

Структурированные и неструктурированные данные
Данные могут быть представлены в различных формах, и одной из ключевых классификаций является различие между структурированными и неструктурированными данными, как показано на рисунках 1 и 2.
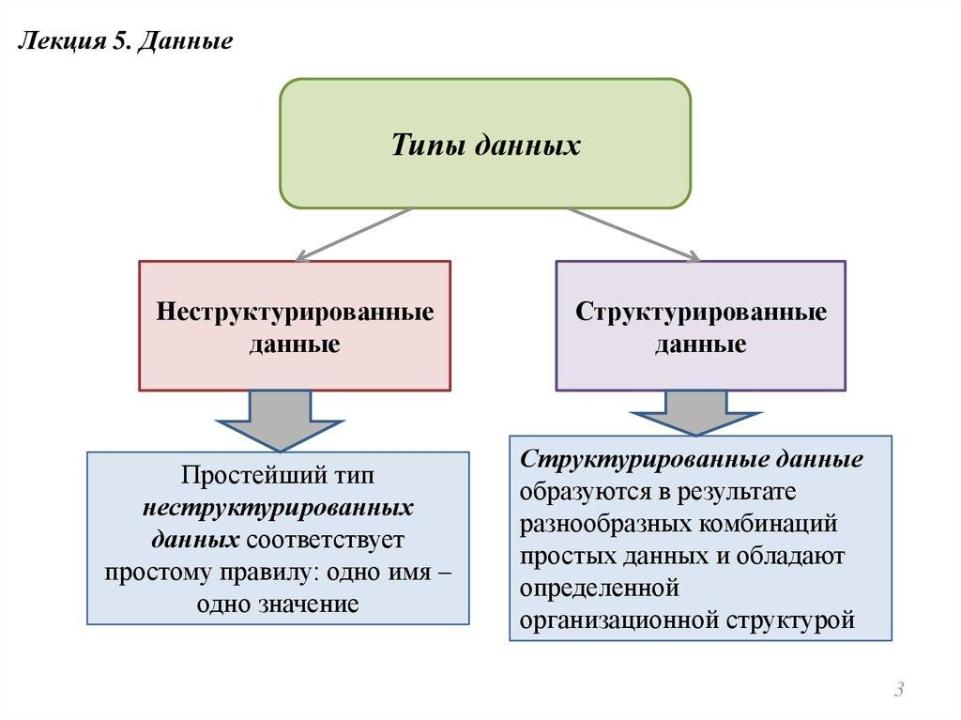
Рисунок 1 — Примеры структурированных и неструктурированных данных

Рисунок 2 — Примеры структурированных и неструктурированных данных
Это разделение не только помогает понять саму природу данных, но и обуславливает способы их обработки, хранения и анализа. Структурированные данные обычно организованы в определённые форматы, что облегчает их обработку и анализ. Наиболее распространённым примером являются табличные данные, где информация разместилась по строкам и столбцам, такие как базы данных SQL. Они легко поддаются синтаксическому анализу и могут быть быстро обработаны с использованием стандартных алгоритмов.
Каждая ячейка в структурированных данных имеет чётко определённый тип, что гарантирует согласованность и предсказуемость. Благодаря этому такой подход позволяет проводить сложные аналитические операции, например, фильтрацию, агрегацию, сортировку и связывание с другими массивами данных. Такие данные легко могут быть интегрированы с аналитическими инструментами и платформами управления данными, что существенно ускоряет процесс принятия решений.
В контрасте с этим, неструктурированные данные не имеют фиксированной структуры. Они могут принимать множество форм, включая текстовые документы, изображения, видео, аудио и даже данные с социальных сетей. Эти данные обладают высоким уровнем сложности, поскольку их анализ требует применения более сложных методов и технологий, таких как обработка естественного языка, машинное обучение и искусственный интеллект. Приведённые примеры неструктурированных данных часто включают в себя огромные объёмы информации, которые ресурсоёмко обрабатывать и анализировать. Тем не менее, именно из неструктурированных данных нередко извлекаются более глубокие инсайты и контекстуальная информация, что делает их крайне ценными.
Перевод неструктурированных данных в структурированный вид порождает дополнительные вызовы. За счёт необходимости выявления и извлечения значимой информации исследователи сталкиваются с задачами распознавания паттернов и анализа контекста. Многие современные алгоритмы, основанные на искусственном интеллекте, служат как вспомогательные инструменты для обработки этих данных. Важным аспектом здесь становится качество извлечённых данных, поскольку точность анализа во многом зависит от способа обработки неструктурированной информации.
Кроме того, стоит учитывать, что несмотря на очевидные различия, граница между структурированными и неструктурированными данными нередко размыта. Например, полуструктурированные данные, такие как XML или JSON, содержат элементы, присущие обоим видам. Эти данные имеют некоторую предустановленную организацию, что облегчает их анализ, но не придерживаются строго фиксированной схемы. Интеграция полуструктурированных данных в более традиционные системные базы данных может представлять значительные трудности, требующие создания адаптивных механизмов обработки.
Фактор времени играет важную роль в различии между структурированными и неструктурированными данными. Со временем данные устаревают, их контекст может меняться, поэтому методы их получения, хранения и анализа также должны быть динамичными. Нужно учитывать, что в рамках одних и тех же процессов, требующих извлечения информации, неструктурированные данные могут значительно изменяться, что затрудняет их использование и согласование с уже существующими базами данных.
Таким образом, между структурированными и неструктурированными данными существует множество нюансов. Каждая категория имеет свои преимущества и недостатки. В то время как структурированные данные позволяют быстро и точно производить количественный анализ, неструктурированные данные обеспечивают более развернутое понимание сложных явлений, требуя применения современных технологий и креативных подходов. Эффективное управление данными требует найти баланс между использованием структурированного подхода к данным и внедрением инновационных методов для работы с неструктурированными массивами информации.
Развитие технологий обработки данных, таких как Big Data и облачные вычисления, открывает новые горизонты для анализа как структурированных, так и неструктурированных данных. На данный момент компании и исследовательские организации активно ищут способы объединения различных типов данных для создания единой экосистемы, где все элементы смогут работать вместе. Подходы к интеграции требуют обеспечения совместимости, что также включает изучение метаданных, так как они могут предоставить информацию о происхождении, контексте использования и значимости данных.
Разнообразие форматов и типов данных вносит вклад в тенденции их использования и накопления на уровне больших объёмов. С развитием интернета и социальных сетей неструктурированные данные приобретают особое значение, становясь источником инсайтов для бизнеса, науки и других областей. В результате, конечная цель в управлении данными заключается в эффективной трансформации информации в знания, что позволит принимать более обоснованные и эффективные решения.