*1e-6}
# История буферов - словарь с тремя ключами, каждый содержит пустой список
# Будет наполняться суммарным размером буфера на каждой итерации
hist = {'Equal Blind': [], 'Max Throughput': [], 'Proportional Fair': []}
# Предварительно вычисляем базовые потери для всех пользователей
# shape: (N_users, 1) - базовое затухание сигнала в дБ для каждого пользователя
Li_base = okumura_hata_vectorized(distances, F0, Hbs, Hrx, S).reshape(N_users, 1)
# Предварительно выделяем память для массивов, которые будут многократно использоваться
Li = np.zeros((N_users, N_RB)) # shape: (N_users, N_RB) - затухание сигнала для каждого пользователя и ресурсного блока
C = np.zeros((N_users, N_RB)) # shape: (N_users, N_RB) - пропускная способность для каждого пользователя и ресурсного блока
V = np.zeros((N_users, N_RB)) # shape: (N_users, N_RB) - максимальный объем данных в битах, который можно передать
p_ij_k = np.zeros((N_users, N_RB)) # shape: (N_users, N_RB) - приоритеты для алгоритмов планирования
for k in range(simulation_slots):
# Генерируем случайные затухания (векторизованно)
# x_ij_k: shape: (N_users, N_RB) - случайная компонента затухания
x_ij_k = norm.rvs(0, 1, size=(N_users, N_RB))
# Li: shape: (N_users, N_RB) - полное затухание сигнала для каждого пользователя и ресурсного блока
Li = np.tile(np.mean(Li_base), (N_users, N_RB)) + x_ij_k
# Генерируем пакеты для всех пользователей сразу
# packets: shape: (N_users,) - число пакетов для каждого пользователя
packets = poisson.rvs(lambda_val, size=N_users)
# Вычисляем SNR и пропускную способность (векторизованно)
# snr_values: shape: (N_users, N_RB) - SNR для каждого пользователя и ресурсного блока
snr_values = calculate_snr_vectorized(Ptx, Li)
# C: shape: (N_users, N_RB) - пропускная способность в бит/с для каждого пользователя и ресурсного блока
C = calculate_data_rate_vectorized(snr_values, delta_f_RB)
# V: shape: (N_users, N_RB) - максимальный объем данных в битах, который можно передать за один слот
V = C * tau_RB
# Распределение ресурсов для каждого алгоритма
for algorithm in buffers:
# Расчет приоритетов (векторизованно)
if algorithm == 'Equal Blind':
# p_ij_k: shape: (N_users, N_RB) - приоритеты для алгоритма Equal Blind
p_ij_k = np.ones((N_users, N_RB)) / R_avg[algorithm].reshape(N_users, 1)
elif algorithm == 'Max Throughput':
# p_ij_k: shape: (N_users, N_RB) - приоритеты для алгоритма Max Throughput (равны пропускной способности)
p_ij_k = C.copy()
elif algorithm == 'Proportional Fair':
# p_ij_k: shape: (N_users, N_RB) - приоритеты для алгоритма Proportional Fair
p_ij_k = C / R_avg[algorithm].reshape(N_users, 1)
# Инициализация счетчика для отслеживания объема данных
# transmit_volume: shape: (N_users,) - объем переданных данных для каждого пользователя
transmit_volume = np.zeros(N_users)
# Добавляем пакеты в буферы (размер каждого пакета в битах умножается на число пакетов)
buffers[algorithm] += packets * packet_size # shape: (N_users,)
# Определяем активных пользователей (тех, у кого буфер не пуст)
# active_users: shape: (M,) - индексы активных пользователей, где M <= N_users
active_users = np.where(buffers[algorithm] > 0)[0]
if len(active_users) > 0:
# Инициализация массива распределения ресурсных блоков
# rb_allocation: shape: (N_RB,) - массив, показывающий какому пользователю назначен каждый ресурсный блок
rb_allocation = np.full(N_RB, -1, dtype=int)
# Вычисляем приоритеты только для активных пользователей
# active_priorities: shape: (M, N_RB) - приоритеты только для активных пользователей
active_priorities = p_ij_k[active_users]
# Распределяем ресурсные блоки одним проходом
for rb_index in range(N_RB):
if len(active_users) == 0:
break
# Находим индекс максимального приоритета среди активных пользователей
# best_user_local_idx: индекс пользователя с максимальным приоритетом в массиве active_users
best_user_local_idx = np.argmax(active_priorities[:, rb_index])
# selected_user_id: фактический индекс выбранного пользователя
selected_user_id = active_users[best_user_local_idx]
# Назначаем ресурсный блок выбранному пользователю
rb_allocation[rb_index] = selected_user_id
# Вычисляем объем данных для передачи (минимум из пропускной способности и размера буфера)
# data_to_transmit: объем данных для передачи в битах
data_to_transmit = min(V[selected_user_id, rb_index], buffers[algorithm][selected_user_id])
# Обновляем буфер и счетчик переданных данных
buffers[algorithm][selected_user_id] -= data_to_transmit
transmit_volume[selected_user_id] += data_to_transmit
# Если буфер пуст, удаляем пользователя из активных
if buffers[algorithm][selected_user_id] <= 0:
# Находим индекс в массиве active_users
# remove_idx: индекс пользователя в массиве active_users, которого нужно удалить
remove_idx = np.where(active_users == selected_user_id)[0][0]
# Удаляем пользователя и его приоритеты из соответствующих массивов
active_users = np.delete(active_users, remove_idx) # shape: (M-1,)
active_priorities = np.delete(active_priorities, remove_idx, axis=0) # shape: (M-1, N_RB)
# Сглаживающий фильтр для обновления средних скоростей
y = 1.
beta = tau_RB / y # коэффициент сглаживания
# Обновляем средние скорости для алгоритма, shape: (N_users,)
R_avg[algorithm] = (1-beta)*R_avg[algorithm] + beta*(transmit_volume/tau_RB)
# Добавляем текущий суммарный размер буфера в историю
hist[algorithm].append(np.sum(buffers[algorithm])) # сумма всех буферов
# Возвращаем средние значения истории буферов для трех алгоритмов
# Каждое значение - среднее по всем итерациям для данного алгоритма
return (np.mean(hist['Equal Blind']),
np.mean(hist['Maximum Throughput']),
np.mean(hist['Proportional Fair']))
async def model_async(N, lam):
"""Асинхронная обертка для функции model"""
try:
if lam == 0:
print(f"Пропуск моделирования для N={N}, λ={lam} (всегда нули)")
return (0, 0, 0), N, lam
# Передаем выполнение основной функции, которая может занять много времени
result = await asyncio.to_thread(model, N, lam)
print(f"Выполнено моделирование для N={N}, λ={lam}")
return result, N, lam
except Exception as e:
print(f"Ошибка при N={N}, λ={lam}: {str(e)}")
return (0, 0, 0), N, lam
async def main():
start_time = time.time()
results = {N: {'Equal Blind': [], 'Maximum Throughput': [], 'Proportional Fair': []} for N in N_users_values}
# Используем фиксированное начальное значение для воспроизводимости результатов
np.random.seed(42)
# Создаем список задач для асинхронного выполнения
tasks = []
for N in N_users_values:
if N == 2:
lambda_values = N2_lambda
elif N == 4:
lambda_values = N4_lambda
elif N == 16:
lambda_values = N16_lambda
elif N == 32:
lambda_values = N32_lambda
for lam in lambda_values:
print(f"Запуск моделирования: N={N}, λ={lam}")
tasks.append(model_async(N, lam))
# Запускаем все задачи параллельно и ждем результаты
completed_tasks = await asyncio.gather(*tasks)
# Обрабатываем результаты
for result, N, lam in completed_tasks:
eb, mt, pf = result
if N == 2:
lambda_values = N2_lambda
elif N == 4:
lambda_values = N4_lambda
elif N == 16:
lambda_values = N16_lambda
elif N == 32:
lambda_values = N32_lambda
lambda_index = list(lambda_values).index(lam)
results[N]['Equal Blind'].insert(lambda_index, eb)
results[N]['Maximum Throughput'].insert(lambda_index, mt)
results[N]['Proportional Fair'].insert(lambda_index, pf)
end_time = time.time()
print(f"Общее время выполнения: {end_time - start_time} секунд")
print(f"Моделирование успешно завершено для всех конфигураций!")
return results
nest_asyncio.apply()
results_optimized = asyncio.run(main())