

ГУАП
КАФЕДРА № 41
ОТЧЕТ
ЗАЩИЩЕН С ОЦЕНКОЙ
ПРЕПОДАВАТЕЛЬ
Старший преподаватель |
|
|
|
В.В.Боженко |
должность, уч. степень, звание |
|
подпись, дата |
|
инициалы, фамилия |
ОТЧЕТ О ЛАБОРАТОРНОЙ РАБОТЕ №3 |
СВЕРТОЧНЫЕ НЕЙРОННЫЕ СЕТИ |
по курсу: МАШИННОЕ ОБУЧЕНИЕ |
|
|
РАБОТУ ВЫПОЛНИЛА
СТУДЕНТКА ГР. |
4117 |
|
|
|
А.В.Иванова |
|
|
|
подпись, дата |
|
инициалы, фамилия |
Санкт-Петербург 2024
Цель работы:
Обучить свёрточную сеть распознавать изображения.
Ссылка на colab:
https://colab.research.google.com/drive/1WoizFqidh_6iKFeOnWBmEDLbMj22Za-l?authuser=0#scrollTo=_37MHyFPe38I
Задание:
Создать модели НС для распознавания рукописных цифр.
Ход работы:
Часть 1. В начале импортируются необходимые для работы библиотеки, большая часть из которых наборы данных и различные виды слоёв Keras для описания структуры нейросети.
Сформированы тренировочная и валидационная выборки из набора данных MNIST. MNIST — это набор данных для оценки моделей машинного обучения по проблеме классификации рукописных цифр. В нём представлены изображения отсканированных цифр. Каждое изображение представляет собой квадрат размером 28 на 28 пикселей (всего 784 пикселя). Обучающая выборка включает 60 000 изображений, тогда как валидационная - 10 000.
Для визуализации 4 случайных изображений из каждого набора используется функция vis_img, получающая на вход выборку и её название. Через функцию sample генерируются 4 случайных порядковых номера изображения в выборке, после чего варианты с данными номерами визуализируются при помощи функции imshow. (Рисунок 1-2).

Рисунок 1 – 4 случайных числа из тренировочного набора

Рисунок 2 – 4 случайных числа из валидационного набора
Полученные данные необходимо нормализовать. Изображения из массивов 28 на 28 пикселей представляются в виде одномерных массивов размером в 784 элемента.
Так как значения пикселей заданы в диапазоне от 0 до 255, показывая оттенок цвета, для упрощения работы нейросети можно поделить эти значения на 255, тем самым отмасштабировав их в диапазоне от 0 до 1.
Также чтобы обучить классификационную модель используется to_categorical для преобразования обучающих данных в двоичные матрицы размером 10, где все ячейки заполнены 0, кроме одной 1, указывающей на обозначенную цифру.
По заданию нужно создать несколько моделей, с разными архитектурами и выполнить предсказания и сравнить результаты и качество построенных сетей.
Эксперимент 1. Простая НС из 2 слоёв, во входном 64 нейрона, в выходном - 10, по количеству распознаваемых цифр. Во входном слое линейная функция активация, в выходном - softmax. Полный код находится в Приложении А.
Так как в последствии для других моделей будут схожим образом выполняться обучение, предсказание, построение графиков потерь и точности, вывод характеристик модели, то было решено использовать для этого отдельные функции, и вызывать их в дальнейшем для других моделей.
Функция make_history проводит обучение для переданной модели, используя заданное количество эпох. Функция выводит оценку потерь и точности модели и возвращает эти значения.
Также для удобства чтения задается список ответов из валидационной выборки в более удобном формате.
Функция prediction выполняет предсказание на основе переданной модели, результаты выводятся наряду с истинными значениями, для быстрого сравнения.
Для записи результатов проводимых по распознаванию экспериментов создан датафрейм results_df, и функция для добавления новых результатов в данный набор через метод loc.
Для вывода различных метрик качества сети используется метод classification_report. Для первой модели показаны высокие оценки точности (в общем 92 %), а в виде тепловой карты выведена матрица ошибок, отображающая точность распознавания конкретного класса. Результаты приведены на Рисунках 3-4.
Для данной модели получилось, что хуже всего распознается цифра 5 (точность 0.85), далее 8 и 2. Лучше всего сеть распознает цифры 1, 0 и 6.
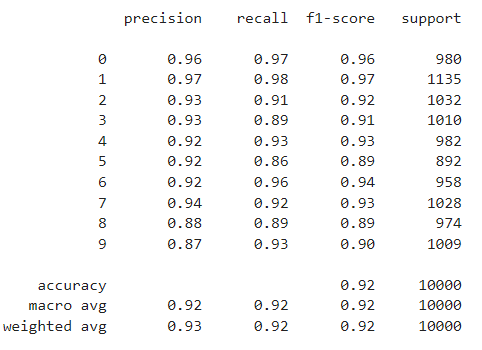
Рисунок 3 – Метрики для 1 модели
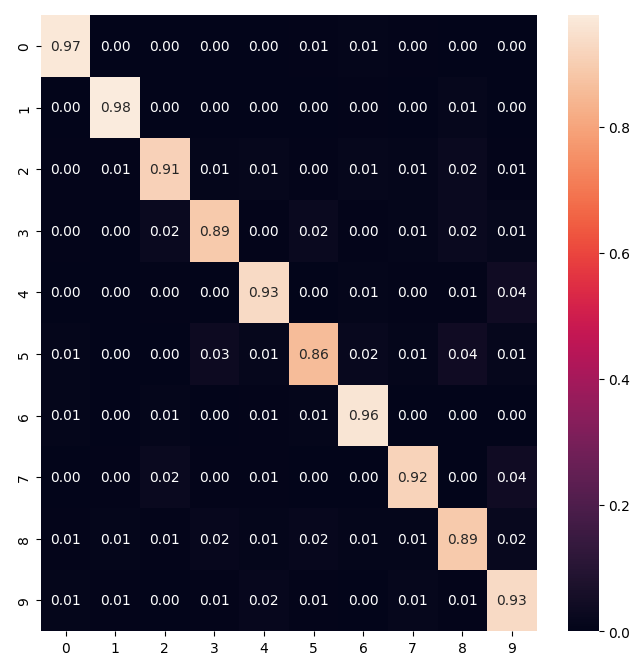
Рисунок 4 – Матрица ошибок для модели 1
Функция plot_loss выводит строит графики потерь и точности для выполненных предсказаний. Как можно видеть на графиках, с увеличением количества эпох потери снижаются, а следовательно точность распознавания растет. Для данной модели значения точности на валидационной выборке стабильно составляет около 92 процентов, как было выведено в метриках качества (Рисунок 5).
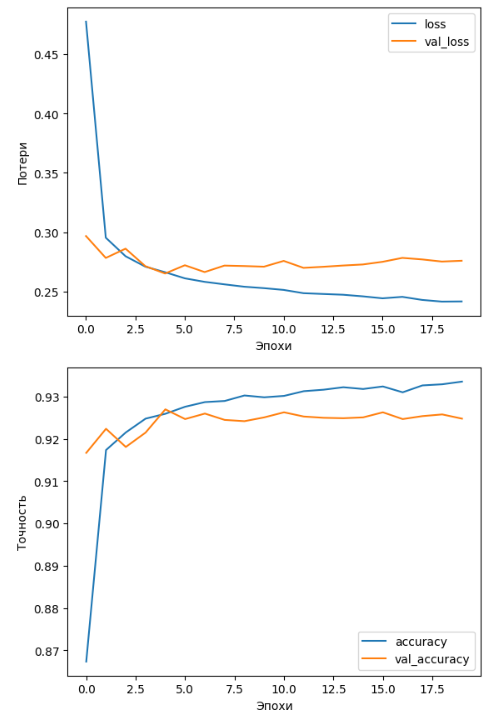
Эксперимент 2. Следующая рассматриваемая модель отличается только функцией активации. Теперь вместо линейной используется relu. Обучение, предсказание, вывод метрик и построение графиков осуществляется за счет ранее написанных функций. Полный код находится в Приложении Б.
По матрице ошибок и метрикам, можно сказать что данная модель уже лучше справляется с распознаванием. Точность у неё выше на 0.5 по сравнению с первой моделью, и почти все цифры распознаются одинаково хорошо. А точность распознавания 1 и 0 составляет приблизительно 99 %.Результаты на Рисунках 6-7.
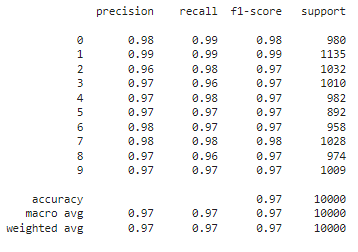
Рисунок 6 – Метрики модели 2
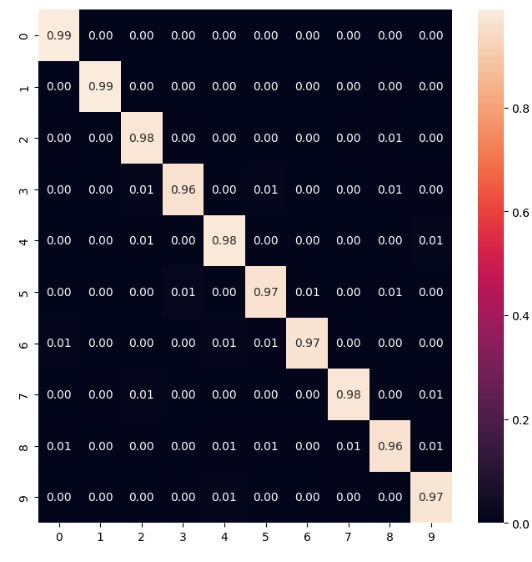
Рисунок 7 – Матрица ошибок модели 2
Графики потерь и точности также показывают на снижение уровня ошибок по мере увеличения эпох. Примеры приведена на Рисунке 8.
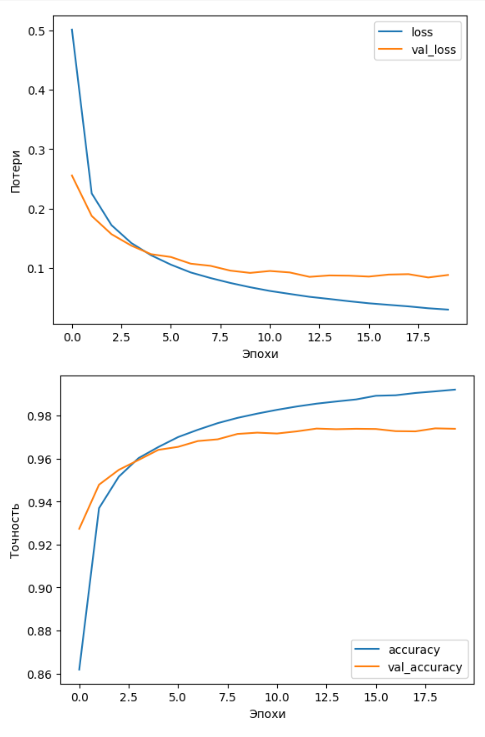
Рисунок 8 – Графики потерь и точности модели 2
Эксперимент 3. Модель расширена, теперь используется 4 слоя. Во входном 256 нейронов, далее 128, и 64. В качестве функции активации используется relu. Также при обучении используется 40 эпох. Полный код находится в Приложении В.
Проведено обучение сети и записаны результаты эксперимента.
Матрица ошибок не сильно отличается от предыдущей модели, но будет немного точнее (0.98). Так что можно сказать, что модель справляется лучше. Результаты на Рисунках 9-10.

Рисунок 9 – Метрики модели 3
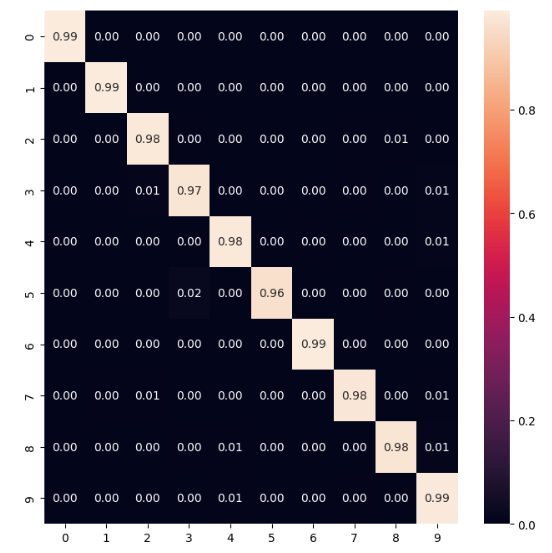
Рисунок 10 – Матрица ошибок модели 3
Однако на графике (Рисунок 11) зависимости потерь и точности от количества эпох виден большой разрыв в результатах для обучающей и валидационной выборках. Это может говорить о переобучении, но точность на валидационной выборке все равно достаточно высока.
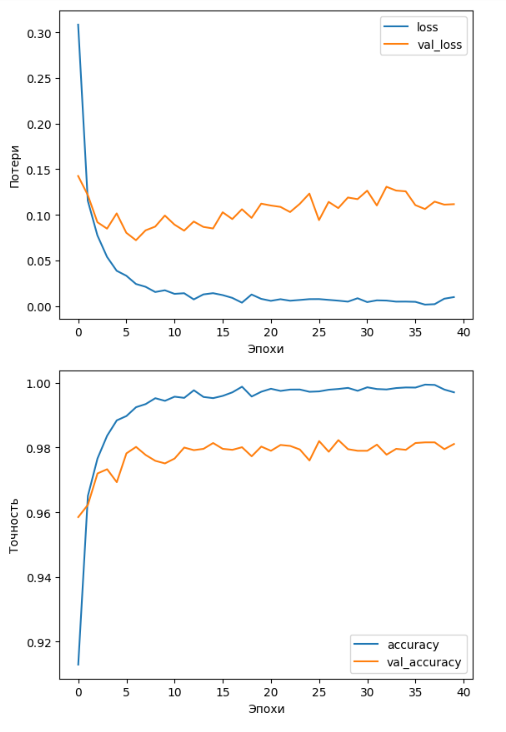
Рисунок 11 – Графики потерь и точности для модели 3
Эксперимент 4. Модель имеет схожую структуру с третьей, но в ней меньшее количество нейронов. Функция активации также relu, в обучении проводится 40 эпох. Код представлен в Приложении Г.
Ожидаемых результатов на улучшение модель показала. Точность соответствует точности предыдущей модели, как показано на Рисунках 12-13.
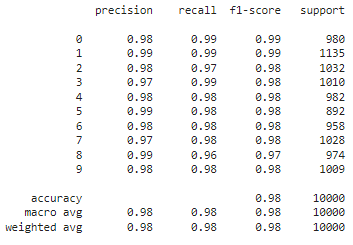
Рисунок 12 – Метрики модели 4
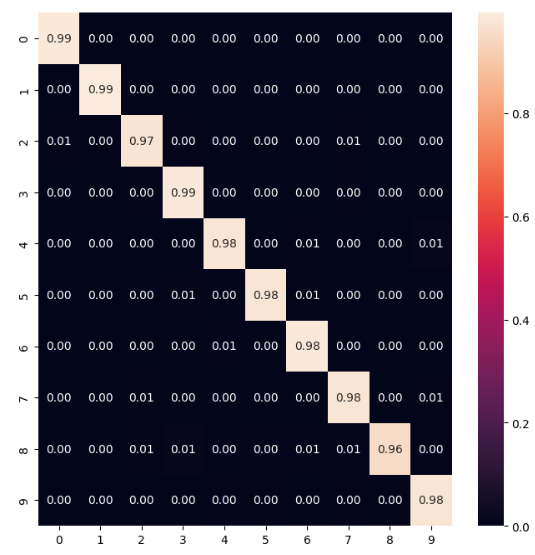
Рисунок 13 – Матрица ошибок модели 4
Аналогичным образом наблюдается небольшой разрыв в результатах потерь и точности для обучающей и валидационных выборок. Проведенный эксперимент показывает, что увеличение нейронов вдвое, при их мало количестве (128) существенно не влияет на результаты предсказывания (Рисунок 14).
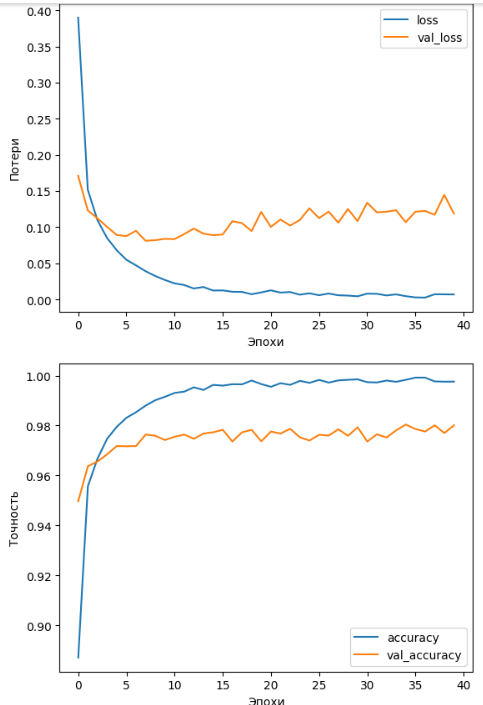
Рисунок 14 – Графики потерь и точности модели 4
Эксперимент 5 - Сверточная нейронная сеть. В качестве входного слоя выступает слой свёртки. Полный код представлен в Приложении Д.
Сверточный слой представляет из себя набор карт, у каждой карты есть ядро (фильтр). В данном случае блок свертки имеет 32 фильтра размером (3, 3) с активацией ReLU. Входная форма выглядит как (28, 28, 1), так как изображения представлены в виде матриц 28 на 28 пикселей.
Далее идет слой подвыборки (пуллинга), который снижает размерность изображения, тем самым ускоряя работы сети. Следующий слой Flatten не влияет на результаты обучения, а преобразует поступающий на вход после развертывания многомерный массив в одномерный.
Далее следует полносязный слой в 128 нейронов и выходной полносвязный слой.
Для новой модели сети заново загружены наборы данных, без их преобразования в одномерные векторы.
Выполняется обучение модели в 40 эпох. Также выполнено предсказание.
Результаты эксперимента записаны, на этот раз сеть состоит из 6 слоёв. По выведенным метрикам качества и матрице ошибок, можно сделать вывод о том, что построенная сверточная нейронная сеть справляется лучше, чем ее предшественники, так как имеет точность в 0.99, что на 0.1 выше, чем у лучшей испытанной простой модели. Результаты приведена на Рисунках 15-16.
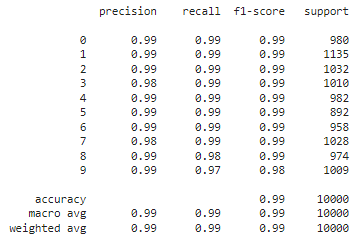
Рисунок 15 – Метрики модели 5
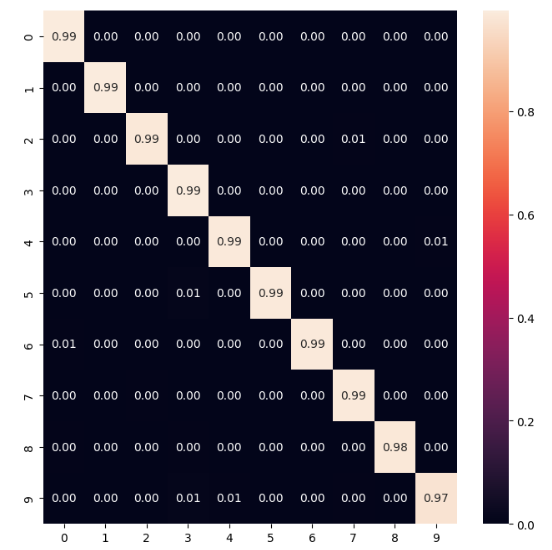
Рисунок 16 – Матрица Ошибок модели 5
На графиках зависимости потерь и точности от количества эпох результаты также выглядят несколько лучше, если сравнивать с разрывами между результатами для тренировочной и валидационных выборок у моделей 3 и 4. У сверточной сети точность выше, а разрыв результатов для разных выборок меньше. Пример приведен на Рисунке 17.
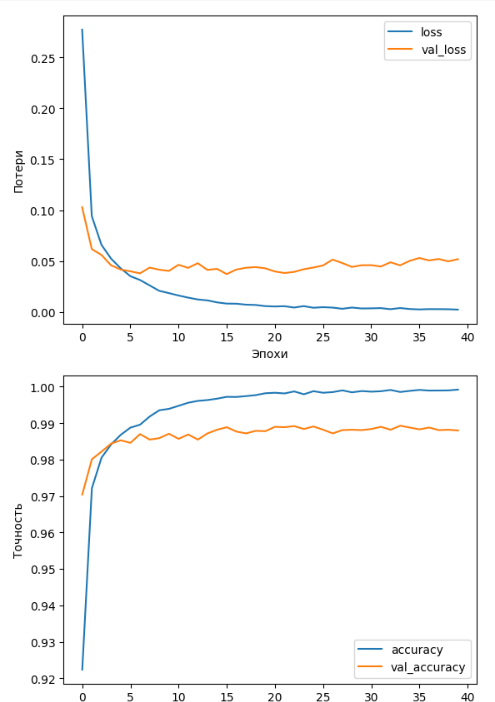
Рисунок 17 – Графики потерь и точности для модели 5
Эксперимент 6 - Сверточная нейронная сеть 2. Создана еще одна сверточная НС, имеющая более сложную структуру. Она включает 10 слоёв, из которых 3 сверточные. Поочередно сеть содержит сверточные блоки и слови пуллинга, далее следует слой Flatten, полносвязный слой в 128 нейронов и Dropout, добавленный для снижения вероятности переобучения, путем случайного отключения от обучения 25 % нейронов. Полный код представлен в Приложении Е.
Проведено обучение модели в 40 эпох.
Результаты эксперимента с шестой моделью записаны в датафрейм.
Данная модель на 100 % справилась с распознавание цифры "0", однако в целом её точность немного меньше, чем у предыдущей модели сверточной сети. Поэтому можно сказать о том, что усложнение сети не всегда повышает её точность и эффективность работы. Результаты на Рисунках 18-19.

Рисунок 18 – Метрики модели 6.
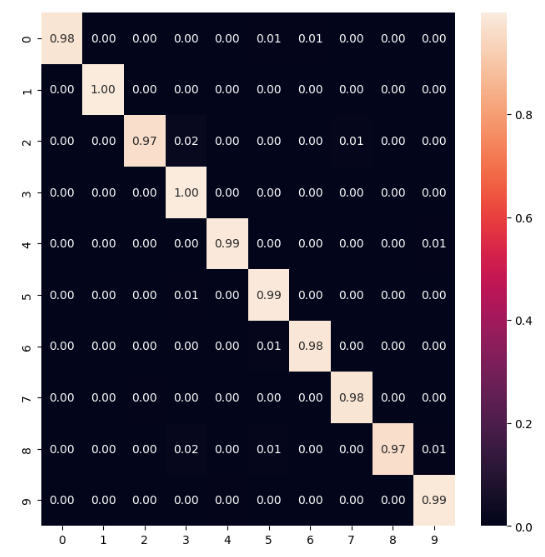
Рисунок 19 – Матрица ошибок модели 6.
На графиках потерь и точности модели заметны те же данные о небольшом снижении результатов, по сравнению с предыдущей сетью (Рисунок 20).
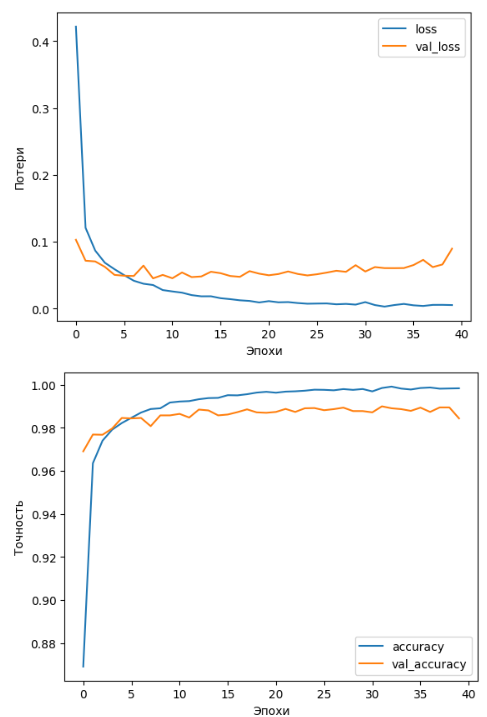
Рисунок 20 – Графики для модели 6
Выведены результаты экспериментов для 6 созданных сетей, 4 простых и 2 сверточных. Данные показаны в порядке убывания точности. Так можно быстро определить, что лучше всего с задачей распознавания справилась сверточная сеть из 6 слоёв, 1 из которых сверточный. Ее точность составила 0.988. Следующей идет более сложная сверточная сеть, и далее простые сети, которые снижаются по качеству с уменьшением количества слоёв и нейронов.
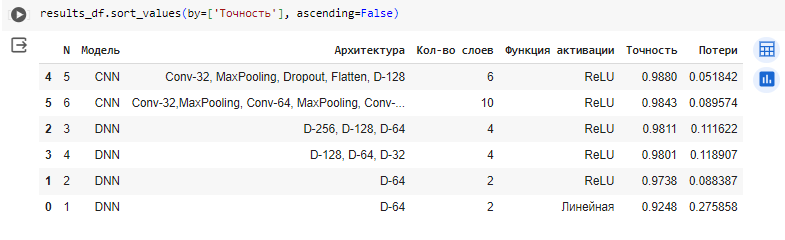
Рисунок 21 – Сравнение результатов
Лучше всего себя показала 5 модель, поэтому на ней проверена работа на собственных рукописных цифрах. Были нарисованы цифры 7 и 8 (Рисунок 22), и сеть успешно справилась с их распознаванием (Рисунок 23).
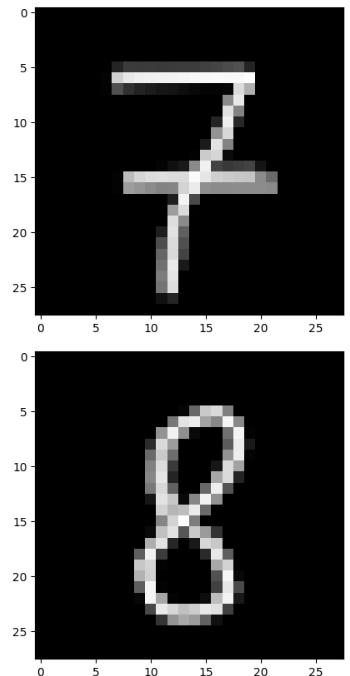
Рисунок 22 – нарисованные цифры

Рисунок 23 – Результаты распознавания