

РАБОТА С ТАБЛИЦАМИ В MS SQL SERVER
Методические указания к выполнению практической работы по курсу «Современные технологии управления базами данных»
для студентов направления 230400.62 очной, заочной и заочно-сокращенной форм обучения
Цель работы: научиться создавать и изменять таблицы в Microsoft SQL Server 2005
ОСНОВНЫЕ ПОНЯТИЯ:
1. Компоненты и инструментальные средства Microsoft SQL Server 2005
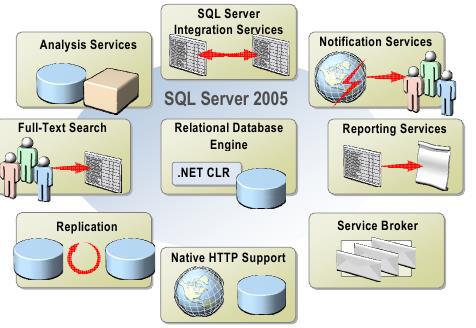
Компоненты SQL Server 2005
Relational Database Engine – это ядро SQL Server, использующее .NET.
Analysis Services – службы для анализа данных, поддерживают OLAP. SQL
Server Integration Services (SSIS) – средства для создания решений импорта
и экспорта данных и выполнения трансформирования данных при передаче.
Notifiations Services – службы оповещения.
Reporting Services – службы для создания и публикации отчетов.
Service Broker – механизм, основанный на очереди, для связывания различных служб приложений.
Native HTTP Support – встроенная поддержка HTTP. Позволяет отвечать на запросы HTTP без IIS.
SQL Server Agent – автоматизирует обслуживание БД и управляет задачами, событиями и оповещениями.
Replication – ряд средств для копирования и распространения данных и объектов БД из одной БД в другую и синхронизации между БД для поддержания соответствия.
Full-Text Search – средство эффективного поиска в БД.
Центральным средством администрирования является SQL Server Management Studio, которое позволяет управлять серверами БД, Analysis
Services и серверами Reporting Services.
2. Общие сведения о среде SQL Server Management Studio
SQL Server Management Studio предоставляет графические интерфейсы для интерактивной разработки и отладки команд языка Transact-SQL, пакетов команд и скриптов, а также набор средств по администрированию баз данных.
SQL Server Management Studio предоставляет следующие средства для разработки команд языка Transact-SQL:
текстовый редактор для ввода команд Transact SQL
цветовую подсветку операторов Transact-SQL для облегчения процесса чтения сложных выражений
представление результатов как в виде таблицы, так и в виде простого текста
графические диаграммы, показывающие логическую последовательность действий, в которую выливается исполнение команды Transact-SQL. Это позволяет программистам определять, какие участки SQL-выражений требуют больших затрат машинных ресурсов, и оптимизировать свой код.
визард для настройки индексов, который позволяет понять, может ли
дополнительное число индексов улучшить производительность системы
SQL Server Management Studio предоставляет интерактивное, графическое средство, которое позволяет администраторам баз данных или разработчикам создавать SQL-запросы, выполнять несколько запросов одновременно,
анализировать результаты запросов и пользоваться средствами, помогающими улучшить производительность системы. В дополнение к этому SQL Server
Management Studio делает предложения по введению дополнительных индексов, способных повлиять на производительность.
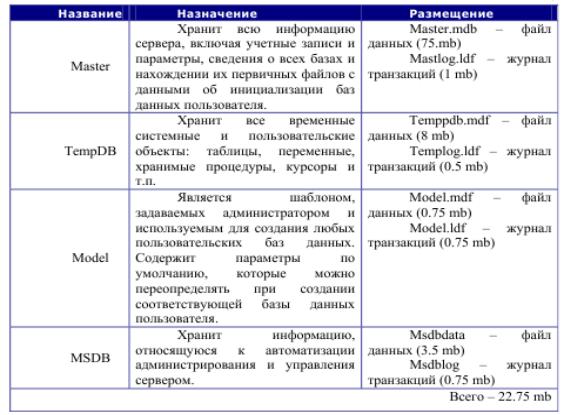
Экземпляр Microsoft SQL Server включает в себя системные базы данных
(master.model, msdb, tempdb), содержащие служебную информацию, назначение которых приведено в табл 1 и пользовательские базы данных.
Табл 1 Системные базы данных
Каждая пользовательская база данных размещается в отдельных файлах – минимум двух: один для самой базы данных – файл данных (mdf-файл), и один для журнала транзакций (ldf-файл). Первый файл данных (mdf-файл) является основным и кроме самих данных содержит системную информацию, второй и все последующие файлы данных являются вторичными (ndf-файлами) и
содержат непосредственно сами данные. Расположение этих файлов можно указать при создании базы данных.
Все системные и пользовательские базы данных содержат в обязательном порядке 18 системных таблиц, которые хранят информацию,
определяющие структуру и организацию соответствующей базы данных.
Основной единицей хранения данных является страница. SQL Server
выполняет чтение и запись данных постранично. Вся база данных логически подразделена на страницы, нумеруемые начиная с 0. Размер страницы составляет 8 Кбайт (128 страниц на один мегабайт).
Объекты базы данных Логически данные в базе данных хранятся в виде объектов базы данных.
Объекты данных хранятся в схеме базы данных. SQL Server предоставляет следующие объекты данных:
таблицы;
представления;
синонимы;
индексы;
хранимые процедуры;
триггеры;
пользовательские типы данных;
функции пользователя;
ключи, обеспечивающие ссылочную целостность;
ограничения целостности;
умолчания
правила (используются для обратной совместимости)
Кобъектам базы данных также относятся схемы, пользователи и роли.
ВSQL Server 2005введены новые объекты, используемые Service Broker:
типы сообщений (структура сообщения, отправляемого от одного сервиса другому),
контракты (соглашения между двумя сервисами),
очереди (сообщения, направленные сервису),
сервисы (наборы задач, где каждая задача представляется
контрактом), сервисные программы.
3. Запуск SQL Server Management Studio
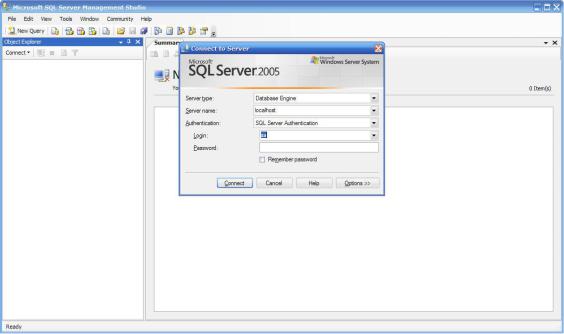
Для запуска прикладного окна Запуск SQL Server Management Studio в
среде Windows нужно выбрать: Пуск > Программы > Microsoft SQL Server >
SQL Server Management Studio.
На экране открывается фрейм приложения SQL Server Management Studio с
формой подключения к серверу баз данных, показанный на рис.1.
Рис.1. Начальное окно SQL Server Management Studio
Для продолжения работы следует ввести в поле Server name имя сервера баз данных, с которым осуществляется соединения: SQL2005, выбрать тип аутентификации Windows Authentication и нажать кнопку соединить
После этого появится рабочее окно SQL Server Management Studio ,
показанное на рис.2.
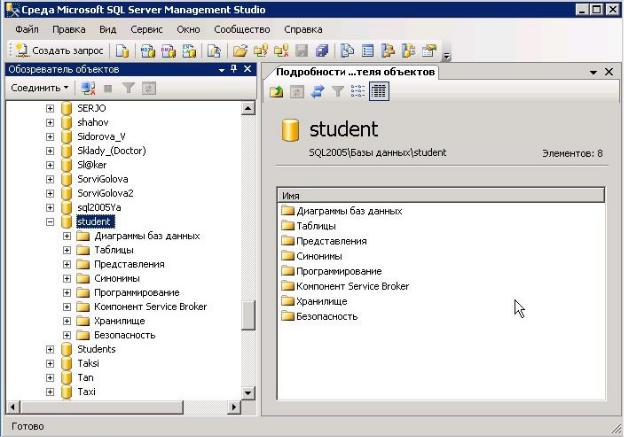
Рис.2. Окно SQL Server Management Studio после подключения к серверу баз данных
В левой части окна расположен обозреватель объектов - древовидный навигатор по ресурсам сервера баз данных, с помощью которого можно просматривать состав объектов (таблицы, хранимые процедуры, индексы) баз данных сервера.
Изменение таблиц
Большинство параметров, которые были указаны при первоначальном создании таблицы, можно изменить. Можно выполнить следующие действия:
Можно добавить, изменить или удалить столбцы. У столбца можно изменить имя, длину, тип данных, точность, масштаб и возможность принимать значения NULL, хотя существуют некоторые ограничения.
можно добавить или удалить ограничения PRIMARY KEY, FOREIGN
KEY, UNIQUE и CHECK, определение DEFAULT.
Ограничения
1) NOT NULL - данный ограничитель не позволяет принимать значения
NULL.
NOT NULL данный ограничитель гарантирует, что всегда будет какое либо значение. Это означает, что вы не можете вставить новую запись или изменить запись без добавления значения к этой области.
Null-значение(null value) – это неизвестное значение, для которого применяется обозначение NULL. Null-значение в колонке обычно означает, что для данной строки этой колонки нет данных, потому что значение неизвестно, либо не имеет смысла, либо не задано или будет задано в будущем. Null-значения – это не пустые значения и не значения числа 0, их настоящие значения неизвестны
(unknown), поэтому никакие два null-значения не являются равными.
2) Свойство IDENTITY задает одну из колонок как идентифицирующую колонку (identity column), добавив к определению колонки. Если колонка создается со свойством IDENTITY, то SQL Server
автоматически генерирует для этой колонки значение строки, рассчитываемое по начальному значению (seed value) и значению приращения (increment value). Начальное значение (seed) является значением идентификации для первой строки, вставленной в таблицу. Приращение (increment) – это величина, на которую SQL Server увеличивает значение идентификации для последовательно вводимых строк. Каждый раз при вводе строки SQL Server
присваивает текущее значение идентификации элементу данных в колонке идентификации, вводимому в новую строку. Следующая введенная строка получит значение идентификации, большее, чем текущее максимальное значение идентификации на величину приращения. Таким образом, каждая вводимая строка получит уникальное значение идентификации. Свойство идентификации полезно для создания колонок, в которых каждая строка должна иметь уникальный идентификатор, например, для колонки Product_ID.
Если вы разрешите SQL Server генерировать идентифицирующие значения для вводимых строк, то это окажется проще, чем следить за правильностью ввода последовательных значений. Идентифицирующие колонки обычно
применяются в ограничениях первичного ключа в таблицах, благодаря которым возможна уникальная идентификация строк.
Например, если вы зададите IDENTITY(0, 10), то значение идентифицирующей колонки для первой введенной строки будет равно 0, для второй строки будет равно 10, для третьей строки – 20, и т.д. Если начальное значение или приращение не задать, то для них будут применяться значения по умолчанию, равные 1 и 1. Вы можете задать как оба этих параметра, так и один из них. Идентифицирующие колонки не могут содержать значения по умолчанию и для них не разрешено применение null-значений. В каждой из таблиц может иметься только одна идентифицирующая колонка.
По умолчанию, непосредственный ввод данных в идентифицирующие колонки невозможен и они не могут быть изменены. Если вы хотите повторить ввод удаленной строки и хотите сохранить старое идентифицирующее значение этой строки, то вы можете преодолеть стандартные настройки, применив такой оператор:
SET IDENTITY_INSERT имя_таблицы ON
При помощи этого оператора можно вставить строку и назначить нужное вам значение идентифицирующей колонки. Закончив ввод строки, нужно отменить возможность вставки в идентифицирующую колонку при помощи такого оператора:
SET IDENTITY_INSERT имя_таблицы OFF
После этого, SQL Server, в качестве начального значения, применяемого при добавлении следующих строк, возьмет самое большое значение из данной колонки.
3)Свойство UNIQUE – уникальность, столбец не может содержать повторяющихся значений.
4)Ограничение PRIMARY KEY – первичный ключ. Столбцы ограничения
PRIMARY KEY, указанного при создании таблицы, неявно преобразуются в
NOT NULL. В них также не должно быть повторяющихся значений. У таблицы
может быть только одно ограничение PRIMARY KEY.
5)Ограничение FOREIGN KEY – внешний ключ. Необходимо для установления связи между таблицами. Таблица может содержать несколько ограничений FOREIGN KEY.
6)Ограничение CHECK – служит для проверки введенного условия. Оно позволяет задать для определённой колонки выражение, которое будет осуществлять проверку, помещаемого в эту колонку значения. Если значение удовлетворяет, заданному ограничению, то выражение должно возвращать Логическое значение (истина). Например, если требуется, чтобы в колонке были только положительные цены товаров, вы можете использовать:
CHECK (price > 0)
Ограничение check состоит из ключевого слова CHECK, за которым следует выражение в круглых скобках. Выражение в ограничении check должно использовать ту колонку, на которую оно накладывается, в противном случае это ограничение не будет иметь смысла.
7) DEFAULT – позволяет задать значение по умолчанию. Если при создании новой строки в таблице, значения для некоторых колонок не будут указаны, то эти колонки могут быть заполнены заданными для них значениями по умолчанию.
Изменяет определение таблицы путем изменения, добавления или удаления столбцов и ограничений команда ALTER TABLE.
1)Добавление столбцов в таблицу:
ALTER TABLE <имя таблицы> ADD <имя столбца> <тип данных>
2)Изменение типа данных
ALTER TABLE <имя таблицы> ALTER COLUMN <имя столбца> <новый тип данных>
3)Удаление столбца ALTER TABLE <имя таблицы> DROP COLUMN <имя столбца>
4)Добавление ограничений