Лаб. 11 ТПП
.docxЛабораторная работа №11
Управление группами процессов и коммуникаторами
Цель: изучить основные принципы управления группами процессов и коммуникаторами в технологии MPI на примере использования в рамках языка С++.
Задание:


#include <iostream>
#include <cstdlib>
#include <ctime>
#include <cstdio>
#include <mpi.h>
#include <cwchar>
// mpiexec -n 2 .\TPP_LAB_7.exe
using namespace std;
#define A 6 // Размер матрицы
void generateMatrix(int matrix[A][A]) {
srand(static_cast<unsigned>(time(nullptr)));
for (int i = 0; i < A; i++) {
for (int j = 0; j < A; j++) {
matrix[i][j] = rand() % 10;
}
}
}
void generateArray(int array[A]) {
srand(static_cast<unsigned>(time(nullptr)) + A);
for (int i = 0; i < A; i++) {
array[i] = rand() % 10;
}
}
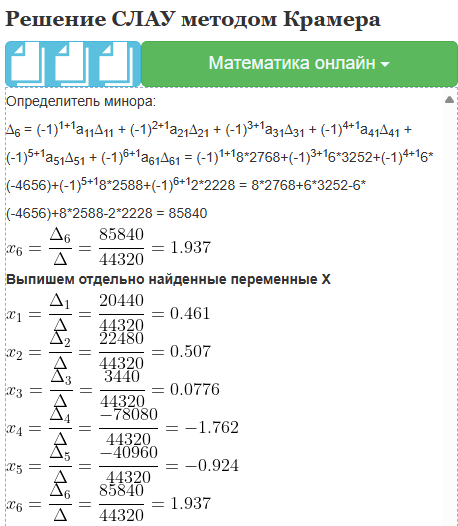
int determinant(int matrix[A][A], int n) {
if (n == 1) {
return matrix[0][0];
}
if (n == 2) {
return matrix[0][0] * matrix[1][1] - matrix[0][1] * matrix[1][0];
}
int det = 0;
int temp[A][A];
for (int p = 0; p < n; p++) {
int h = 0;
for (int i = 1; i < n; i++) {
int k = 0;
for (int j = 0; j < n; j++) {
if (j != p) {
temp[h][k] = matrix[i][j];
k++;
}
}
h++;
}
det += (p % 2 == 0 ? 1 : -1) * matrix[0][p] * determinant(temp, n - 1);
}
return det;
}
void printMatrix(int matrix[A][A]) {
for (int i = 0; i < A; i++) {
for (int j = 0; j < A; j++) {
wprintf(L"%d ", matrix[i][j]);
fflush(stdin);
}
wprintf(L"\n");
fflush(stdin);
}
}
void printArray(const int array[A]) {
for (int i = 0; i < A; i++) {
wprintf(L"%d ", array[i]);
fflush(stdin);
}
wprintf(L"\n");
fflush(stdin);
}
int main(int argc, char* argv[]) {
setlocale(LC_ALL, "ru_RU.UTF-8");
MPI_Init(&argc, &argv);
int rank, size;
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
MPI_Comm_size(MPI_COMM_WORLD, &size);
MPI_Datatype MPI_Matrix;
MPI_Type_contiguous(A * A, MPI_INT, &MPI_Matrix);
MPI_Type_commit(&MPI_Matrix);
int count_of_processes_used = size - 1;
if (count_of_processes_used > A) {
count_of_processes_used = A;
}
int count_of_transmitted_matrix = A / count_of_processes_used;
int remains = A % count_of_processes_used;
MPI_Group world_group;
MPI_Comm_group(MPI_COMM_WORLD, &world_group);
// Массивы для хранения групп и коммуникаторов
MPI_Group* sub_groups = new MPI_Group[count_of_processes_used];
MPI_Comm* group_comm = new MPI_Comm[count_of_processes_used];
// Создание групп и коммуникаторов
for (int i = 0; i < count_of_processes_used; i++) {
int members[] = { 0, i + 1 };
MPI_Group_incl(world_group, 2, members, &sub_groups[i]);
MPI_Comm_create(MPI_COMM_WORLD, sub_groups[i], &group_comm[i]);
}
if (rank == 0) {
int matrix[A][A];
int matrix_2[A][A];
generateMatrix(matrix);
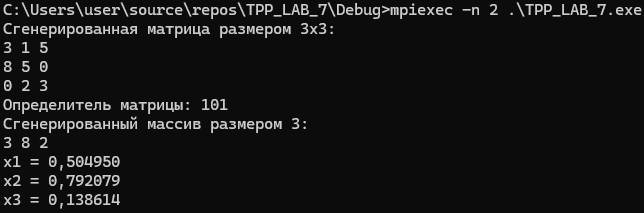
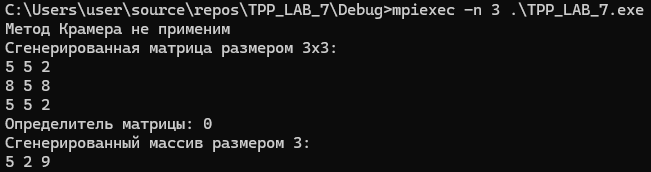
wprintf(L"Сгенерированная матрица размером %dx%d:\n", A, A);
fflush(stdin);
printMatrix(matrix);
int det = determinant(matrix, A);
wprintf(L"Определитель матрицы: %d\n", det);
fflush(stdin);
int array[A];
generateArray(array);
wprintf(L"Сгенерированный массив размером %d:\n", A);
fflush(stdin);
printArray(array);
if (det == 0) {
for (int i = 1; i <= count_of_processes_used; i++) {
MPI_Send(&det, 1, MPI_INT, 1, 1, group_comm[i - 1]);
}
}
else {
int count = 0;
for (int i = 1; i <= count_of_processes_used; i++) {
MPI_Send(&det, 1, MPI_INT, 1, 1, group_comm[i - 1]);
if (i == count_of_processes_used) {
for (int k = 0; k < count_of_transmitted_matrix + remains; k++) {
memcpy(matrix_2, matrix, sizeof(matrix));
for (int j = 0; j < A; j++) {
matrix_2[j][count] = array[j];
}
MPI_Send(matrix_2, 1, MPI_Matrix, 1, 0, group_comm[i - 1]);
count++;
}
}
else {
for (int k = 0; k < count_of_transmitted_matrix; k++) {
memcpy(matrix_2, matrix, sizeof(matrix));
for (int j = 0; j < A; j++) {
matrix_2[j][count] = array[j];
}
MPI_Send(matrix_2, 1, MPI_Matrix, 1, 0, group_comm[i - 1]);
count++;
}
}
}
}
//MPI_Send(matrix, 1, MPI_Matrix, 1, 0, MPI_COMM_WORLD);
}
else if (rank > 0 and rank < count_of_processes_used) {
int det = 0;
MPI_Recv(&det, 1, MPI_INT, 0, 1, group_comm[rank - 1], MPI_STATUS_IGNORE);
if (det == 0) {
//wprintf(L"Метод Крамера не применим\n");
//fflush(stdin);
}
else {
int matrix[A][A];
for (int i = 0; i < count_of_transmitted_matrix; i++) {
MPI_Recv(matrix, 1, MPI_Matrix, 0, 0, group_comm[rank - 1], MPI_STATUS_IGNORE);
//wprintf(L"Полученная матрица рангом: %d:\n", rank);
//fflush(stdin);
//printMatrix(matrix);
// Вычисление определителя
int det_kramer = determinant(matrix, A);
int number = rank + i;
double x = (double)det_kramer / (double)det;
wprintf(L"x%d = %lf\n", number, x);
fflush(stdin);
//wprintf(L"Определитель матрицы: %d\n", det);
//fflush(stdin);
}
}
}
else if (rank == count_of_processes_used) {
int det = 0;
MPI_Recv(&det, 1, MPI_INT, 0, 1, group_comm[rank - 1], MPI_STATUS_IGNORE);
if (det == 0) {
wprintf(L"Метод Крамера не применим\n");
fflush(stdin);
}
else {
int matrix[A][A];
for (int i = 0; i < count_of_transmitted_matrix + remains; i++) {
MPI_Recv(matrix, 1, MPI_Matrix, 0, 0, group_comm[rank - 1], MPI_STATUS_IGNORE);
//wprintf(L"Полученная матрица рангом: %d:\n", rank);
//fflush(stdin);
//printMatrix(matrix);
// Вычисление определителя
int det_kramer = determinant(matrix, A);
int number = rank + i;
double x = (double)det_kramer / (double)det;
wprintf(L"x%d = %lf\n", number, x);
fflush(stdin);
//wprintf(L"Определитель матрицы: %d\n", det);
//fflush(stdin);
}
}
}
for (int i = 0; i < count_of_processes_used; i++) {
if (group_comm[i] != MPI_COMM_NULL) {
MPI_Comm_free(&group_comm[i]);
}
MPI_Group_free(&sub_groups[i]);
}
delete[] group_comm;
delete[] sub_groups;
MPI_Finalize();
return 0;
}