

Моделирование4
.docxЦель работы: получить навыки обработки выборочных данных
средствами MATLAB/GNU Octave.
Вариант 21 (1)
Ход работы
Часть 1
Выписаны 50 элементов выборки по варианту, значения округлены до двух знаков после запятой, справа расположен вариационный ряд. (Рисунок 1)

Рисунок 1- Значения по варианту и вариационный ряд
Далее вычислено количество интервалов с помощью формулы Стерджесса, определена длина интервала и произведено разделение выборки на интервалы (Рисунок 2).

Рисунок 2- Разбиение выборки на интервалы
Построена гистограмма (Рисунок 3).

Рисунок 3- График гистограммы выборки
На гистограмме видно, что правая сторона распределения растянута в положительную сторону, что может говорить о том, что разброс положительных значений больше, чем отрицательных.
Также построен график эмпирической функции распределения и полигона частот (Рисунок 4-5).

Рисунок 4- График эмпирической функции распределения
График ЭФР показывает плавный рост.

Рисунок 5- График полигона частот выборки
Рассчитаны выборочное среднее, дисперсия, СКО, мода, медиана, коэффициенты асимметрии и эксцесса (Рисунок 6).

Рисунок 6- Выборочное среднее, дисперсия, СКО, мода, медиана, коэффициенты асимметрии и эксцесса
Метрики показывают, что распределение в среднем сосредоточено около нулевого значения и имеет достаточно широкий разброс значений относительно среднего. Медиана близка со средним, что указывает на симметричность распределения относительно нуля.
Положительное значение коэффициента асимметрии говорит о том, что распределение имеет правостороннюю асимметрию. Коэффициент эксцесса также положительный, значит распределение имеет более острую вершину по сравнению с нормальным распределением.
Таким образом, можно сказать, что данное распределение является близким к нормальному, но с небольшой правосторонней асимметрией.
Часть 2
Импортирована таблица с данными выборки. Данные сортированы в порядке возрастания. Вычислено количество интервалов, и выборка разбита на интервалы.
Листинг 1- Импортирование данных и разбиение на интервалы
import pandas as pd
import numpy as np
df = pd.read_csv('myData.csv')
array = df['variant_1'].to_numpy()
data = np.sort(array)
intervals = int(np.sqrt(len(data)))
interval_length = (data.max() - data.min()) / intervals
# Границы интервалов
bins = np.linspace(data.min(), data.max(), intervals + 1)
data_intervals = pd.cut(data, bins)
print(data_intervals)
Построены графики гистограммы, эмпирической функции распределения и полигона частот (Рисунок 7-9)
Листинг 2- Построение графика гистограммы
import matplotlib.pyplot as plt
plt.hist(array, bins=bins,color='indigo')
plt.xlabel('Значения')
plt.ylabel('Частота')
plt.title('Гистограмма выборки')
plt.show()

Рисунок 7- Гистограмма выборки
Гистограмма выборки показывает равномерное распределение данных в интервале от 0 до 1. Частоты значений не сильно различаются между собой, что указывает на то, что данные распределены относительно равномерно.
Листинг 3- Построение графика ЭФР
ecdf = np.array([np.sum(data <= x) / len(array) for x in data])
plt.plot(data, ecdf, color='red')
plt.xlabel('y')
plt.ylabel('x')
plt.title('Эмпирическая функция распределения')
plt.show()
plt.figure(figsize=(7, 5))
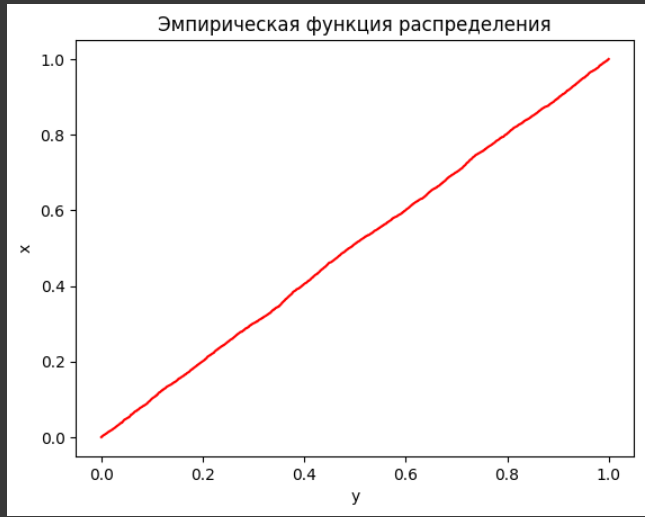
Рисунок 8- График эмпирической функции распределения
Эмпирическая функция распределения показывает линейное увеличение вероятности, что характерно для равномерного распределения.
Листинг 4- Построение графика полигона частот
y = interval_counts = data_intervals.value_counts()
# Середины интервалов
x = (bins[:-1] + bins[1:]) / 2
plt.title('График полигона частот')
plt.plot(x, y, color='green')
plt.scatter(x, y, color='green', s=50, linewidth=1)
plt.show()

Рисунок 9- График полигона частот
График полигона частот показывает некоторую вариабельность данных, но в целом частоты значений остаются в пределах от 55 до 95.
Также вычислены выборочное среднее, дисперсия, СКО, мода, медиана, коэффициенты асимметрии и эксцесса (Рисунок 10).
Листинг 5- Вычисление метрик
import scipy.stats as stats
import statsmodels.api as sm
m = np.mean(data).round(3)
d = np.var(data).round(3)
s = np.sqrt(d).round(3)
mode = stats.mode(data)
median = np.median(data)
A_s = stats.skew(array)
E_k = stats.kurtosis(array)
print("Выборочное среднее:", m)
print("Дисперсия:", d)
print("Среднеквадратическое отклонение:", s)
print("Мода:", mode[0])
print("Медиана:", median)
print("Коэффициент асимметрии:", A_s )
print("Коэффициент эксцесса:", E_k )

Рисунок 10- Метрики распределения
Среднее значение выборки очень близко к 0,5, что подтверждает равномерность распределения данных. Значения близкие к 0 являются наиболее частыми значениями. Коэффициент асимметрии также близок к 0, что данные не имеют значительной асимметрии. Коэффициент эксцесса имеет отрицательное значение, которое указывает на более плоское распределение.
Вычислены метрики по теоретическим формулам равномерного распределения (Рисунок 11).
Листинг 6- Вычисление теоретических метрик
import scipy.stats as stats
import statsmodels.api as sm
m = np.mean(data).round(3)
d = np.var(data).round(3)
s = np.sqrt(d).round(3)
mode = stats.mode(data)
median = np.median(data)
A_s = stats.skew(array)
E_k = stats.kurtosis(array)
print("Выборочное среднее:", m)
print("Дисперсия:", d)
print("Среднеквадратическое отклонение:", s)
print("Мода:", mode[0])
print("Медиана:", median)
print("Коэффициент асимметрии:", A_s )
print("Коэффициент эксцесса:", E_k )

Рисунок 11- Теоретические метрики
Ранее вычисленные метрики близки к теоретическим, что подтверждает равномерное распределение.
Вывод: в ходе выполнения лабораторной работы был сформирован вариационный ряд, вычислено количество интервалов, вычислена длина интервалов, выборка была разбита на интервалы.
Для визуализации распределения построены графики гистограммы эмпирической функции распределения и полигона частот. Вычислены выборочное среднее, дисперсия, СКО, мода, медиана, коэффициент асимметрии, коэффициент эксцесса.
В первой части лабораторной работы анализ проведен вручную, во второй с помощью программных средств.